






视觉里程计只有短暂的记忆,如果希望获得长久的效果最优的状态,就需要后端的优化。在后端优化中,我们通常考虑一个更长的时间内的状态估计问题,不仅使用过去的信息,也会使用未来的信息来更新自己,这种方式被称为批量的,与之相对,如果当前的状态只由过去的时刻决定,就称为渐进的。
SLAM的过程可以由运动方程加一个观测方程来确定,假设在到
的时间段内,有
到
共
个姿态,并且观测到了
到
一共
个路标,那么按照之前的写法,应该有:
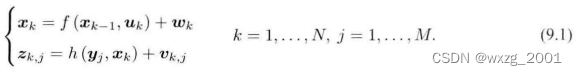
对于这两个方程,有下面几点需要注意的地方:
①观测方程中,只有在某个位姿下观测到了某个路标点才会产生观测数据,否则没有数据。
②可能没有测量运动的装置,所以可能没有运动方程,在这种情况下,有多种处理方式:认为确实没有运动方程,或假设相机不动,或假设相机匀速运动。
由于噪声的存在,这里的位姿和路标点
都不是一个准确的值,应该看成服从某种概率分布的随机变量。现在问题就变成了有一些观测数据
和运动数据
的情况下(这两个量也是带有噪声的,不是绝对准确),如何确定状态量的分布。在常见的情况下,我们假设状态量和噪声都服从高斯分布,均值看作是对变量最优值的估计,协方差矩阵则度量了它的不确定性。
运动方程可以看作是利用运动学公式计算出的下一个时刻的位置信息,但是这个信息完全是自己算出来的,而不依赖观测的数据,在实际情况下,只使用运动方程显然是不行的,只有运动方程的情况下(下图左侧部分),由于噪声的存在,每次计算都是在加入了当前时刻误差的情况下计算的新值,所以误差会越来越大,最后偏得离谱。所以我们的做法都是将运动方程与观测方程结合起来(下图右侧部分),彼此互相校正,从而得到更加准确的信息。
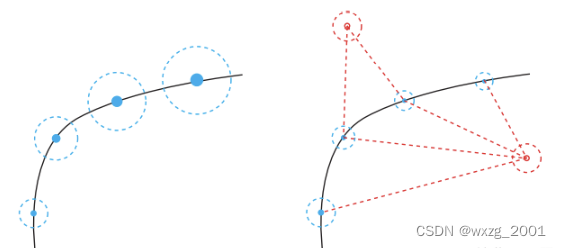
原理
由于位姿和路标点都是待估计的变量,所以这里我们改变一下符号,让表示
时刻所有的未知量,作为一个状态向量,这里面包含了当前时刻的相机位姿和这个时刻观测到的
个路标点,于是写成:

于是式(9.1)可以简化成:
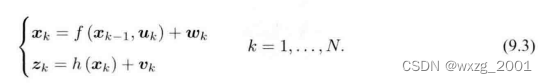
现在考虑时刻的情况,我们的目标是用过去的数据,来估计现在的状态分布,即:

按照贝叶斯公式,这个条件概率公式可以转换为先验和似然的乘积:
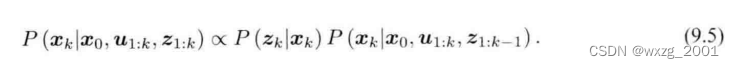
这个式子中,似然的部分由观测方程给出,而先验部分,是根据过去时刻得到的,于是将先验部分展开:

先看一下十四讲上的思路。对于一般的卡尔曼滤波,当我们假设了马尔可夫性后,由于当前时刻的状态只与上一个时刻有关,所以式中右侧第一部分可以进一步简化:
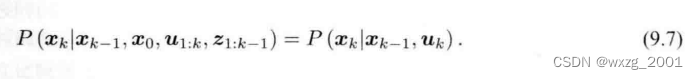
由于时刻状态与
之前的无关,所以就简化成只与
和
有关的形式,与
时刻的运动方程对应。第二部分可简化为:
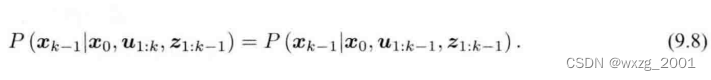
这是考虑到时刻的输入量
与
时刻的状态无关,所以我们把
拿掉。可以看到,这一项实际是
时刻的状态分布。这其实表明了,我们实际在做的是“根据
时刻的状态分布如何推导
时刻的状态分布”这样一件事。这意味着我们不需要存储许多状态量,而是对一个状态量不断进行维护和更新,进一步如果假设状态量符合高斯分布,那么就只需要维护状态量的均值和协方差即可。
对于高斯分布,我们可知:
,
,
则有:
则我们对于先验可知如下,时刻后验来推理
时刻的先验,光靠运动方程预测,则不确定会逐渐上升:
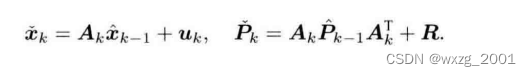
似然则有:
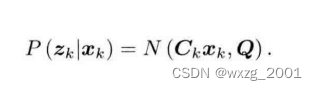
那么我们可知时刻的先验,是由似然乘上后验:
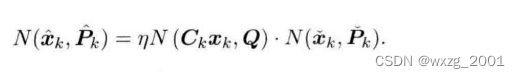
等式两侧都是高斯分布,则我们只需要比较指数部分:
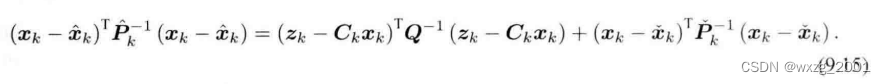
具体的推理这里省略,我们可知
二次项系数有,其中的可以由
时刻的后验推出,由前式可得:
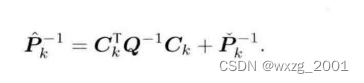
一次项系数有:
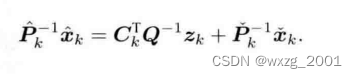
同时我们声名一个变量,作为修正量,也就是我们俗称的卡尔曼增益。
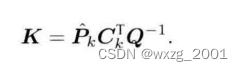
的形式不一定绝对是这样,也可以有别的形式(例如SMB恒等式得)。
于是我们可以得到,最终的:
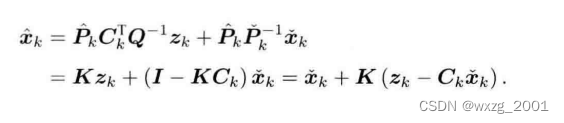
其实卡尔曼滤波的更新过程,可以理解为多个来源的数据的融合,从而得到更精确的结果。
代码
我们给出了一个简单的示例,来帮助我们更好的理解卡尔曼滤波的工作原理。
import numpy as np
import matplotlib.pyplot as plt
t = np.linspace(1, 100, 100) #采样100次
a = 0.5 #加速度,匀加速直线运动
v0 = 0 #初速度
s0 = 0 #初始位置
m_var = 120**2 #位置测量仪器的方差,越大则测量值占比越低,Q~N(0,m_var)
v_var = 50**2 # 速度测量仪器的方差,R~N(0,v_var)
nums = t.shape[0]
# 我们假设为理想模型,则能推导出的真实位置,实际应用中不会存在简单易推理的运动模型,真实位置将不可知
# 对于实际应用,我们并不需要知道真实值,而是通过预测值和观测值,来得到最优估计值,不断逼近真值
real_positions = [0] * nums
real_positions[0] = s0
# 观测值,通过理论值加上噪声模拟获得,初值即理论初始值加上观测噪声
measure_positions = [0] * nums
measure_positions[0] = real_positions[0] + np.random.normal(0, m_var**0.5)
# 不使用卡尔曼滤波,也不使用实际观测值修正,单纯依靠运动模型来预估的预测值,仅初值由观测值决定
predict_positions = [0] * nums
predict_positions[0] = measure_positions[0]
# 最优估计值,也就是卡尔曼滤波输出的真实值的近似逼近,同样地,初始值由观测值决定
optim_positions = [0] * nums
optim_positions[0] = measure_positions[0]
# 卡尔曼滤波算法的中间变量
pos_k_1 = optim_positions[0]
predict_var = 0
for i in range(1,t.shape[0]):
# 根据理想模型获得当前的速度、位置真实值(实际应用中不需要)
real_v = v0 + a * i;
real_pos = s0 + (v0 + real_v) * i / 2
real_positions[i] = real_pos
# 模拟输入数据,实际应用中从传感器测量获得
v = real_v + np.random.normal(0,v_var**0.5)
measure_positions[i] = real_pos + np.random.normal(0,m_var**0.5)
# 如果仅使用运动模型来预测整个轨迹,而不使用观测值,则得到的位置如下
predict_positions[i] = predict_positions[i-1] + (v + v + a) * (i - (i - 1))/2
# 以下是卡尔曼滤波的整个过程
# 根据实际模型预测,利用上个时刻的位置(上一时刻的最优估计值)和速度预测当前位置
pos_k_pred = pos_k_1 + v + a/2
# 更新预测数据的方差
predict_var += v_var
# 求得最优估计值
pos_k = pos_k_pred * m_var/(predict_var + m_var) + measure_positions[i] * predict_var/(predict_var + m_var)
# 更新
predict_var = (predict_var * m_var)/(predict_var + m_var)
pos_k_1 = pos_k
optim_positions[i] = pos_k
plt.plot(t,real_positions,label='real positions')
plt.plot(t,measure_positions,label='measured positions')
plt.plot(t,optim_positions,label='kalman filtered positions')
# 预测噪声比测量噪声低,但是运动模型预测值比观测值差很多,原因是在于运动模型是基于前一刻预测结果进行下一次的预测,而测量噪声是基于当前位置给出的测量结果
# 意思就是,运动模型会积累噪声,而观测结果只是单次噪声
plt.plot(t,predict_positions,label='predicted positions')
plt.legend()
plt.show()参考
参考链接1:https://blog.csdn.net/weixin_43849505/article/details/121947413
参考链接2:https://zhuanlan.zhihu.com/p/649997859
参考链接3:https://www.bilibili.com/video/BV1fV4y1f7j6?p=7
参考书籍:《视觉SLAM十四讲-第二版》
















 2529
2529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









