







鉴于这个机器学习在课上就没咋听明白过,自己慢慢啃吧。。。内容来自西瓜书和学校课件。
文章目录
决策树概述
- 可以处理分类问题也可以处理回归问题;分类问题看比例、回归问题看均值。
- 目的是找到泛化能力强即处理未见示例能力强的模型。
信息增益&信息熵
信息熵
- 信息熵:公式:− ∑ 𝑃𝑖 × 𝑙𝑜𝑔2𝑃𝑖 (𝑖 = 1,2, … , 𝑛)
𝑃𝑖 是整个数据集中 𝑖 出现的概率(频率) - 信息熵的值越小,证明数据集的纯度越高。因为熵即是表示随机变量不确定性的度量。
信息增益
- 信息增益:针对整个数据集里的不同划分种类计算出来的熵。
- 示例:
| ¥ | 正例 | 负例 | 合计 |
|---|---|---|---|
| 全样本 | 6 | 9 | 15 |
| 喜欢A | 5 | 2 | 7 |
| 喜欢B | 4 | 4 | 8 |
此时,
整体的信息熵为E(T):
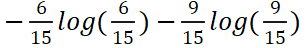
喜欢A的信息熵为E(TA):
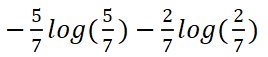
喜欢B的信息熵为E(TB):
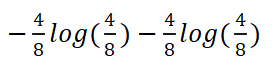
喜欢A/B这个属性的信息增益为:
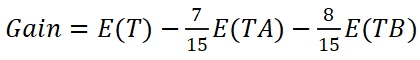
- 一般信息增益越大,意味着使用属性来划分所获得的“纯度提升”越大。
基尼指数 Gini index

- 示例:
| ¥ | 正例 | 负例 | 合计 |
|---|---|---|---|
| 全样本 | 6 | 9 | 15 |
| 喜欢A | 5 | 2 | 7 |
| 喜欢B | 4 | 4 | 8 |
Gini = (7/15) * (1 - (5/7)^2 - (2/7)^2) + (8/15) * (1 - (4/8)^2 - (4/8)^2)
剪枝处理 pruning
- 决策树用来“过拟合”的主要手段。
预剪枝 prepruning
- 生成决策树,对每个结点在划分前进行估计,若这次划分不能带来决策树的泛化能力提高,则将这个结点作为叶节点、终止划分。
- 目的:限制深度(其实就是使用的变量个数),叶子节点个数、叶子节点样本数,信息增益量等
后剪枝 postpruning
- 先从训练集生成一颗完整的决策树,再自底向上对非叶节点进行考察,若将某属性的下分支改成叶节点会提高决策树的泛化能力,即替换。


连续值和缺失值
连续值
- 连续值不能按照取值分类,所以可以基于划分点 t 将数据集分为Dt- (数据集中小于 t )和 Dt+(数据集中大于 t )。

- 示例:如[60,70,76,80,82,87,89,90,96,99]
如果用二分法,则有10个分界点,所以可以按照 >85 和 <=85 分割。
缺失值
- 数据集中某属性的数据如若因为有缺失值就不使用实属浪费,所以把该属性的非缺失值保留进行处理。


示例步骤:
比如数据集中共有20个值,但非缺失值只有15个。分为ABCD四类。现计算该属性的信息增益。
1)首先求出全属性的信息熵:
Ent = - 正例比例 × 𝑙𝑜𝑔2正例比例 - 负例比例 × 𝑙𝑜𝑔2负例比例
2)求出ABCD四类的信息熵:
Ent(A) = - A正例比例 × 𝑙𝑜𝑔2A正例比例 - A负例比例 × 𝑙𝑜𝑔2A负例比例
BCD类似如上。
3)求非缺失值子集的信息增益:
Gain(子集.属性) = Ent - (Ent( A )+Ent( B )+Ent( C )+Ent( D ))
4)样本集上该属性的信息增益:
Gain(数据集.属性) = 15/20 * Gain(子集.属性)
即,在子集的信息增益上乘以非缺失值/总值的比例。
5)后续:上述过程得出的各个属性的信息增益,取最大信息增益的属性作为决策树的根节点进行划分
6)样本集上该属性的信息增益: 该属性中的缺失值该进入哪个分类呢?
这个该属性缺失值的样本会进入到这个属性的所有分支里,但权重要有所调整,按照各分支占总非缺失值的比例作为权重。
多变量决策树
- 每个非叶节点都是一个线性分类器,不再只针对某个属性,而是对属性的线性组合进行测试。

ID3决策树
- 信息增益作为划分属性的标准。
- 从根节点开始,对节点的所有属性计算其信息增益,选择信息增益最大的属性作为节点的特征,由该属性的不同类别建立子节点;直到所有属性的信息增益均很小或没有属性可以选择为止。
C4.5算法
- 采用二分法(bi-partition)对连续属性进行处理。
- 采用增益率作为划分属性的标准。
- 信息增益率:信息增益 / 内在信息;内在信息即是每个属性的信息熵。
- 不是直接选择增益率最大的侯选属性做划分,而是先从划分属性中找出信息增益高出平均信息增益的属性,再从中找出增益率最高的。
示例:
| A | B | 正负例 |
|---|---|---|
| 喜欢 | 黑 | 正例 |
| 喜欢 | 白 | 正例 |
| 不喜欢 | 红 | 正例 |
| 喜欢 | 黑 | 正例 |
| 不喜欢 | 白 | 正例 |
| 喜欢 | 红 | 负例 |
| 不喜欢 | 黑 | 负例 |
| 喜欢 | 红 | 负例 |
| 不喜欢 | 白 | 负例 |
1)获得总信息熵:
Ent = - 正例比例 × 𝑙𝑜𝑔2正例比例 - 负例比例 × 𝑙𝑜𝑔2负例比例
2)获得各属性信息熵:
Ent(A) = - A中正例比例 × 𝑙𝑜𝑔2A中正例比例 - A负例比例 × 𝑙𝑜𝑔2A中负例比例
Ent(B) = - B中正例比例 × 𝑙𝑜𝑔2B中正例比例 - B负例比例 × 𝑙𝑜𝑔2B中负例比例
3)获得各属性信息增益:
Gain(A) = Ent - Ent(A)
Gain(B) = Ent - Ent(B)
4)获得各属性熵:
H(A) = - 喜欢比例 × 𝑙𝑜𝑔2喜欢比例 - 不喜欢比例 × 𝑙𝑜𝑔2不喜欢比例
H(B) = - 黑色比例 × 𝑙𝑜𝑔2黑色比例 - 白色比例 × 𝑙𝑜𝑔2白色比例- 红色比例 × 𝑙𝑜𝑔2红色比例
5)计算信息增益率
IGR(A) = Gain(A) / H(A)
IGR(B) = Gain(B) / H(B)
6)选择节点
哪个属性的信息增益率最高,选择该属性为分裂属性。分裂之后,选择不“纯”的结点继续分裂;若子结点都是纯的,因此子节点均为叶子节点,分裂结束。
CART
- 采用Gini指标作为划分属性的标准。
- 由于CART是做二分类问题的,所以Gini( p ) = 2p(1-p)
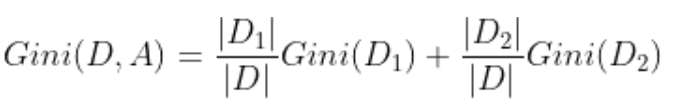
示例:
| A | B | 正负例 |
|---|---|---|
| 喜欢 | 黑 | 正例 |
| 喜欢 | 白 | 正例 |
| 不喜欢 | 红 | 正例 |
| 喜欢 | 黑 | 正例 |
| 不喜欢 | 白 | 正例 |
| 喜欢 | 红 | 负例 |
| 不喜欢 | 黑 | 负例 |
| 喜欢 | 红 | 负例 |
| 不喜欢 | 白 | 负例 |
以颜色为例,为了方便书写将颜色中各类别进行赋值,其中黑为1、白为2、红为3。
Gini(D,B=1) = ?
1)黑色的个数为3个,非黑色的个数为6个
2)黑色中正例的个数为2个,负例的个数为1个;非黑色中正例的个数为3个,负例的个数为3个
3)Gini(D,B=1) = 3/9 * [2 * 2/3 * (1- 2/3)] + 6/9 * [2 * 3/6 * (1- 3/6)]
此时,选取基尼系数最小的属性点作为切分点进行决策树的划分。
进行这个最佳属性点的寻找和切分直至
1)结点中的样本个数小于预定阈值,或
2)样本集的基尼指数小于预定阈值、如样本基本属于同一类,如完全属于同一类则为0,或
3)特征集为空。















 4814
4814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









