







@朴素贝叶斯算法Python复现(基于iris数据集)TOC
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本节主要讲的是朴素贝叶斯算法以及相应的Python复现(基于iris的数据集)。本段代码没有进行K折交叉验证,希望有需要的读者可以自行添加,如果对其他数据集有分类情况偏低,可以考虑添加一下拉普拉斯修正,或者对数据进行归一化处理。
接下来,对朴素贝叶斯定理做一个简单的介绍,如果需要了解详细内容可以找相关资料进行学习
一、朴素贝叶斯分类器
1.贝叶斯分类 :是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本文作为分类算法的第一篇,将首先介绍分类问题,对分类问题进行一个正式的定义。然后,介绍贝叶斯分类算法的基础——贝叶斯定理。最后,通过实例讨论贝叶斯分类中最简单的一种:朴素贝叶斯分类。
2.朴素贝叶斯定理:
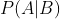
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率
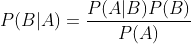
3.拉普拉斯修正:
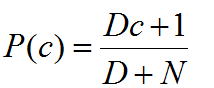
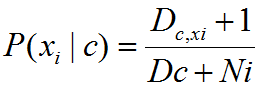
拉普拉斯修正:为了避免其他属性携带的信息被训练集中未出现的属性抹去,在估计概率值时通常要进行smoothing,常使用拉普拉斯修正。具体来说,令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值数。
接下来是我的一些学习笔记,提供参考:

三、朴素贝叶斯分类器python代码
1.引入库
pandas:exce表数据集的读取
shuffle:数据集打乱顺序
exp:自然指数e
import pandas as pd
import numpy as np
from math import pi
from numpy import exp
from sklearn.utils import shuffle
2.读取数据集并根据标签值分类
此处主要是将不同属性的三个标签用字典进行分类
返回的每一个dict都是3个标签的同一个属性的数据
fpath = r'd:iris.xls'
object = pd.read_excel(fpath)
object = shuffle(object)
list = []
dict1 = {
}
dict2 = {
}
dict3 = {
}
dict4 = {
}
i1 = object.iloc[100:150,0:5]
test_set = i1.values.tolist()#测试集
#.....................................................................................
m1 = object.iloc[0:100, [0, 4]]
m2 = m1.values.tolist()
for j in m2:
if j[1] not in dict1:
dict1[j[1]] = [j[0]]
else:
dict1[j[1]].append(j[0])
print(dict1)
m1 = object.iloc[0:100, [1, 4]]
m2 = m1.values.tolist()
for j in m2:
if j[1] not in dict2:
dict2[j[1]] = [j[0]]
else:
dict2[j[1]].append(j[0])
m1 = object.iloc[0:100, [2, 4]]
m2 = m1.values.tolist()
for j in m2:
if j[1] not in dict3:
dict3[j[1]] = [j[0]]
else:
dict3[j[1]].append(j[0])
m1 = object.iloc[0:100, [3, 4]]
m2 = m1.values.tolist()
for j in m2:
if j[1] not in dict4:
dict4[j[1]] = [j[0]]
else:
dict4[j[1]].append(j[0])
return dict1,dict2,dict3,dict4,test_set

这个是第一个属性分类后dict1相应的返回值,test_set是测试集的数据集合。
3.定义均值和方差
输入的per_dataset是每一个数据的数据
def average_variance 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6443
6443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











