







学习笔记
机器学习贝叶斯模型原理及手写代码 + Lintcode 刷题 627最长回文串
一、正态分布
1.连续数据&离散数据的特点
"""
离散数据
"""
ls = [1, 2, 3, 4, 3, 2, 1, 2, 3, 6, 4, 2, 1]
P_1 = ls.count(1) / len(ls)
"""
连续数据
"""
ls = [1, 2, 3, 4, 3, 2, 1, 2, 3, 6, 4, 2, 1]
P_1 = ?
Q:上面一模一样的连续数据&离散数据的特点是什么?有什么区别?
A:数据科学中,我们使用有限的数据代表客观世界,连续数据&离散数据用肉眼看上去是一样的,但实际背后的意义(规律)不一样
-
离散数据 —> 数据是可列个(N) —> 用频率代表概率
-
连续数据 —> 数据是无限个 —> 计算时分母为无穷大 —> 单点概率为0 —> 只能求区域概率
2.高斯(正态)分布理解
正态分布公式
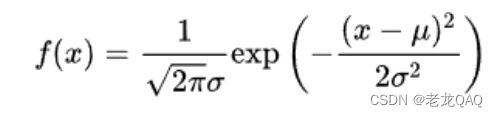
f(x)代表导函数-概率密度函数
F(x)代表原函数
delta - 标准差
exp - e的多少次方
u - 均值
正态分布python实现
import numpy as np
from matplotlib import pyplot as plt
def normal(x, mu, delta):
"""
正态分布的概率密度函数
- x:变量取值
- mu:均值(mean)
- delata:标准差
"""
return 1 / np.sqrt(2 * np.pi) / delta * np.exp(- (x - mu) ** 2 / 2 / delta ** 2)
#从(-5,5)取100个数
x = np.linspace(start=-5, stop=5, num=100)
# 画出正态分布图像
# mu = 数据平均值(对称轴) delta= 数据分布 总面积为1
plt.plot(x, normal(x=x, mu=0, delta=1))
正态分布图像
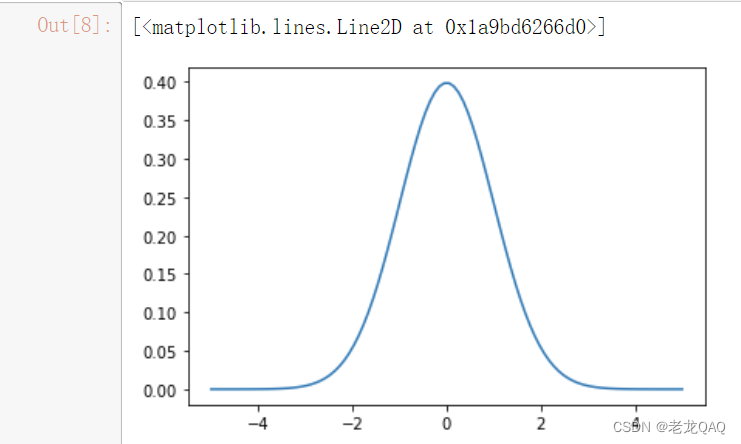
X轴代表连续型变量的取值
Y轴代表PDF(概率密度函数 Probability density function) --> 本质为概率的导数 —> 积分可以获得区域概率
- 注意:数学上高斯分布中连续型变量求单点概率无法计算(上下限相同的定积分为0)
3.工程近似
思考:工程中有大量离散数据,离散数据就无法使用正态分布了吗?
工程近似思想:离散数据假定为连续数据使用正态分布求解
# 创建离散数据ls
ls = [1, 2, 3, 4, 3, 2, 1, 2, 3, 6, 4, 2, 1]
arr = np.array(ls)
# op:array([1, 2, 3, 4, 3, 2, 1, 2, 3, 6, 4, 2, 1])
mu = arr.mean()
# op:2.6153846153846154
delta = arr.std()
# op:1.3888823142513684
plt.plot(x, normal(x, mu=mu, delta=delta))
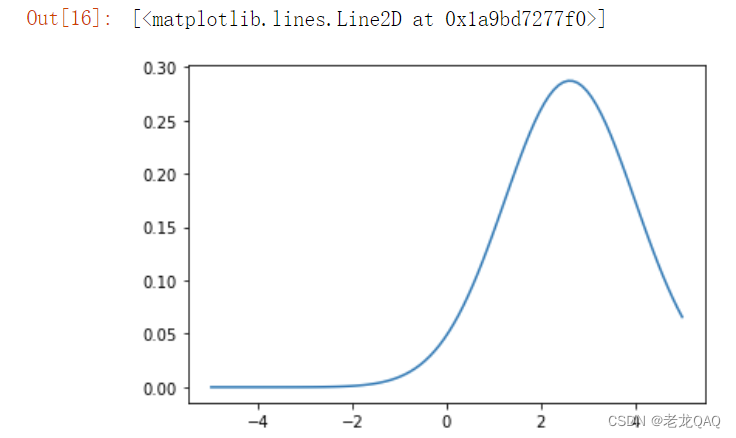
比较离散数据使用正态分布准确度
# 计算1的概率
P_1 = normal(x=1, mu=mu, delta=delta)
# op:0.14604824969233512
# 可以求任意数的值(概率)
normal(x=3.5, mu=mu, delta=delta)
print(p1, p2, p3, p4)
# op:0.23076923076923078 0.3076923076923077 0.23076923076923078 0.15384615384615385
print(normal(x=1, mu=mu, delta=delta), normal(x=2, mu=mu, delta=delta),
normal(x=3, mu=mu, delta=delta), normal(x=4, mu=mu, delta=delta))
# op:0.14604824969233512 0.2603841142666653 0.27643448647307345 0.17475498326027847
工程近似概念理解
在数学上正态分布中单点数据不是概率 —> 但是工程中可以类比概率 —> 这一点的概率正比于这个点的pdf(pdf相当于长方形的高,给每个数据都乘一个相同的很小的值就是这个点的概率,而这个给很小的值在模型预测中对结果影响极小) —> 人工智能计算中单个数值不重要,重要的是数值间的关系
模型的前提假设 —> 实际工程上做工程近似 —> 假设是正态分布
- Q:为什么要假设为正态分布
- A:虽然不知道该数据集是什么分布,但是因为客观世界中正态分布最多最广,所以我认为就是正态分布 - 最大似然估计
如果模型结果和正态分布差的不多 —> 得到很好的效果
如果模型结果和正态分布差的多 —> 前提假设有问题 —> 预测效果不好 —> 重新选择
工程近似总结
在人工智能领域中:
- 从纯数学的角度,所有模型都是错的
- 从工程角度,大部分模型都是有效的 —> 工程上衡量模型预测的收益和损失 —> 例如:速度性能准确度等,模型最终目标是收益远大于损失
客观世界满足不了计算条件,所以人为引入误差(如假定为正态分布)来构建模型,算法工程师就是来减小误差/衡量模型预测的收益和损失 —> 最大似然估计
最大似然估计
通俗理解为:既然事情已经发生了,为什么不让这个出现的结果的可能性最大呢?
二、高斯贝叶斯
1.运行sklearn中的高斯贝叶斯
from sklearn.naive_bayes import GaussianNB #高斯贝叶斯
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X = data["data"]
y = data["target"]
X_train, X_test, y_train ,y_test = train_test_split(X, y, test_size=0.15, random_state=1)
# 构建模型
gbn = GaussianNB()
# 训练模型
gbn.fit(X=X_train, y=y_train)
gbn.score(X=X_test, y=y_test)
# op:0.9418604651162791
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X=X_train, y=y_train)
knn.score(X=X_test, y=y_test)
# op:0.9418604651162791
2.手写高斯贝叶斯
class MyGaussianNB(object):
"""
自定义高斯贝叶斯
"""
def __init__(self):
"""
接收超参
"""
pass
def fit(self, X, y):
"""
模型的训练
- 提前把后续推理需要用到的一些参数计算好
- 每个类别的先验概率
- 每个特征的均值和标准差
"""
# 转 NumPy 数组
X = np.array(X)
y = np.array(y)
# 计算参数
self.y_probs = {} # 每一类的概率
self.x_params = {} # 每个类的
for class_idx in set(y): # 把每个标号取出来
# 计算每个类别的先验概率 P(yi)
self.y_probs[class_idx] = (y==class_idx).mean() # y==class_idx 相同则是True 反之亦然 ,然后求mean() 就是概率(准确率)
# 计算条件参数
mu = X[y==class_idx].mean(axis=0) # 筛选数列 -- X[y==class_idx] 就是切分数据集 P(xi|y1)
delta = X[y==class_idx].std(axis=0) + 1e-6 # 竖着求 axis=0
self.x_params[class_idx] = {"mu":mu, "delta":delta}
def predict(self, X):
"""
模型的预测
"""
# 转NumPy类型
X = np.array(X)
# 多样本校验
if X.ndim != 2:
raise Exception("默认是批量预测 ....")
# 等待接收结果
results = []
# 每个样本单独计算
for x in X:
labels = []
for label_idx in self.y_probs: # self.y_probs每个类的先验概率
prob = self.y_probs[label_idx]
for feature_idx in range(len(x)): # 有几个特征就有几个条件概率
prob *= self._gaussian_distribution(x=x[feature_idx],
mu=self.x_params[label_idx]["mu"][feature_idx],
delta = self.x_params[label_idx]["delta"][feature_idx])
labels.append(prob)
results.append(labels)
return np.array(results).argmax(axis=1)
def score(self, X, y):
"""
模型的评估
"""
y_pred = self.predict(X=X)
return (y_pred == y).mean()
# pass
def _gaussian_distribution(self, x, mu, delta):
"""
高斯概率密度函数
"""
return 1 / np.sqrt(2 * np.pi) / delta * np.exp(- (x - mu) ** 2 / 2 / delta ** 2)
# 定义模型
my_gnb = MyGaussianNB()
# 训练模型
my_gnb.fit(X=X_train, y=y_train)
# 模型评估
my_gnb.score(X=X_test, y=y_test)
# op:0.9418604651162791
工程中如果出现连续+离散变量该怎么办 —> 实际上都当作连续型处理 —> 更底层的:或许不存在真正的离散型数据,都是连续的
numpy练习
# 构建4x6矩阵
w =np.arange(24).reshape(4,6)
"""
op: array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
"""
# 构建标签
k = np.array([1,0,1,1])
# op:array([1, 0, 1, 1])
# 求列均值
w.mean(axis=0) # 0就是竖着求 1就是横着求
# op:array([ 9., 10., 11., 12., 13., 14.])
# 抓取第0类样本
w[k==0]
# op:array([[ 6, 7, 8, 9, 10, 11]])
# 抓取第1类样本
w[k==1]
"""
op:
array([[ 0, 1, 2, 3, 4, 5],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
"""
# 返回每列最大值的索引
w.argmax(axis=1)
# op:array([5, 5, 5, 5], dtype=int64)















 6839
6839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









