







 本文详细介绍了Self-Attention机制在自然语言处理中的作用,特别是如何在Pytorch中实现这一机制,包括计算过程和关键组件如查询、键和值的处理。
本文详细介绍了Self-Attention机制在自然语言处理中的作用,特别是如何在Pytorch中实现这一机制,包括计算过程和关键组件如查询、键和值的处理。
使用Pytorch实现Self-Attention架构
Self-Attention
自注意力(Self-Attention)机制是一种用于建模序列数据中元素之间关系的技术,最初广泛应用于自然语言处理领域,特别是在Transformer模型中。在自注意力机制中,每个元素(例如单词或时间步)都与其他元素进行交互,并且注意力权重决定了每个元素对其他元素的重要性。
在 Self-Attention 中,首先计算一个注意力分数矩阵,其大小为 N × N N \times N N×N,其中 N N N 是序列的长度。注意力分数矩阵的每个元素表示一个元素对另一个元素的注意力权重,这些权重通常通过计算元素之间的相似性得到。
通常 Self-Attention 的计算过程如下:
-
计算查询、键和值: 对于给定的序列,首先通过三个独立的线性变换(通常是全连接层)来计算查询向量 Q Q Q、键向量 K K K 和值向量 V V V。这些向量的维度通常是预先定义的,通常是模型的超参数。
-
计算注意力分数: 使用查询向量 Q Q Q 和键向量 K K K 之间的点积来计算注意力分数。然后通过应用 s o f t m a x softmax softmax函数将这些分数归一化,以获得注意力权重 A A A。
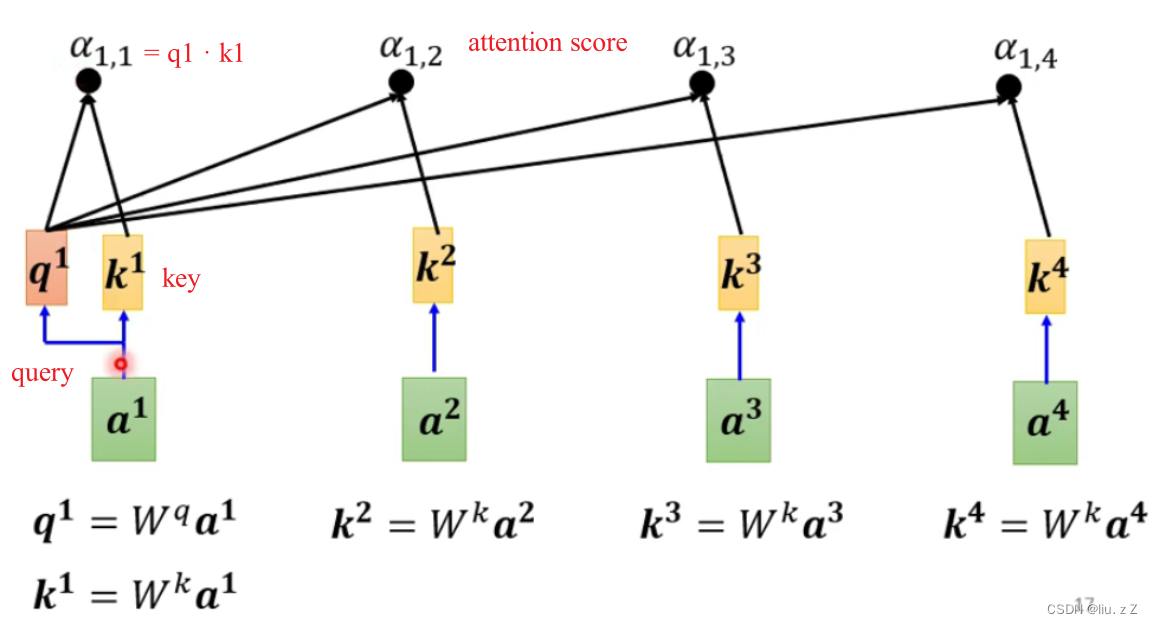
-
加权求和: 使用注意力权重对值向量 V V V 进行加权求和,以获得注意力加权的输出。
这样,通过将每个元素与其他元素进行交互,并且根据它们之间的关系调整重要性,自注意力机制能够捕捉序列中的长距离依赖关系,并且不受序列长度的限制。
Pytorch 实现
在PyTorch中 Self-Attention 可以通过定义一个自注意力层来完成。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size # 词嵌入的维度
self.heads = heads # 注意力头的数量
self.head_dim = embed_size // heads # 每个注意力头的维度
assert (
self.head_dim * heads == embed_size
), "Embedding size must be divisible by number of heads"
# 查询、键和值的线性变换
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0] # 序列的长度
# 对查询、键和值进行线性变换
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(query)
# 将值、键和查询分割为多个头
values = values.view(N, -1, self.heads, self.head_dim)
keys = keys.view(N, -1, self.heads, self.head_dim)
queries = queries.view(N, -1, self.heads, self.head_dim)
# 将注意力分数计算为查询和键之间的点积,并进行缩放
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# 应用掩码(mask)来忽略无效位置的注意力权重
# 将掩码中值为0的位置对应的注意力分数设置为一个很大的负数(这里使用了 -1e20)
# 从而使得在 softmax 操作中这些位置的注意力权重接近于0,从而实现忽略这些位置的效果。
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# 计算注意力权重
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
# 将注意力权重乘以值
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, -1, self.heads * self.head_dim
)
# 将多个头的输出拼接在一起,并通过线性层进行处理
out = self.fc_out(out)
return out















 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









