







线性回归是一个或多个自变量与因变量之间的关系模型,它通过找到一条直线来拟合数据。
逻辑回归是线性回归的拓展,可以解决分类问题。
应用领域
线性回归(Linear Regression): 回归
逻辑回归(Logistic Regression) : 分类
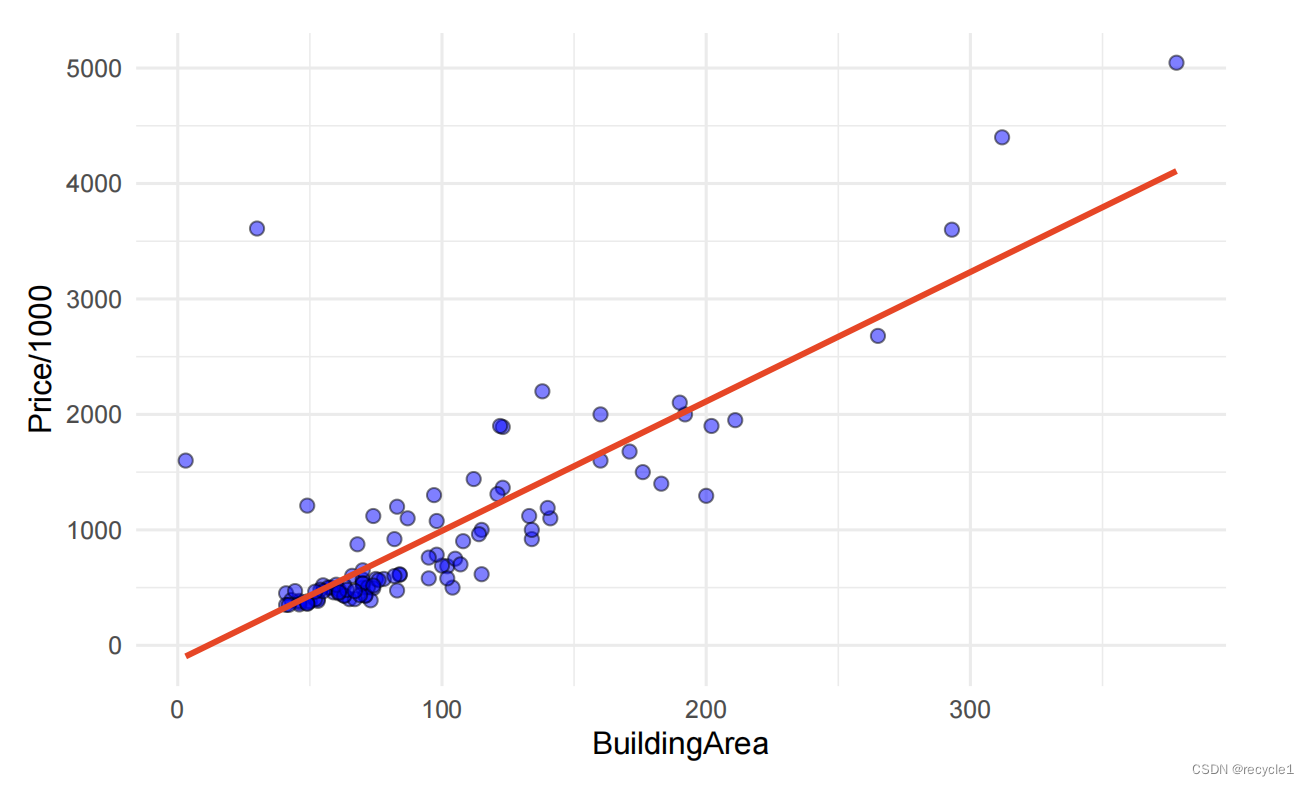
简单线性回归
原理及步骤
-
确定自变量和因变量,因变量和自变量之间可能存在某些关系,通过自变量可以估计因变量的值。
-
选择数据,计算线性模型的参数,即直线斜率(slope / β1)和截距(intercept / β0),这里需要注意的是,线性回归是参数化模型(premetric model),也就是说,在这里我们假定存在一个真实的模型,Y=β0+β1X+ϵ,β1是斜率,β0是截距,ϵ是误差,我们假定现实中的数据是由这个模型生成的,而我们现在希望通过数据来回推或者估计真实模型的参数,也就是Y=β0+β1X,在我们最后估计的模型中没有ϵ。具体的计算上:
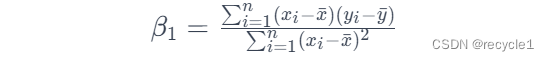

对于计算公式如何得到,这里我们不深入研究,但是通过这个公式的计算,我们希望模型的损失函数越小越好,一般我们使用均方误差(Mean Squared Error,MSE)越小越好,即每个点和预测值的差值越小越好。
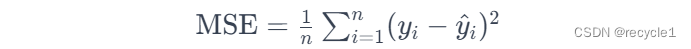
-
模型评估,通过R2等评估模型。
优点
- 简单易实现:线性回归模型简单直观,易于实现和解释。
- 模型解释性强:线性回归提供了对每个自变量影响因变量的量化评估,这使得模型具有很高的解释性。(即通过斜率大小可以估计自变量对因变量的影响)
- 应用广泛:线性回归可以应用于许多实际问题中,比如经济学、社会科学等。
缺点
- 无法拟合非线性关系:线性回归假设自变量和因变量之间存在线性关系,在许多问题中自变量和因变量的关系可能是非线性的。
- 对异常值敏感:线性回归对离群点或异常值非常敏感,这可能极大影响了预测的准确性。
- 过拟合风险:在包含大量自变量的情况下,线性回归模型可能会过度拟合训练数据,导致其泛化能力降低。
改良的线性回归
为了克服过拟合风险,可以通过对不同的自变量设置权重的方式,并增加惩罚项,来解决。
我们有两种相似的方法,Lasso和Ridge,这些方法都在损失函数中增加惩罚项,只是一个是L1范式,一个是L2范式。
Ridge损失函数:

Lasso损失函数:
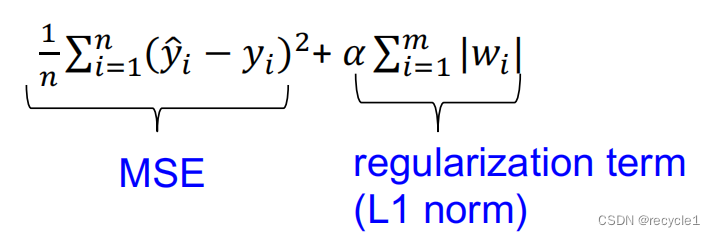
α控制了模型复杂度和性能之间的平衡(trade-off)
当α过大时,模型变得简单,权重趋于0,可能变为欠拟合,
当α过小时,模型过于复杂,将导致过拟合。
另外,Lasso可以将很多特征的权重直接压缩为0而不是趋近0,它可以作为一种特征选择的工具,权重不为0的特征是相关特征。
代码实现
这里我们可以使用sklearn来实现线性回归,具体详情可查询官网:
线性回归:https://scikit-learn.org.cn/view/394.html
- 加载库
from scipy import signal
from sklearn.preprocessing import MinMaxScaler, PolynomialFeatures
from sklearn.model_selection import train_test_split
# 线性回归
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
- 数据选择
生成随机数据
def simulate_data(n_samples):
random_data = np.random.RandomState(25)
x = random_data.uniform(-3, 3, size=n_samples)
y_no_noise = (np.sin(4 * x) + x)
y = (y_no_noise + random_data.normal(size=len(x))) / 2
return x.reshape(-1, 1), y
X,y = simulate_data(65)
plt.plot(X,y,'o')
plt.ylim(-3,3)
plt.xlabel("Feature")
plt.ylabel("Target")

3. 拟合模型
lr = LinearRegression().fit(X_train, y_train)
print("coef:",lr.coef_)
print("intercept:", lr.intercept_)
### coef: [0.45384321]
### intercept: -0.03133361831813451
- 性能评估
print("Training set R^2 score: {:.2f}".format(lr.score(X_train, y_train)))
print("Test set R^2 score: {:.2f}".format(lr.score(X_test, y_test)))
### Training set R^2 score: 0.56
### Test set R^2 score: 0.64
- Ridge
ridge = Ridge().fit(X_train, y_train)
- Lasso
lasso = Lasso().fit(X_train, y_train)
- 通过调整α选择特征
alp_array=[0.1,0.01,0.001,0.0001]
for alp in alp_array:
lasso=Lasso(alpha=alp).fit(X_train,y_train)
print("Training set score: {:.2f}".format(lasso.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lasso.score(X_test, y_test)))
print("Number of features used:", np.sum(lasso.coef_ != 0))
逻辑回归
逻辑回归是在线性回归外面套了一个非线性函数,sigmoid:
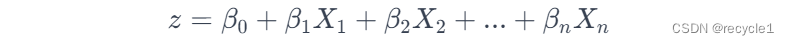
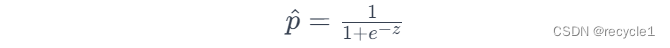
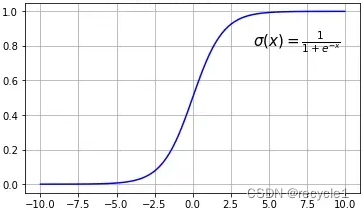
优点(与线性回归类似)
- 简单高效:模型结构简单,易于实现,且计算效率高。
- 可解释性强:逻辑回归不仅给出预测类别,还能给出属于某一类别的概率,这对于理解和解释模型十分有帮助。
- 避免过拟合:逻辑回归较少受到高维空间下的过拟合问题影响,特别是在正则化技巧应用得当时。
缺点(与线性回归类似)
- 无法拟合非线性关系:逻辑回归假设数据是线性可分的,对于复杂的非线性数据,性能可能较差。
- 特征空间的限制:当特征数量远超过样本数量时,逻辑回归可能不会表现得很好。
- 对异常值敏感:逻辑回归对异常值比较敏感,异常值可能会显著影响性能。
- 类别不平衡问题:在目标变量的类别极不平衡的情况下,逻辑回归模型可能会倾向于多数类,从而影响分类性能。
代码实现
这里我们可以使用sklearn来实现逻辑回归,具体详情可查询官网:
逻辑回归:https://scikit-learn.org.cn/view/378.html
- 加载库
from sklearn.datasets import load_breast_cancer
# 逻辑回归
from sklearn.linear_model import LogisticRegression
- 数据选择
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=0)
- 拟合数据
logistic_regression = LogisticRegression(solver='liblinear')
logistic_regression.fit(X_train, y_train)
- 模型评估
print("Accuracy on training set: {:.2f}".format(logistic_regression.score(X_train, y_train)))
print("Accuracy on test set: {:.2f}".format(logistic_regression.score(X_test, y_test)))
### Accuracy on training set: 0.96
### Accuracy on test set: 0.94
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











