







qidian_analysis
目的
本次的数据分析项目实现了数据爬取、解析、储存、分析和可视化等需求。本项目整体使用了Python语言,爬取的目标是起点中文网,目的是获得其畅销榜单的前100部小说的相关信息(排行,书名,作者,书籍类型,简介,最新章节,最近更新时间和书籍链接),并在网页上进行相应的分析和可视化展示。
介绍
-
spider_qidian:将目标网站的数据进行爬取、清洗,然后保存在excel和数据库中
-
flask_qidian:web可视化展示
-
本次项目实现的大致功能:
-
网页爬取:采用Python中的urlib库连接并且爬取了起点中文网畅销榜单,获得了需要的内容。
-
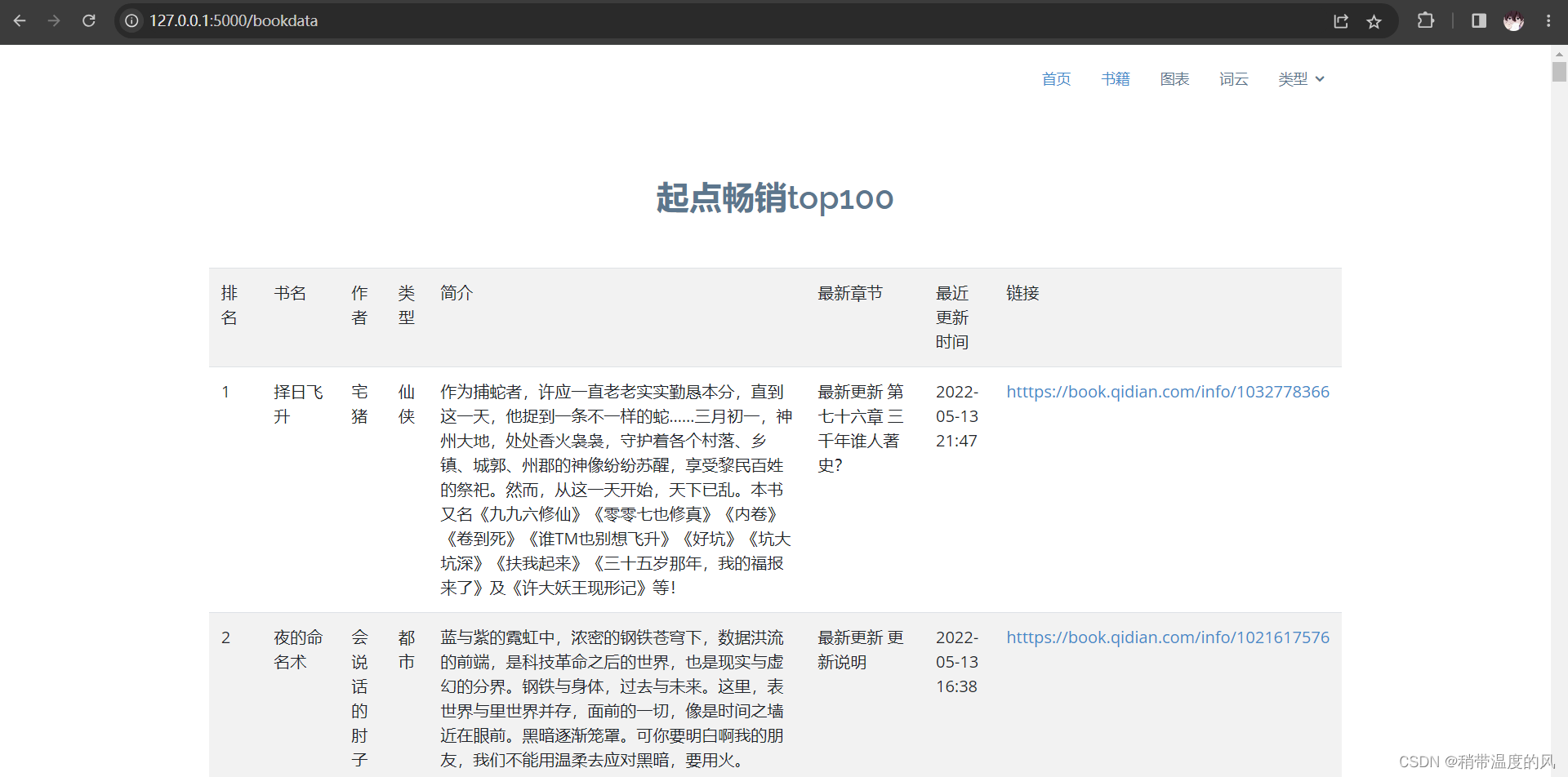
数据解析:利用了BeautifulSoup和正则式对获取的网页内容进行了解析,拿到我们需要的信息(排行,书名,作者,书籍类型,简介,最新章节,最近更新时间和书籍链接)。
-
数据存储:将拿到的数据保存在了Excel文件中同时也利用sqlite3库将相关的数据保存在了数据库中,以便于之后数据的利用。
-
数据分析:利用flask框架构造了一个本地的网站,再次利用sqlite3操作数据库进行数据分析并且在网页上进行了展示。
-
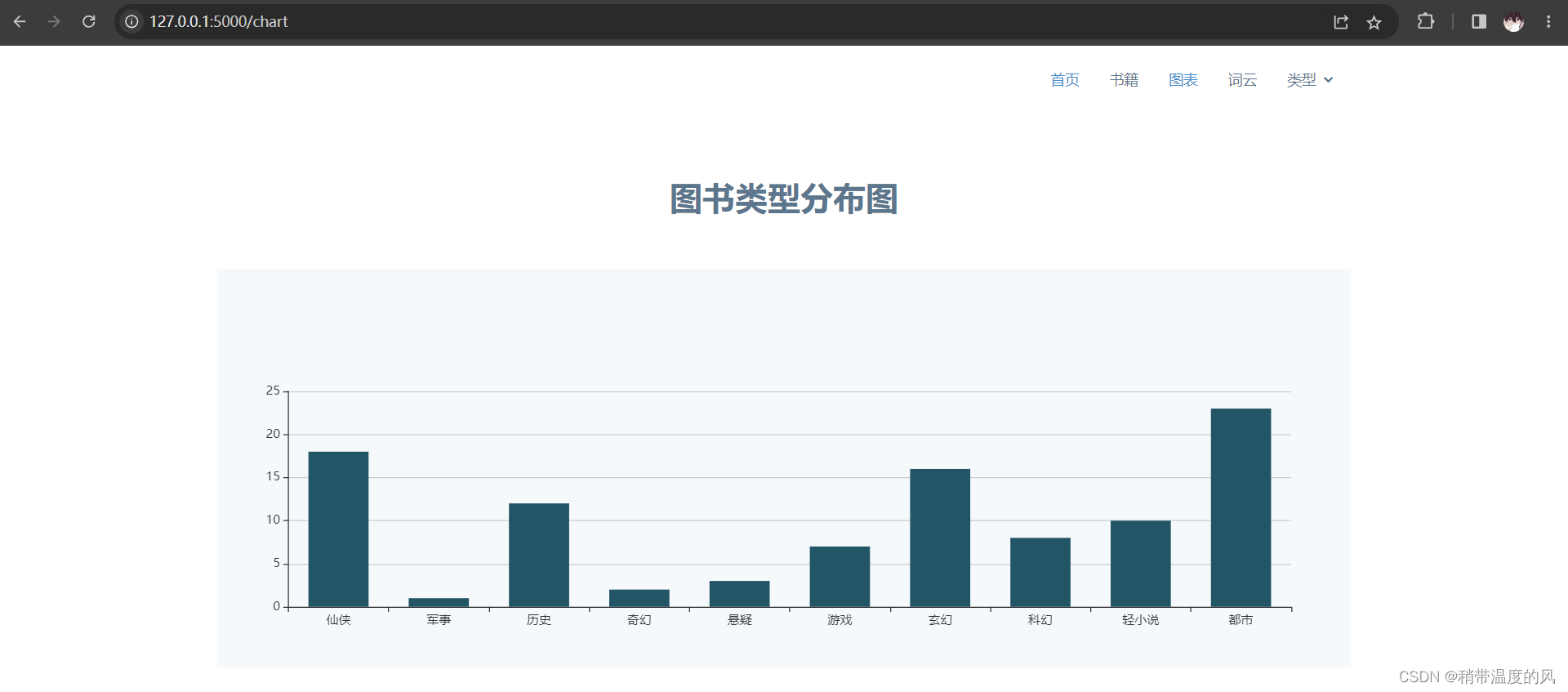
数据可视化:通过echarts对书籍类型分布情况绘制了柱状图,然后又用wordcloud完成了对书籍简介词频分析和图像的制作,同时进行了展示。
-
环境
python3.9 + BeautifulSoup4 +flask + 各种库
搭建/运行
- 数据爬取(指定起止页1~30)
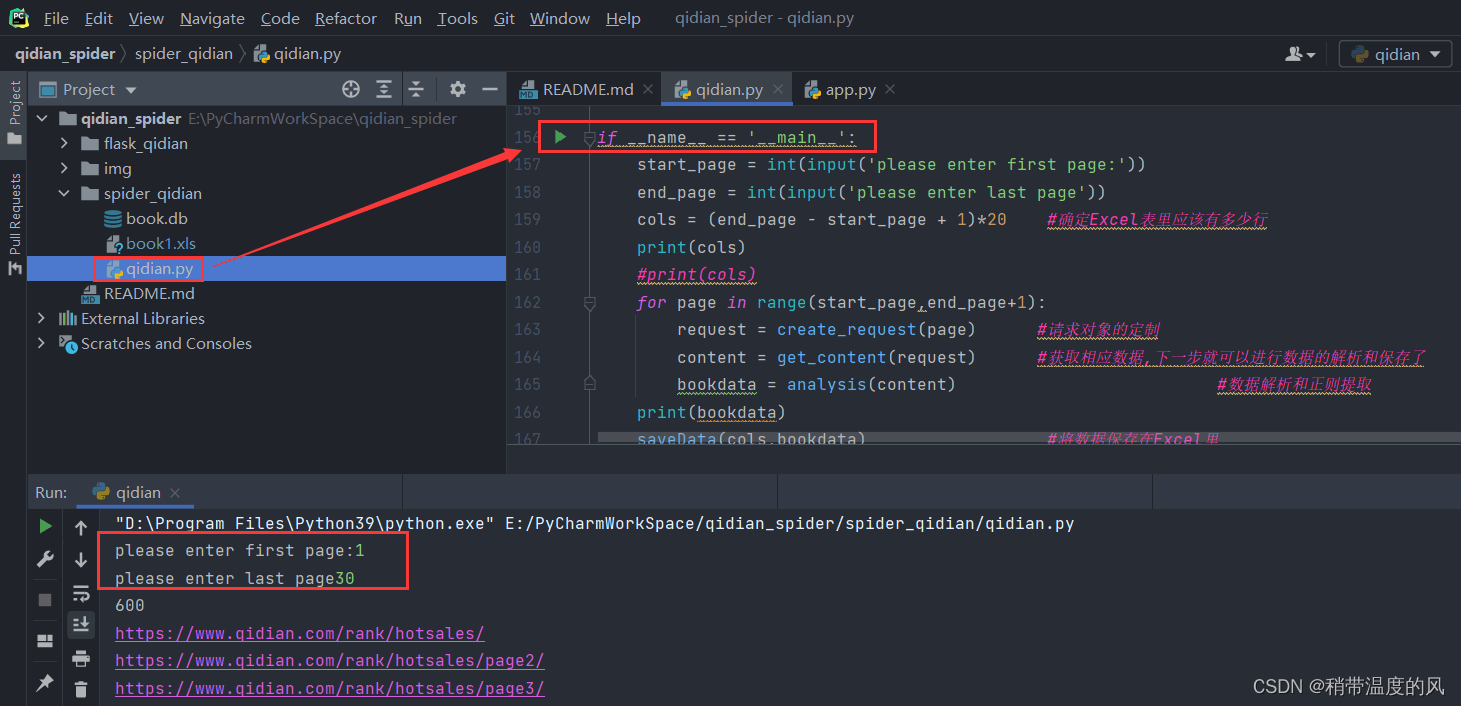
- 可视化展示(运行app.py后访问终端显示的链接)
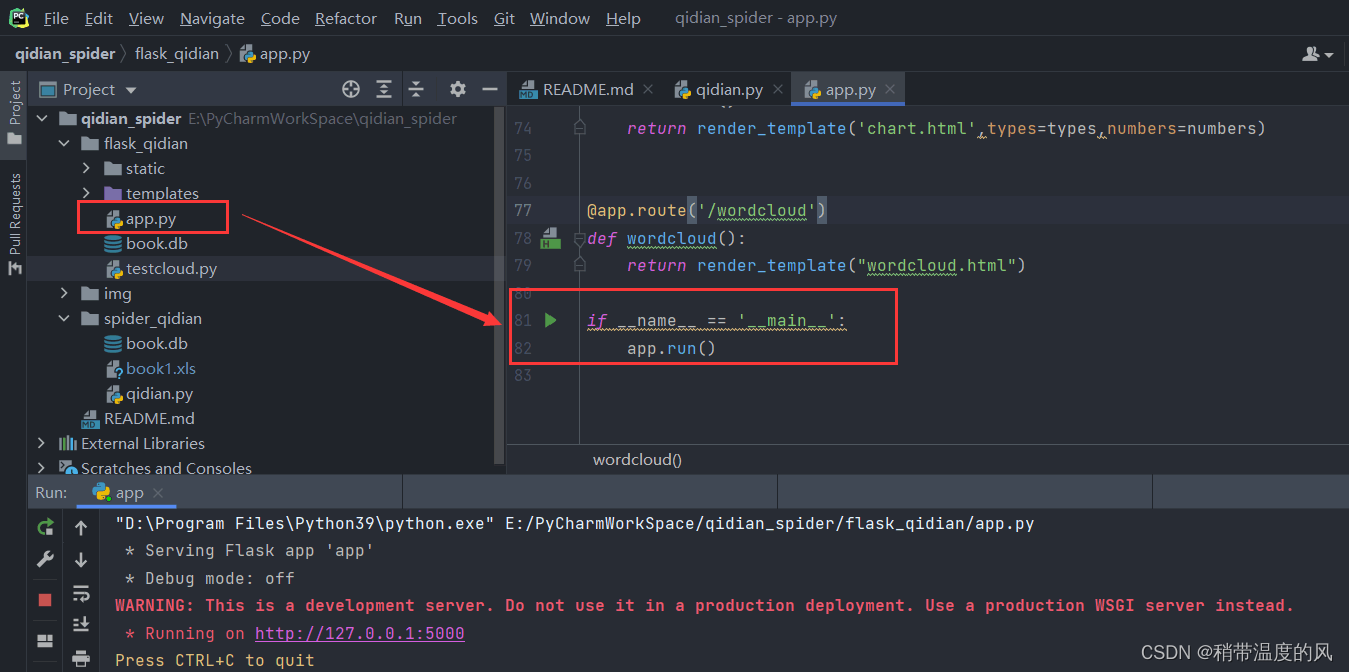
效果图
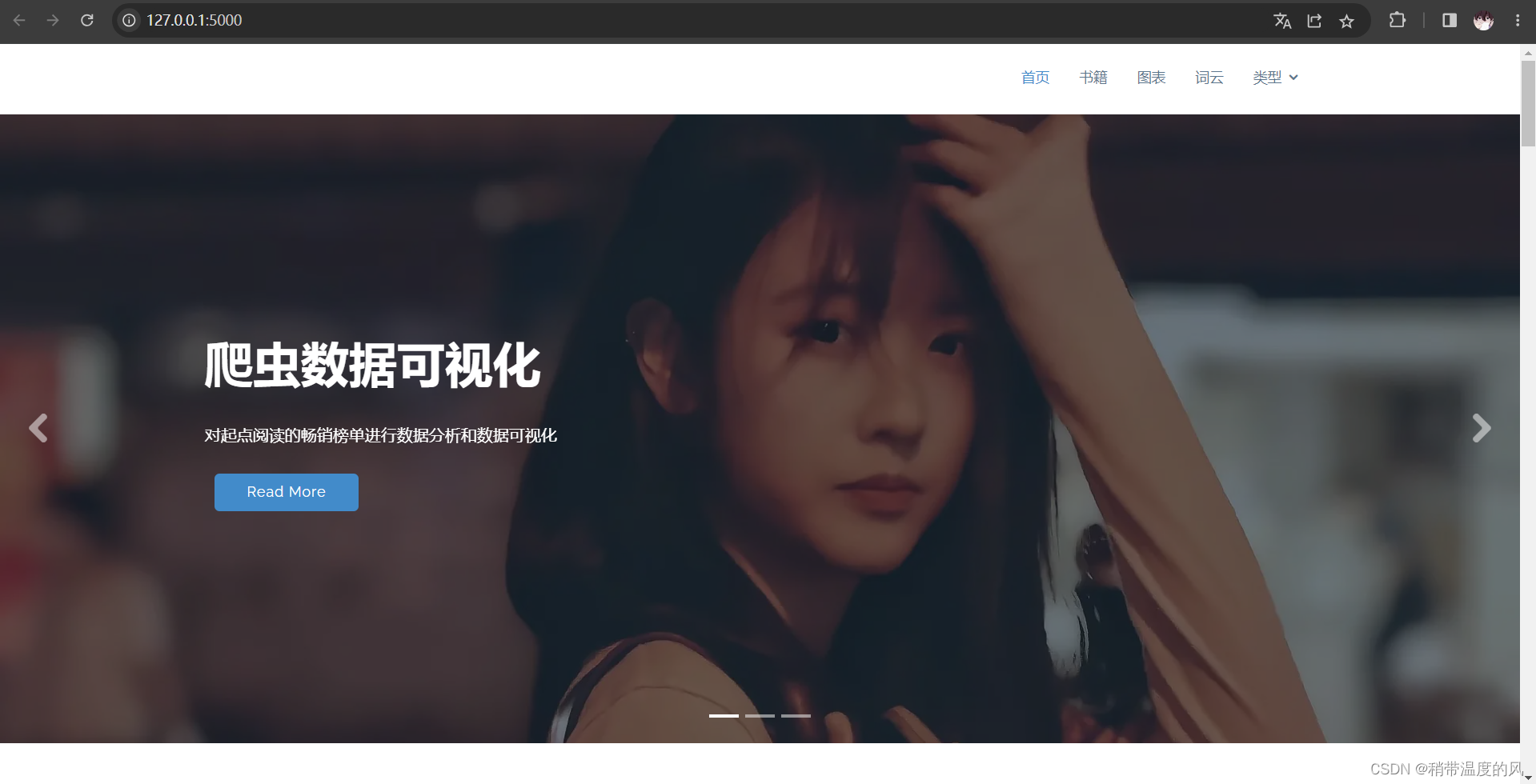
- 首页(轮播图)
- 书籍(畅销榜)
- 柱状图(类型分布)
- 词云
- 图书类型再分类分析
- 可视化大屏
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tg2ZIwbo-1688808431047)(https://github.com/Mingdaj/qidian-analysis/assets/130920375/5c9116e8-8d77-49d3-b895-0b925c47d640)]](https://i-blog.csdnimg.cn/blog_migrate/fe79e7aa39fdb4fde2c46e2d41c32d23.png)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









