






CUDA线程模型
下面我们介绍CUDA的线程组织结构。首先我们都知道,线程是程序执行的最基本单元,CUDA的并行计算就是通过成千上万个线程的并行执行来实现的。下面的机构图说明了GPU的不同层次的结构。
CUDA的线程模型从小往大来总结就是:
- Thread:线程,并行的基本单位
- Block:线程块,互相合作的线程组,共享shared memory:
- Grid:一组线程块,共享global memory
- Kernel:在GPU上执行的核心程序,这个kernel函数是运行在某个Grid上的。
One kernel <-> One Grid
一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。每一个block和每个thread都有自己的ID,我们通过相应的索引找到相应的线程和线程块。
blockIdx:
含义:
blockIdx是一个内建的 三维变量,用来标识当前线程块 (block) 在整个网格 (grid) 中的位置。网格由多个线程块组成,每个线程块是一个由多个线程组成的矩形或立方体。维度:
blockIdx可以有三个分量:blockIdx.x,blockIdx.y,blockIdx.z,分别表示线程块在 x、y、z 方向上的索引。blockDim:
- 含义:
blockDim是一个内建的 三维变量,用于表示每个线程块中线程的维度,也就是一个线程块中每个维度包含多少个线程。- 维度:
blockDim.x,blockDim.y,blockDim.z,分别表示线程块在 x、y、z 方向上的线程数量。
例:二维图像中像素处理,当前thread处理的像素行坐标和纵坐标由此得到(此处block为2维,thread为二维)

这里想谈谈SP和SM(流处理器),很多人会被这两个专业名词搞得晕头转向。
- SP:最基本的处理单元streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。
- SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。
需要指出,每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X是48个,Kepler架构都是192个,Maxwell都是128个,V100是64个。
简而言之,SP是线程执行的硬件单位,SM中包含多个SP,一个GPU可以有多个SM(比如16个),最终一个GPU可能包含有上千个SP。这么多核心“同时运行”,速度可想而知,这个引号只是想表明实际上,软件逻辑上是所有SP是并行的,但是物理上并不是所有SP都能同时执行计算(比如我们只有8个SM却有1024个线程块需要调度处理),因为有些会处于挂起,就绪等其他状态,这有关GPU的线程调度。
下面这个图将从硬件角度和软件角度解释CUDA的线程模型。
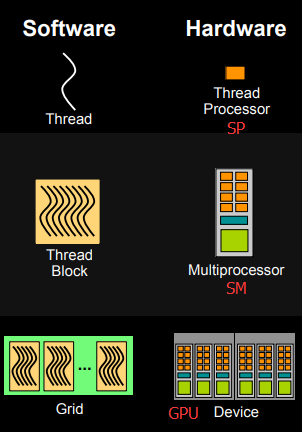
- 每个线程由每个线程处理器(SP/CUDA核)执行。一个SP也可能执行多个thread(一般情况下是并发执行,不能并行)
- 线程块由多核处理器(SM)执行(block不能跨SM,每个 SM,它会将 block 内的线程划分成若干个 warp,每个 warp 内 32 个线程同步执行,warp 调度器会尽量将 warp 中的线程同时执行,但如果有线程发散,性能会下降。如果一个 SM 资源足够,可以同时容纳多个 block,并通过调度器安排 warp 的执行。
- 一个kernel其实由一个grid来执行,一个kernel一次只能在一个GPU上执行
block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行(逻辑上同时执行多个block,实际只执行一个)。
1.CUDA 的 grid-block-thread 结构和 SM-Warp-thread 结构
CUDA 的 grid-block-thread 结构和 SM-Warp-thread 结构是从两个不同的抽象层次来描述 GPU 计算的。理解这两种结构有助于明确不同层面上的计算调度和执行机制。下面详细说明这两个结构及它们各自所面向的对象。
1. Grid-Block-Thread 结构
- Grid 是线程块的集合,表示整个并行计算的范围。
- Block 是线程的集合,表示执行单元中的一小块工作,线程块可以相互独立执行。
- Thread 是最小的执行单元,每个线程执行相同的 kernel 代码,处理自己的数据。
面向问题:
Grid-Block-Thread 结构主要用于编程时组织线程、划分工作负载。在设计并行算法时,程序员需要考虑如何将计算任务划分成合理的网格和线程块,并通过<<<grid, block>>>来启动并行执行。这种抽象模型让开发者能够以较高的层次来思考问题的并行性,而不需要直接关注 GPU 硬件的细节。
优点:
- 易于编写高并行度的代码。
- 灵活的多维度配置:Grid 和 Block 都可以是 1D、2D、3D 的结构,适合不同维度的并行计算问题。
- 能够方便地将复杂问题分解为小的线程工作单元(thread),并在 grid 和 block 之间进行映射。
2. SM-Warp-Thread 结构
- 面向硬件执行层面,即实际硬件(Streaming Multiprocessor, SM)如何管理和执行并行线程。
- SM(Streaming Multiprocessor) 是 GPU 执行任务的基本单元,每个 SM 负责调度和执行多个线程块(block)。
- Warp 是 SM 内的执行单元,一个 warp 通常包含 32 个线程,这些线程会同步执行相同的指令集。
- Thread 依然是最小的执行单元,但在硬件级别,它们以 warp 的形式被调度和执行。
面向问题:
SM-Warp-Thread 结构 主要描述了 GPU 内部的实际硬件执行机制。硬件调度器按照 warp 为单位调度线程的执行,并通过 SM 来分配共享的硬件资源(寄存器、共享内存等)。这使得每个 warp 内的 32 个线程同步执行,并尽量减少控制流发散(warp divergence)带来的性能损失。
优点:
- 硬件的高度并行性得以体现。每个 SM 可以同时执行多个 warp,从而极大地提升了并行度。
- Warp 是 GPU 线程执行的基础,保证了硬件调度的效率和线程管理的简单性。
二者关系和各自面向的对象:
- Grid-Block-Thread 是编程模型上的抽象,它让程序员方便地组织并行任务、划分工作,并通过这种结构来启动并行计算。
- SM-Warp-Thread 是硬件上的实现,描述了实际的计算资源是如何被分配和调度的。每个 block 被分配到一个或多个 SM 上执行,而每个 SM 又通过 warp 来管理并调度线程的执行。
结合实例理解:
-
编程模型(Grid-Block-Thread):
- 你设计了一个应用,它需要处理一个 1000x1000 的数据矩阵,于是你使用一个
grid(10, 10),每个block(100, 100),共 100 个 block,每个 block 内有 100x100 = 10,000 个线程。 - 每个线程独立处理一小块数据。
- 你设计了一个应用,它需要处理一个 1000x1000 的数据矩阵,于是你使用一个
-
硬件执行模型(SM-Warp-Thread):
- 当你启动 kernel 时,硬件会将每个 block 分配给不同的 SM 来执行。
- 具体到每个 SM,它会将 block 内的线程划分成若干个 warp,每个 warp 内 32 个线程同步执行,warp 调度器会尽量将 warp 中的线程同时执行,但如果有线程发散,性能会下降。
- 如果一个 SM 资源足够,可以同时容纳多个 block,并通过调度器安排 warp 的执行。
总结:
- Grid-Block-Thread 面向的是开发者在编写 CUDA 程序时的逻辑组织,专注于将任务划分为合适的并行结构。
- SM-Warp-Thread 是 GPU 硬件的执行机制,专注于实际的硬件如何管理、调度和执行这些并行任务。
2. 一个 block 可以跨多个 SM 运行吗?
不可以,一个 block 只能由一个 SM 完整执行,不能跨多个 SM。CUDA 的设计是让每个线程块(block)作为一个执行单元,由某一个 SM 完全管理和执行。
-
原因:block 需要在同一个 SM 内共享资源,比如寄存器(registers)、共享内存(shared memory)等。如果一个 block 跨多个 SM 执行,资源共享和同步机制会变得非常复杂。因此,block 必须在同一个 SM 内执行,直到所有线程都完成。
-
当一个 block 执行完毕后,调度器可以将另一个 block 分配给这个 SM 执行。这也是为什么选择合理的 block 大小非常重要,确保每个 block 能有效利用 SM 的资源。
3. 一个 SM 内只能有一个 warp 在运行吗?
不,一个 SM 内可以同时运行多个 warp。
-
多Warp 并行:每个 SM 有多个 warp 调度器,它们可以同时调度多个 warp。在硬件层面,warp 是 GPU 调度的最小单位,每个 warp 通常由 32 个线程组成,这些线程执行相同的指令(SIMT,单指令多线程)。由于 warp 之间是独立的,多个 warp 可以并行执行。
-
多 warp 并发:当某个 warp 在等待内存操作时,SM 可以切换到其他 warp 执行,以避免计算资源的浪费。这被称为“线程级别并发”(Thread-Level Parallelism,TLP)。
-
活跃 warp 的数量:每个 SM 中活跃的 warp 数量是有限的,受限于 SM 的硬件资源(寄存器、共享内存等)。理论上,多个 warp 可以同时处于准备执行状态(active warp),但 GPU 的硬件会根据实际资源情况决定同时执行多少 warp。具体数量取决于 GPU 架构和 SM 内部的资源分配。
4.线程与 CUDA 核的映射
- 当一个 warp 被调度到 SM 上时,一个 warp 内的 32 个线程会同时执行相同的指令,但这些线程可能会被分配到 SM 内的不同 CUDA 核上进行计算。
- 一个CUDA核也可能同时执行不同warp的thread(需要核是具有多个执行单元的)
5.一个CUDA核只能同时执行一条指令吗?
在 CUDA 编程模型中,一个 CUDA 核(Streaming Processor, SP)通常在一个时钟周期内执行一条指令。然而,这个情况可能因 GPU 架构和指令集而有所不同,下面是对这一点的详细解释:
单指令执行
-
单指令执行:
- 在大多数 CUDA 架构中,一个 CUDA 核在一个时钟周期内只能执行一条指令。这是因为每个 CUDA 核被设计为一个相对简单的计算单元,主要负责执行基本的算术和逻辑操作。
-
SIMT 模型:
- CUDA 采用 SIMT(Single Instruction, Multiple Threads)模型。一个 warp 的所有线程同时执行相同的指令。这意味着在一个时钟周期内,多个线程可以并行地执行同一条指令,但每个线程可能在不同的 CUDA 核上执行。
指令级并行
虽然一个 CUDA 核在一个时钟周期内执行一条指令,但现代 GPU 支持指令级并行性,使得多个指令可以在同一个时钟周期内被执行。实现这一点的方式包括:
-
多个执行单元:
- 一个 CUDA 核可能包含多个执行单元,如加法单元、乘法单元等。这些执行单元允许在同一时钟周期内执行多种操作(如加法和乘法),虽然每个执行单元在一个时钟周期内只能执行一条指令。
-
超标量设计:
- 一些 GPU 架构采用超标量设计,允许在一个时钟周期内发射多个指令到不同的执行单元。这意味着尽管每个 CUDA 核在一个时钟周期内执行一条指令,但多个 CUDA 核可以同时执行不同的指令,从而实现更高的吞吐量。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









