







最近经常有同学反馈 GPU 利用率低,严重浪费 GPU 资源的问题,经过对一些实例分析后,总结这篇文档,希望能对使用 GPU 的同学有些帮助。
一、GPU 利用率的定义
本文的 GPU 利用率主要指 GPU 在时间片上的利用率,即通过 nvidia-smi 显示的 GPU-util 这个指标。统计方式为:在采样周期内,GPU 上面有 kernel 执行的时间百分比。
二、GPU 利用率低的本质
常见 GPU 任务运行流程图如下:
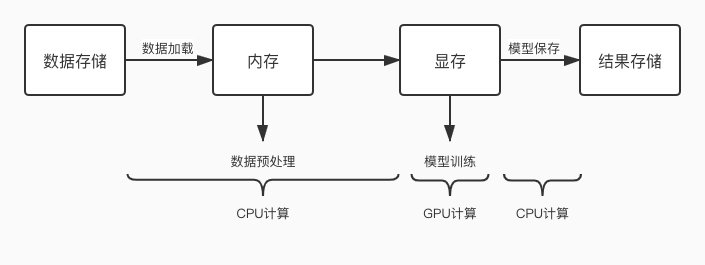
如上图所示,GPU 任务会交替的使用 CPU 和 GPU 进行计算,当 CPU 计算成为瓶颈时,就会出现 GPU 等待的问题,GPU 空跑那利用率就低了。那么优化的方向就是缩短一切使用 CPU 计算环节的耗时,减少 CPU 计算对 GPU 的阻塞情况。常见的 CPU 计算操作如下:
- 数据加载
- 数据预处理
- 模型保存
- loss 计算
- 评估指标计算
- 日志打印
- 指标上报
- 进度上报
三、常见 GPU 利用率低原因分析
1、数据加载相关
1)存储和计算跨城了,跨城加载数据太慢导致 GPU 利用率低
说明:例如数据存储在“深圳 ceph”,但是 GPU 计算集群在“重庆”,那就涉及跨城使用了,影响很大。
优化:要么迁移数据,要么更换计算资源,确保存储及计算是同城的。
2)存储介质性能太差
说明:不同存储介质读写性能比较:本机 SSD > ceph > cfs-1.5 > hdfs > mdfs
优化:将数据先同步到本机 SSD,然后读本机 SSD 进行训练。本机 SSD 盘为“/dockerdata”,可先将其他介质下的数据同步到此盘下进行测试,排除存储介质的影响。
3)小文件太多,导致文件 io 耗时太长
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









