







目标:
从原文件夹中提取多个子文件夹,合并到两个目标文件夹jpg和txt
json转txt,按格式修改txt
归一化
结果:
第一行是IR-label.json的坐标最后一个
第二行是提取单条txt最后一个坐标
第三行是提取前两个键值的(exist和gt_rect),即只要exist和gr_rect
第四行是归一化后的坐标
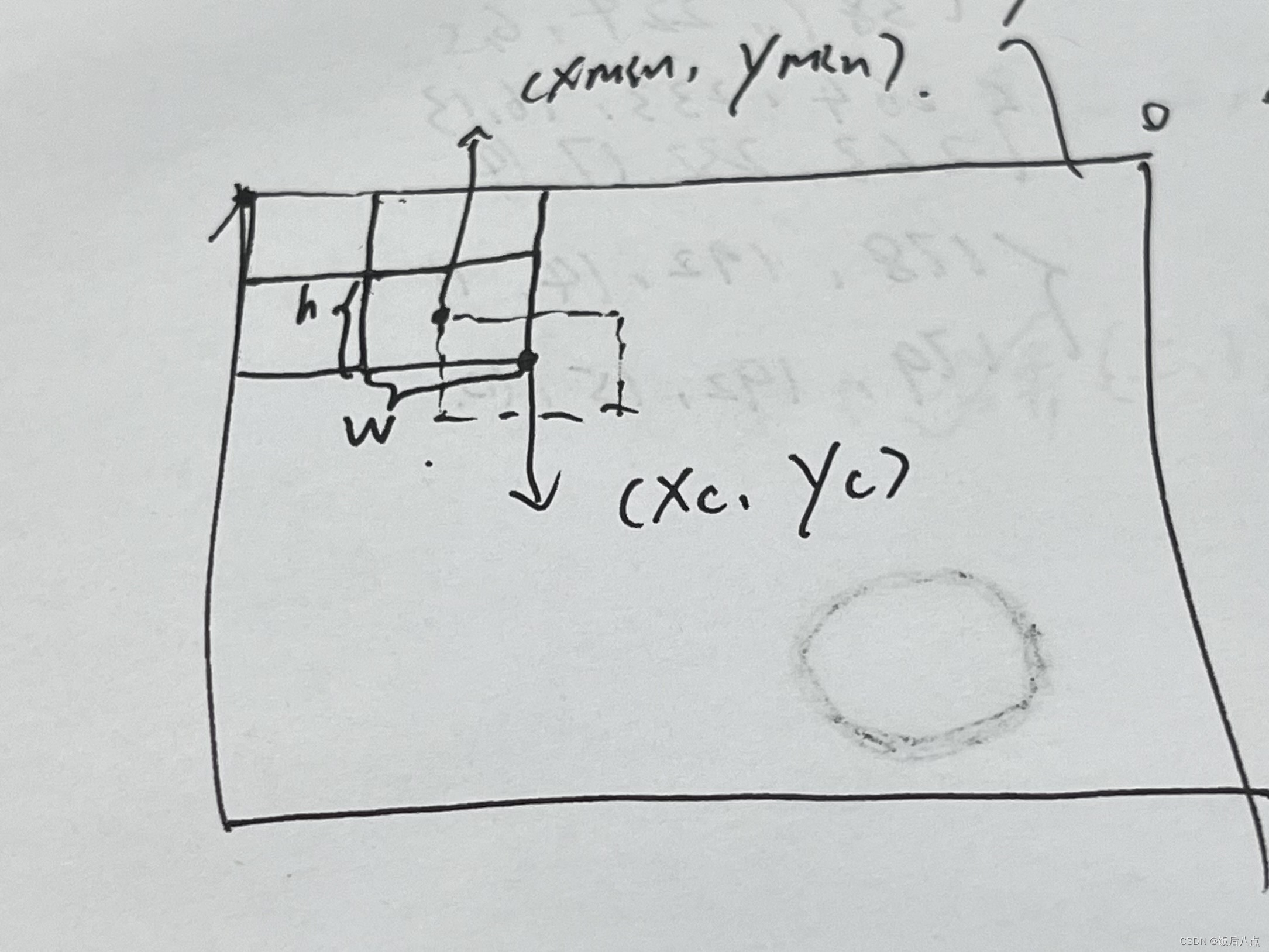
目标检测的数据格式如下:
- exist表示无人机存在
- gt_rect表示坐标信息xmin,ymin,w,h(左上角)
- 目标检测需要的坐标信息xc,yc,w,h(中心坐标)
- 原文中所有图片像素值为640x512,即img_w,img_h的值,在归一化会用到
步骤
归一化
1.对xmin,ymin,w,h进行转换,转成xc,yc,w,h
2.xc,yc,w,h除于像素值
xmin,ymin,w,h转成xc,yc,w,h
xc = xmin + w/2
yc = ymin + w/2
在yolov9的论文中,标注所有图像的像素值是640*512,因此img_w和img_h可以直接为640和512。
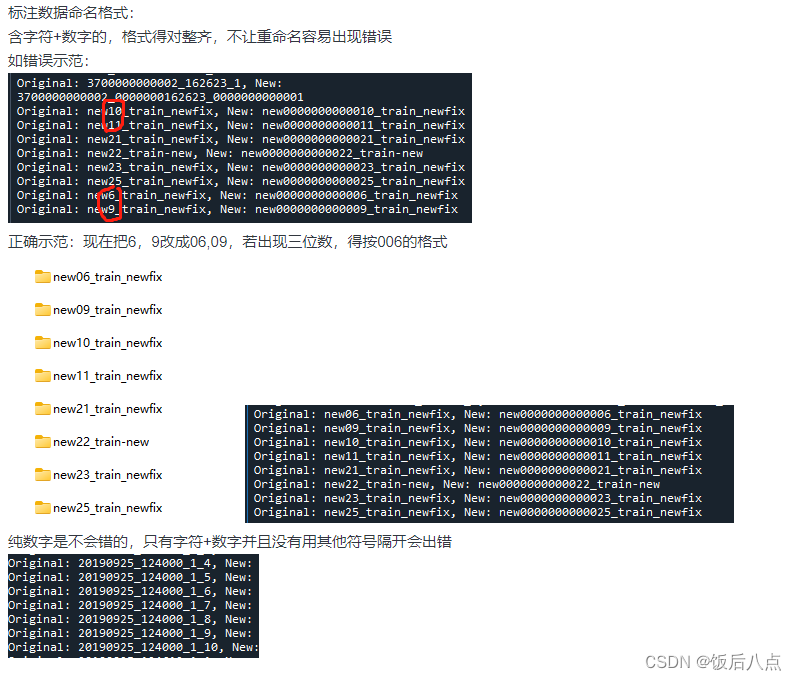
使用os.rename建议:
标注数据命名格式:含字符+数字的,格式得对整齐,不让os.listdir容易出现错误
对不上的原因是os.rename读取文件夹名字的排序含字符+数字的以字符长度来读取,原创会将排序改变,所以需要在收集和标注数据格式使注意细节。
#%%第一步:验证原数据集的张数
import os
def count_images(directory):
# 支持的图片文件扩展名
extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.gif', '.tiff'}
image_count = 0
# os.walk遍历目录
for root, dirs, files in os.walk(directory):
for file in files:
if any(file.lower().endswith(ext) for ext in extensions):
image_count += 1
return image_count
# 指定的文件夹路径
train = r"C:\Users\lina1\Desktop\数据集\Anti-UAV410\Anti-UAV410\train"
test = r"C:\Users\lina1\Desktop\数据集\Anti-UAV410\Anti-UAV410\test"
val = r"C:\Users\lina1\Desktop\数据集\Anti-UAV410\Anti-UAV410\val"
print("train:", count_images(train))
print("test:", count_images(test))
print("val:", count_images(val))
'''
train: 213995
test: 129691
val: 94711
'''
#%%第二.1步:把jpg合并到一个文件夹,按顺序命名,目标张数是train: 213995 test: 129691 val: 94711
import os
import shutil
# 设置目标父文件夹路径
parent_directory = r'C:\Users\lina1\Desktop\数据集\Anti-UAV410\Anti-UAV410\test' # 替换为你的实际文件夹路径
# 获取目录下的所有项
entries = os.listdir(parent_directory)
# 筛选出子目录
directories = [entry for entry in entries if os.path.isdir(os.path.join(parent_directory, entry))]
directoriesPath = [] # 子目录路径
for i in directories:
dirPath = r"C:\Users\lina1\Desktop\数据集\Anti-UAV410\Anti-UAV410\test"+f"\\{i}"
directoriesPath.append(dirPath)
source_folders = directoriesPath # 源文件夹路径
target_folder = r'C:\Users\lina1\Desktop\数据集\uav410\jpg\test' # 写到目标文件夹路径
#遍历源文件夹
a = 0
for folder in source_folders:
for filename in os.listdir(folder): # 获取文件名
source_path = os.path.join(folder, filename)
# 确保只处理文件(非目录)
if os.path.isfile(source_path) and filename.endswith('.jpg'):
target_path = os.path.join(target_folder, filename)
# 复制文件到目标文件夹
shutil.copy(source_path, target_path)
# 生成新的文件名
newfile = f"{directories[a]}+{filename}.jpg"
# 重命名
os.rename(os.path.join(target_folder, filename), os.path.join(target_folder, newfile))
a = a+1
print(a, folder)
'''
#2.标准化名字,预防在改名时按字符长度排名导致错误
import re
import os
# 对每个文件名应用标准化函数
def standardize_filename(filename):
# 解析所有数字部分并添加前导零
parts = re.split('(\d+)', filename)
new_parts = []
for part in parts:
if part.isdigit():
# 统一数字长度至10位,可以根据需要调整
new_parts.append(part.zfill(13))
else:
new_parts.append(part)
return ''.join(new_parts)
standardized_filenames = [standardize_filename(f) for f in directories]
# 打印结果
for orig, new in zip(directories, standardized_filenames):
print(f"Original: {orig}, New: {new}")
'''
#3.按顺序命名在rename-txt开始
folder_path = target_folder
files = [file for file in os.listdir(folder_path) if file.endswith('.jpg')]
# 重命名文件:从000001开始不是000000开始
for index, file in enumerate(files, start=1):
os.rename(os.path.join(target_folder, file), os.path.join(target_folder, f"{index:06}.jpg"))
print(index)
#%%第二.2步:把txt合并到一个文件夹,按顺序命名,目标文件数是train: 213995 test: 129691 val: 94711
import json
#目标txt文件内(每个子文件是一条json格式:key:values)
# 对json文件的数据进行获取-定义函数
def load_json(sfilename, path):
global a
with open(sfilename, 'r', encoding='utf-8') as file:
data = json.load(file)
# 计算每个键的数组长度
length_of_items = len(data["exist"])
# 创建一个列表来存储格式化后的 JSON 行
formatted_json_lines = []
# 循环遍历每个项目索引
for i in range(length_of_items):
formatted_json = {}
# 对于原始 JSON 的每个键,提取相应的值
for key, values in data.items():
if key == "gt_rect":
formatted_json[key] = values[i] if i < len(values) else None
else:
formatted_json[key] = values[i] if i < len(values) else None
# 将每个转换后的 JSON 对象添加到列表中
formatted_json_lines.append(json.dumps(formatted_json))
file.close()
# 打印或保存结果
for line in formatted_json_lines:
txt_path = path+f'\\{a:06}.txt'
file = open(txt_path, 'w')
file.write(line)
file.close()
a = a + 1
print(line)
# 设定目录
source_path = r'C:\Users\lina1\Desktop\数据集\Anti-UAV410\Anti-UAV410\train' # 源目录
target_path = r'C:\Users\lina1\Desktop\数据集\uav410\txt\train' # 写到目标目录
# 读取 JSON 数据
# 获取目录下的所有项
entries = os.listdir(source_path)
# 筛选出子目录
directories = [entry for entry in entries if os.path.isdir(os.path.join(source_path, entry))]
directoriesPath = [] # 子目录路径
for i in directories:
dirPath = r"C:\Users\lina1\Desktop\数据集\Anti-UAV410\Anti-UAV410\train"+f"\\{i}"
directoriesPath.append(dirPath)
source_folders = directoriesPath # 源文件夹路径
a = 1
for folder in source_folders:
for filename in os.listdir(folder): # 获取文件名
source_path = os.path.join(folder, filename)
# 确保只处理文件(非目录)
if os.path.isfile(source_path) and filename.endswith('.json'):
data = load_json(source_path, target_path) # 对json文件进行读取
#%%第二.2.1步:提取前两个key的数字,替换exist的1为0,
#从txt文件提取,txt内的信息是json格式,提取到的数字放在values-txt内
#exist=1改0
import os
import json
# 原始文件夹路径
original_folder_path = 'C:\\Users\\lina1\\Desktop\\数据集\\uav410\\txt\\test'
# 新文件夹路径
new_folder_path = 'C:\\Users\\lina1\\Desktop\\数据集\\uav410\\values-txt\\test'
# 遍历原始文件夹中的所有txt文件
for filename in os.listdir(original_folder_path):
if filename.endswith('.txt'):
original_file_path = os.path.join(original_folder_path, filename)
new_file_path = os.path.join(new_folder_path, filename)
# 读取文件内容
with open(original_file_path, 'r') as file:
data = json.load(file)
# 修改exist的值
if data['exist'] == 1:
data['exist'] = 0
# 检查gt_rect长度并写入output.txt
if len(data["gt_rect"]) <= 4:
output_line = f'{data["exist"]} '
output_line += ' '.join(str(x) if x != '' else ' ' for x in data["gt_rect"]) + '\n'
# 对每个元素检查,如果为空则替换为 "0 0 0 0",否则转换为字符串
#output_line += ' '.join('0 0 0 0' if x == '' else str(x) for x in data["gt_rect"]) + '\n'
with open('output.txt', 'a') as file: # 使用追加模式'a',避免覆盖之前的数据
file.write(output_line)
else:
print(f"文件 {filename} 的数据列表不完整,无法写入文件。")
# 将修改后的数据写入新文件夹的对应文件
with open(new_file_path, 'w') as file:
file.write(f'{data["exist"] } ')
rect_values = ' '.join(str(x) if x != '' else ' ' for x in data["gt_rect"])
file.write(f'{rect_values}\n')
print(new_folder_path,'所有文件已处理并保存到新文件夹。')
#%%第二.2.2步:填补txt的缺失值,验证打印少于4个0的
import os
import re
def find_files_with_few_numbers(folder_path, max_numbers=4):
files_with_few_numbers = [] # 保存文件名的列表
for file in os.listdir(folder_path):
if file.endswith('.txt'):
file_path = os.path.join(folder_path, file)
with open(file_path, 'r') as f:
content = f.read()
# 使用正则表达式查找所有的数字
numbers = re.findall(r'\d+', content)
num_count = len(numbers)
# 如果数字数量少于指定的最大数量,添加到列表
if num_count < max_numbers:
files_with_few_numbers.append(file)
# 如果只有一个数字,进行替换并保存文件
if num_count == 1:
modified_content = re.sub(r'(\d+)', r'\1 0 0 0 0', content)
with open(file_path, 'w') as f:
f.write(modified_content)
return files_with_few_numbers
# 调用函数
folder_path = 'C:\\Users\\lina1\\Desktop\\数据集\\uav410\\values-txt\\train'
result = find_files_with_few_numbers(folder_path)
print(f"Txt files with less than {4} numbers: {result}")
print(folder_path,'缺失已处理并保存到新文件夹。','缺失了:',len(result))
#C:\Users\lina1\Desktop\数据集\uav410\values-txt\val 所有文件已处理并保存到新文件夹。 缺失了 393
#C:\Users\lina1\Desktop\数据集\uav410\values-txt\test 缺失已处理并保存到新文件夹。 缺失了: 728
#C:\Users\lina1\Desktop\数据集\uav410\values-txt\train 缺失已处理并保存到新文件夹。 缺失了: 779
#%%第三步:归一化:xmin,ymin,w,h/img_w,img_h
#对xywh进行归一化,并保留10位小数(通过计算IR_label的最后一个值得到)
#读取每个txt文件
#修改第2到第四个整数,并归一化
import os
import json
# 遍历原始文件夹中的所有txt文件
def normalize_values(folder_path, img_w, img_h):
# 遍历指定文件夹中的所有txt文件
for file in os.listdir(folder_path):
if file.endswith('.txt'):
file_path = os.path.join(folder_path, file)
with open(file_path, 'r') as f:
lines = f.readlines()
# 对每一行进行处理
new_lines = []
for line in lines:
parts = line.split()
if len(parts) >= 4:
# 提取最后四个数值并转换为浮点数(bbox:xmin,ymin,w,h)
xmin, ymin, w, h = map(int, parts[-4:])
# 进行归一化
xc = xmin + w/2
yc =ymin + h/2
xc /= img_w
yc /= img_h
w /= img_w
h /= img_h
# 更新行
new_line = ' '.join(parts[:-4] + [f"{xc:.10f}", f"{yc:.10f}", f"{w:.10f}", f"{h:.10f}"])
new_lines.append(new_line)
else:
new_lines.append(line)
# 将处理后的内容写回文件
with open(file_path, 'w') as f:
f.writelines([line + '\n' for line in new_lines])
folder_path = 'C:\\Users\\lina1\\Desktop\\数据集\\uav410\\zero-txt\\train'#train test val
normalize_values(folder_path, 640, 512)
print(folder_path,'归一化已处理并保存到新文件夹。')
















 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









