







A Transformer-Embedded Multi-Task Model for Dose Distribution Prediction【放射剂量预测】
原文地址
TransMTDP
本文于2023年发表于International Journal of Neural Systems(中科院二区)
背景
局限一
现有Deep learning (DL) 方法往往忽略了剂量图中的等剂量线、梯度信息,这些与剂量预测任务高度相关的特征。

由于放疗计划的首要目标是将规定剂量集中在PTV上,同时尽可能减少OARs上的剂量沉积。那么剂量图显现出来的就是,剂量水平从PTV向周围快速下降,即有明显的下降趋势和梯度特性,如Fig.1 (d) 等剂量线图 和 (e) 梯度图所示。
简单来说,等剂量线图中,同一颜色表示这个区域在同一剂量范围中,越红剂量水平越高。而梯度图,表示的是,剂量水平的变化速度,越红剂量变化越快(PTV边缘的剂量水平变化速度较快)。
局限二
传统多任务学习策略,通常共享浅层来集成各种任务,因此不同任务输出层间的联系较弱,导致多个任务之间不是很匹配。
局限三
常用于提取图像特征的CNN的卷积核大小有限,无法完全提取全局特征。
但是,人体的许多器官是对称的,而且剂量图也呈现丰富的全局性特征。
比如,左股骨和右股骨作为直肠癌的两个典型桨叶,具有相似的解剖特性,使用传统的CNN很难捕获这种远程信息。因此,作者认为结合局部和全局信息可以提高预测性能。
主要思路
采用多任务学习策略,除主要预测任务外,还纳入了两个辅助任务:等剂量线预测任务(auxiliary isodose lines pre-
diction task),为每个像素提供粗粒度的剂量范围,结合主任务得到的微粒度剂量值,可得到剂量分布的多粒度信息,以及梯度图预测任务(auxiliary gradient prediction task),用于提取辐射模式或边缘信息等梯度属性。这样可以使主剂量预测任务受益于增强的等剂量线特性和梯度信息。(解决局限一)
这个多任务学习策略,与MtAA-NET中的多任务学习策略相同,都是采用一个shared encoder集成几个任务。
同时,TransMTDP使用了两个额外的损失:等剂量一致性损失(Isodose Consistency loss)和梯度一致性损失(Gradient Consistency loss),来加强辅助任务生成的剂量分布特征与主任务之间的匹配程度,实现更明确的剂量预测。(解决局限二)
Transformer可以利用一种关注机制来度量所有特性补丁之间的关系,从而捕获远程依赖关系中的上下文特性。因此作者将Transformer嵌入架构。(解决局限三)
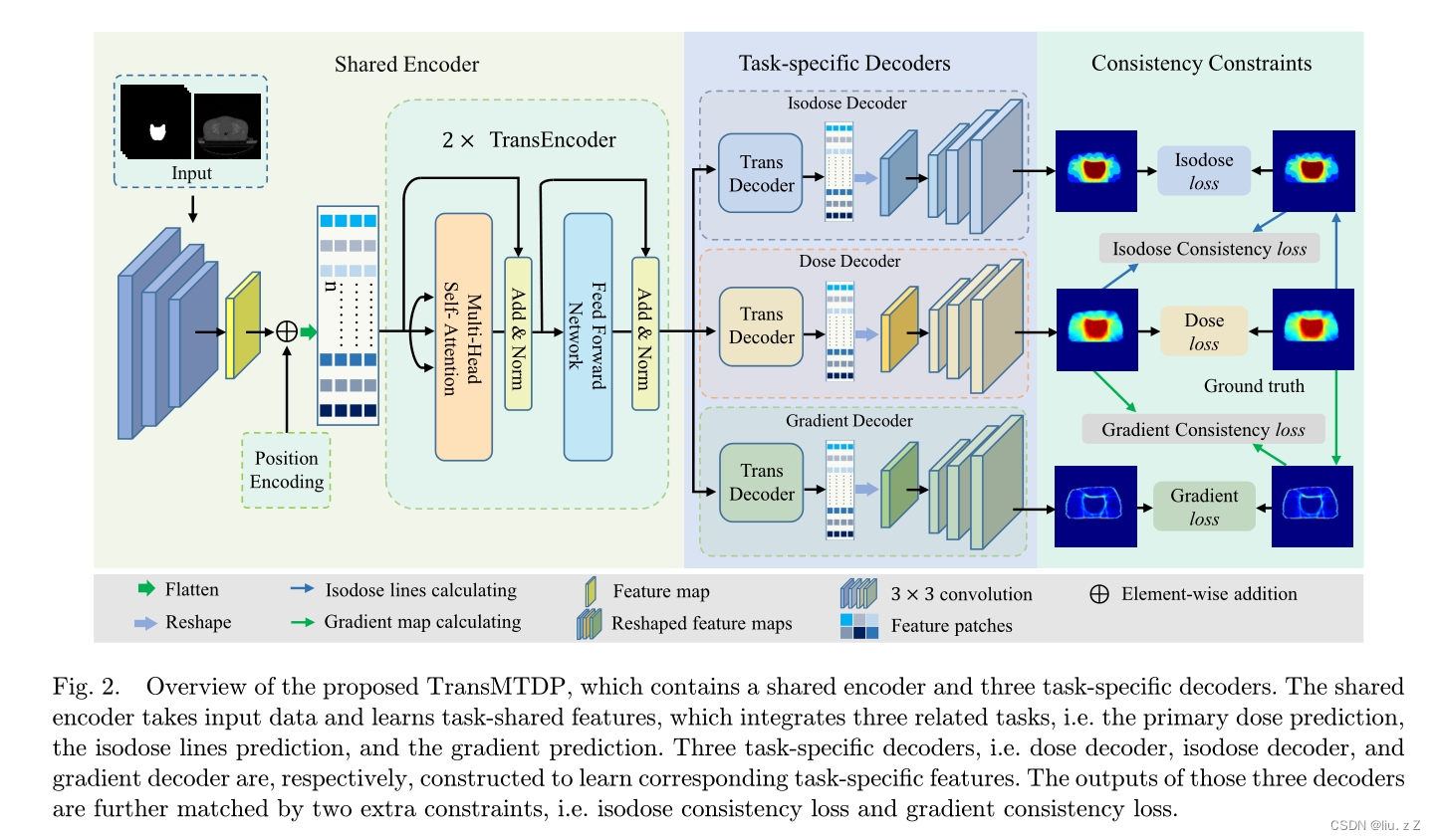
模型设计
Two auxiliary tasks
Isodose Lines Prediction Task
与地理的等高线原理类似,这个任务利用
N
N
N个等剂量线
{
d
1
,
d
2
,
.
.
.
.
.
,
d
n
}
\{d_1,d_2,.....,d_n\}
{d1,d2,.....,dn},将剂量图分为
N
−
1
N-1
N−1个区域
{
A
1
,
2
,
A
2
,
3
,
.
.
.
.
.
,
A
n
−
1
,
n
}
\{A_{1,2},A_{2,3},.....,A_{n-1,n}\}
{A1,2,A2,3,.....,An−1,n}。
简单来说,就是根据剂量范围为每个像素点分配区域标签。因此,这个任务使用的decoder结构与主任务相似,除最后一个卷积层用于输出一个 ( N − 1 ) (N-1) (N−1)通道的分类结果。类似one-hot编码,通道 i i i中的每个像素都有一个属于 A i , i + 1 A_{i,i+1} Ai,i+1区域的概率(最后有一个阈值判断是否属于这个区域)。
Gradient Prediction Task
这个任务利用Sobel算子计算梯度。
补充: 在图像处理中,梯度表示的是灰度值的变化率,即像素值的变化速度。Sobel算子计算的是图像在水平和垂直方向上的梯度,它在图像中检测边缘的位置,而边缘通常表示的是像素值由暗到亮或由亮到暗的变化。因此,Sobel算子得到的梯度信息可以用来表示图像中灰度值变化的快慢,边缘处的梯度值通常较大,而平滑区域的梯度值较小。
下面是Sobel算子的公式:
水平方向上的Sobel算子:
-1 0 1
-2 0 2
-1 0 1
垂直方向上的Sobel算子:
-1 -2 -1
0 0 0
1 2 1
一般来说,在图像处理中,通常将水平方向和垂直方向的Sobel算子和图像进行卷积操作,然后将两个方向上的梯度进行合并,即:
G = G x 2 + G y 2 G = \sqrt{G_x^2 + G_y^2} G=Gx2+Gy2
这里 G x G_x Gx 和 G y G_y Gy 分别表示图像在水平和垂直方向上的梯度, G G G 表示合并后的梯度。
Overall architecture
- 三个任务均采用类似 U-Net 的 encoder-decoder 网络,encoder是共享的,三个decoder的参数各不相同。
- 采用skip connections,传递信息,在任务指定的解码器和共享编码器之间进行特征重用和多级特征聚合。
- TransEncoder被嵌入在Shared Encoder的CNN之后,三个TransDecoder被分别嵌入在三个任务的解码器中。
损失函数
剂量预测任务损失

等剂量线预测任务损失

梯度预测任务损失

以上三个损失通过修正
F
F
F来迫使shared encoder集中注意在剂量分布图中与剂量值、等剂量线和梯度相关的特征上,从而增强提取特征的表现力。
等剂量一致损失

梯度一致损失

这两个一致性损失迫使剂量预测任务的解码器也集中注意在剂量分布图中与等剂量线和梯度相关的特征上,提高了预测准确性。
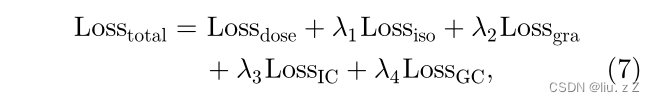
最后这个五个损失各个乘一个超参数,用于衡量在总损失中的占比。然后,模型的参数通过最小化这个总体损失来进行训练。
实验结果
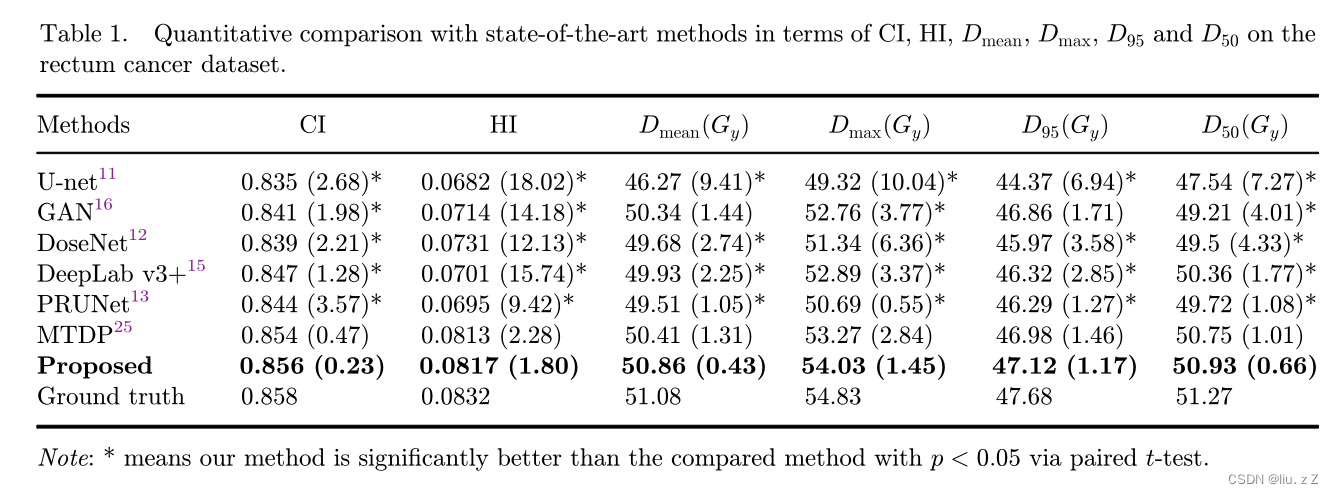
实验在一个私有直肠癌数据集以及OpenKBP-2020 AAPM Grand Challenge中的头颈癌数据集上进行。
实验的评价指标为 conformity index (CI), heterogeneity index (HI), Dose volume histogram (DVH)。公式见 MtAA-NET
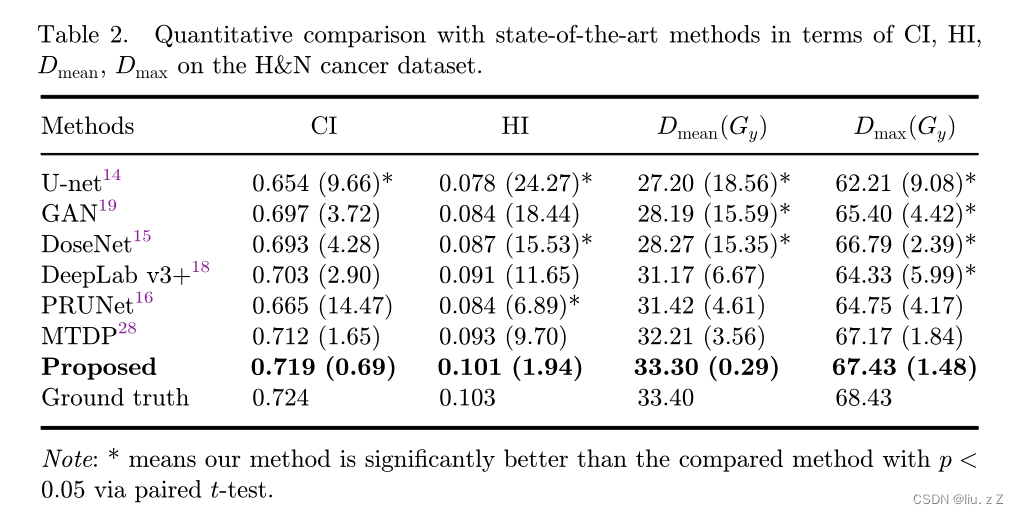
补充: Paired t-test 首先计算两组数据之间的差值,然后将这些差值与它们的标准误差进行比较,以确定差异是否大到足以认为两组数据之间存在显著差异。Paired t-test 通常会生成一个t值和对应的p值,p值表示观察到的差异是否显著。
而 p 值的含义是:在原假设为真的情况下,观察到数据或者更极端情况的概率。如果 p 值很小(通常小于设定的显著性水平,如0.05),则表明观察到的数据与原假设不一致的可能性很高,我们就会有足够的理由拒绝原假设,认为观察到的差异是真实存在的。
独立样本 t 检验的公式如下:
t = Mean 1 − Mean 2 S D 1 2 n 1 + S D 2 2 n 2 t = \frac{\text{Mean}_1 - \text{Mean}_2}{\sqrt{\frac{SD_1^2}{n_1} + \frac{SD_2^2}{n_2}}} t=n1SD12+n2SD22Mean1−Mean2
其中:
- Mean 1 \text{Mean}_1 Mean1 和 Mean 2 \text{Mean}_2 Mean2 分别是两组数据的均值;
- S D 1 SD_1 SD1 和 S D 2 SD_2 SD2 分别是两组数据的标准差;
-
n
1
n_1
n1 和
n
2
n_2
n2 分别是两组数据的样本大小。

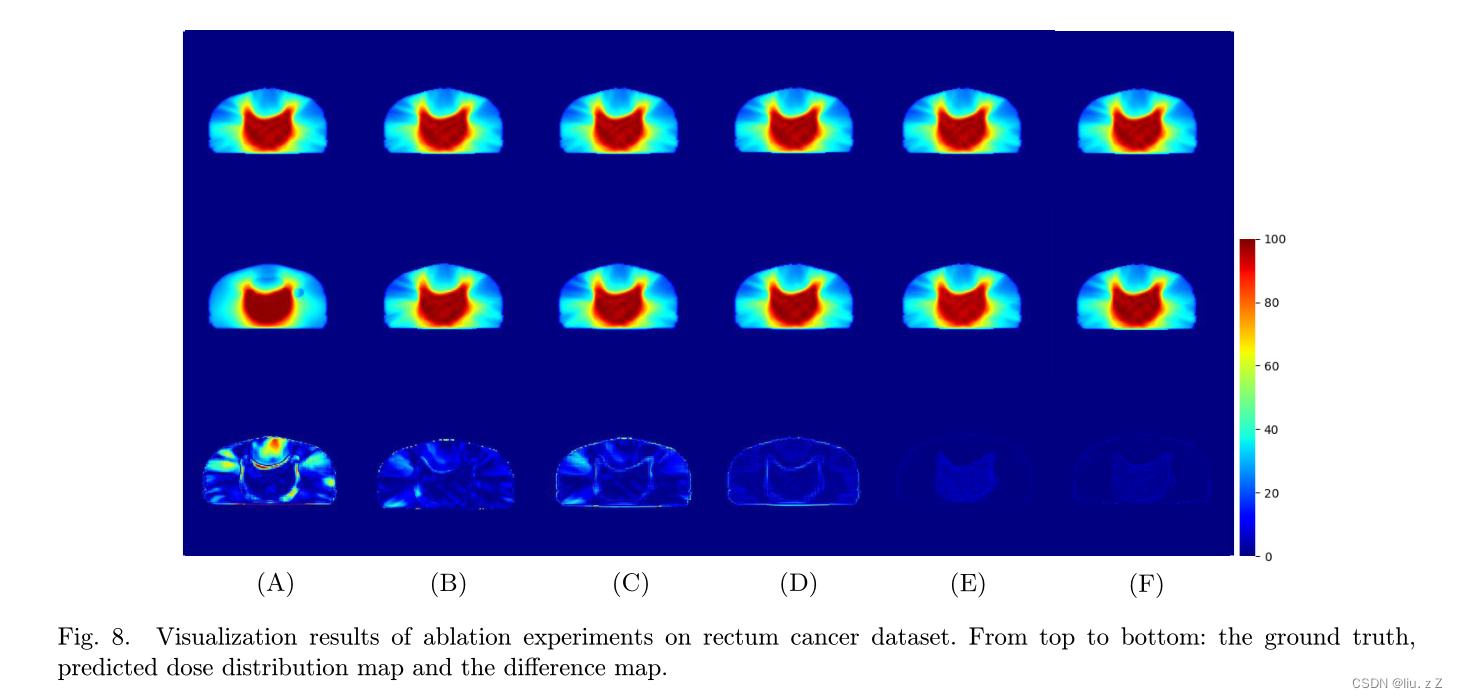
如上所示,TransMTDP 在 CI, HI以及
D
m
e
a
n
D_{mean}
Dmean,
D
m
a
x
D_{max}
Dmax 都更接近 Gound truth,可视化后与Gound truth的差异也相对更小。

















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









