






一、实验内容
本实验将帮助您了解缓存对C程序性能的影响。实验由两部分组成。在第一部分中,您将编写一个模拟高速缓存行为的小型C程序(大约200-300行)。在第二部分中,您将优化一个小的矩阵转置函数,目标是最小化缓存未命中的数量。
二、实验要求
第一部分:
第一部分中,您将编辑csim.c文件,实现一个缓存模拟器。它以valgrind的内存引用轨迹文件作为输入,模拟缓存的命中和未命中行为,并输出命中、未命中和逐出的数量。
我们为您提供了一个名为csim-ref的标准的缓存模拟器的二进制可执行文件,该模拟器模拟具有任意大小和相联度的缓存的行为。在选择要逐出的缓存行时,它使用LRU替换策略,这个参考模拟器就是标准答案,它可以接收以下命令行参数:
./csim-ref [-hv] -s <s> -E <E> -b <b> -t <tracefile>
-h: 可选参数,用于输出使用帮助
-v:可选参数,用于输出跟踪信息的详细内容
-s <s>:设置组索引位的数量(组数量S=2s)
-E <E>:设置每组的行数
-b <b>:设置块大小(块大小B=2b位)
-t <tracefile>:要跟踪的内存引用轨迹文件的名称
第一部分的工作是要编辑csim.c文件,以使它使用与csim-ref相同的命令行参数和产生与它相同的输出。请注意,拿到手上的csim.c几乎完全为空,你需要从头开始写。
第一部分的注意事项:
- 你的csim.c文件必须在没有警告的情况下通过编译才能获得分数。
- 你的模拟器必须在任意的s、E和b下都能正常工作。这意味着你需要使用malloc函数为模拟器的数据结构分配空间。malloc函数的使用方法自己百度。
- 对于这个实验中,我们只对数据缓存性能感兴趣,所以您的模拟器应该忽略所有指令缓存访问(以“I”开头的行)。“I”总是顶格的,它前面没有空格,而“M”、“L”和“S”前面有空格,可以根据这一点来区分。
- 要获得第一部分的分数,必须在main()函数结束前调用函数printsummmary()来输出命中、未命中和驱逐的数量。
- 对于这部分,您应该假设内存访问已正确对齐,因此内存访问永远不会跨越块边界。通过这个假设,你可以忽略在内存访问轨迹文件中的“大小”字段。
第二部分:
在第二部分中,你将编辑trans.c文件实现一个转置函数,目标是使得在程序运行过程中尽可能少的发生缓存未命中。
如果A表示一个矩阵,则矩阵A的转置矩阵为AT,它们之间的关系为:Aij=ATji
为了帮助您编程,我们在trans.c中为您提供转置函数示例,该示例计算N×M矩阵A的转置,并将结果存储在M×N矩阵B中。该示例的转置函数是正确的,但它效率低下,因为访问模式导致许多缓存未命中。
在第二部分中,您的工作是编写一个类似的函数,称为transpose_submit,以缓存未命中最少化的方式实现矩阵转置。
第二部分注意事项:
- 你的trans.c文件必须在没有警告的情况下通过编译才能获得分数。
- 每个转置函数最多可以定义12个int类型的局部变量。
- 不允许通过使用long类型的变量或使用位技巧将多个值存储到单个变量这种手段来规避2)中的限制。
- 转置函数不能使用递归。
- 如果使用函数调用,在被调用函数和顶层转置函数之间的栈空间上的局部变量不得超过12个。例如,如果你的转置函数声明8个变量,然后在转置函数里调用了一个使用4个变量的函数,该函数再调用另一个包含2个局部变量的函数,则栈空间上将有14个变量,这将违反规则。
- 您的转置函数不能修改数组A,但是您可以修改数组B。
- 不允许在代码中定义任何数组或使用malloc之类的函数。
三、实验步骤
一、准备步骤
1.安装valgrind,在终端命令行中运行指令“sudo apt-get install valgrind”
2.安装Python2.7,在终端命令行中运行指令“sudo apt-get install python”
3.将“cachelab-handout.tar”文件拷贝到虚拟机的某文件夹里面并在该文件夹里打开终端使用命令 “tar xvf cachelab-handout.tar”进行解压

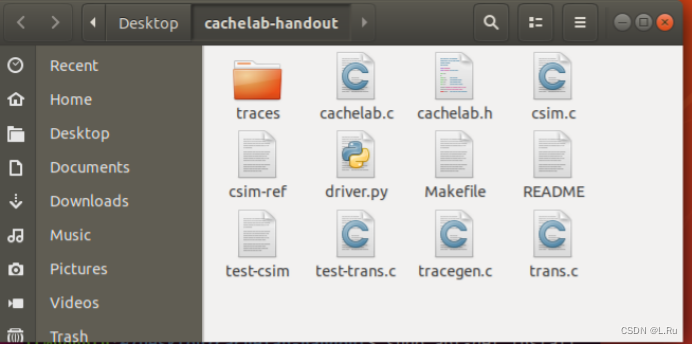
文件说明:
csim.c:实现缓存模拟器的文件
trans.c:实现矩阵转置的文件
csim-ref:标准的缓存模拟器
csim:由你实现的模拟器可执行程序
tracegen:测试你的矩阵转置是否正确,并给出错误信息
test-trans:测试你的矩阵转置优化的如何,并给出评分
part1 编写缓存模拟器
1、编辑cachelab-handout/csim.c文件,实现缓存模拟器。在csim.c文件中编写一个使用LRU策略的 cache 模拟器,里面进行验证的命令就存在traces文件夹里,随便打开一个可以看到其中的样子是这样:
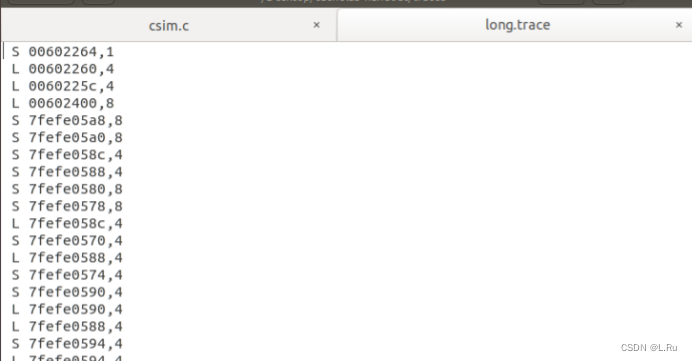
注意:我们碰到I开头的命令,直接跳过,使用continue
LRU策略:即被替换掉的块其最后的访问时间是距离现在最远的,体现在代码里可以设置一个时间戳,完成一次操作然后递增,替换的时候比大小就可以了。
每个数据加载(L)或存储(S)操作最多可导致一次缓存未命中。数据修改操作(M)被视为加载然后存储到同一地址。因此,M操作可能导致两次缓存命中,或者一次未命中再加上一次可能的驱逐。
最终的csim.c文件:
#include "cachelab.h"
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <limits.h>
#include <getopt.h>
#include <string.h>
int h,v,s,E,b,S; // 这个是我们模拟的参数,为了方便在函数里调用,设置成全局
int hit_count ,
miss_count ,
eviction_count; // 三个在 printSummary 函数中的参数,需要不断更新
char t[1000]; // 存 getopt 中选项内容,表示的是验证中需使用的trace文件名
typedef struct{
int valid_bits;
int tag;
int stamp;
}cache_line, *cache_asso, **cache; // cache 模拟器的结构。由合法位、标记位和时间戳组成
cache _cache_ = NULL; // 声明一个空的结构体类型二维数组
// 打印 helper 内容的函数,-h 命令使用
void printUsage()
{
printf("Usage: ./csim-ref [-hv] -s <num> -E <num> -b <num> -t <file>\n"
"Options:\n"
" -h Print this help message.\n"
" -v Optional verbose flag.\n"
" -s <num> Number of set index bits.\n"
" -E <num> Number of lines per set.\n"
" -b <num> Number of block offset bits.\n"
" -t <file> Trace file.\n\n"
"Examples:\n"
" linux> ./csim-ref -s 4 -E 1 -b 4 -t traces/yi.trace\n"
" linux> ./csim-ref -v -s 8 -E 2 -b 4 -t traces/yi.trace\n");
}
// 初始化cache的函数
void init_cache()
{
//多维数组的开辟要一行行malloc
_cache_ = (cache)malloc(sizeof(cache_asso) * S);
for(int i = 0; i < S; ++i)
{
_cache_[i] = (cache_asso)malloc(sizeof(cache_line) * E);
for(int j = 0; j < E; ++j)
{
_cache_[i][j].valid_bits = 0;
_cache_[i][j].tag = -1;
_cache_[i][j].stamp = -1;
}
}
}
void update(unsigned int address)
{
// 索引地址位可以用位运算,-1U是最大整数,64是因为我电脑是64位
int setindex_add = (address >> b) & ((-1U) >> (64 - s));
int tag_add = address >> (b + s);
int max_stamp = INT_MIN;
int max_stamp_index = -1;
for(int i = 0; i < E; ++i) //如果tag相同,就重置时间戳
{
if(_cache_[setindex_add][i].tag == tag_add)
{
_cache_[setindex_add][i].stamp = 0;
++hit_count;
return ;
}
}
for(int i = 0; i < E; ++i) // 查看有没有空行
{
if(_cache_[setindex_add][i].valid_bits == 0)
{
_cache_[setindex_add][i].valid_bits = 1;
_cache_[setindex_add][i].tag = tag_add;
_cache_[setindex_add][i].stamp = 0;
++miss_count;
return ;
}
}
// 没有空行又没有hit就是要替换了
++eviction_count;
++miss_count;
for(int i = 0; i < E; ++i)
{
if(_cache_[setindex_add][i].stamp > max_stamp)
{
max_stamp = _cache_[setindex_add][i].stamp;
max_stamp_index = i;
}
}
_cache_[setindex_add][max_stamp_index].tag = tag_add;
_cache_[setindex_add][max_stamp_index].stamp = 0;
return ;
}
void update_stamp()
{
for(int i = 0; i < S; ++i)
for(int j = 0; j < E; ++j)
if(_cache_[i][j].valid_bits == 1)
++_cache_[i][j].stamp;
}
void parse_trace()
{
FILE* fp = fopen(t, "r"); // 读取文件名
if(fp == NULL)
{
printf("open error");
exit(-1);
}
char operation; // 命令开头的 I L M S
unsigned int address; // 地址参数
int size; // 大小
while(fscanf(fp, " %c %xu,%d\n", &operation, &address, &size) > 0)
{
switch(operation)
{
//case 'I': continue; // 不用写关于 I 的判断也可以
case 'L':
update(address);
break;
case 'M':
update(address); // miss的话还要进行一次storage
case 'S':
update(address);
}
update_stamp(); //更新时间戳
}
fclose(fp);
for(int i = 0; i < S; ++i)
free(_cache_[i]);
free(_cache_); // malloc 完要记得 free 并且关文件
}
int main(int argc, char* argv[])
{
h = 0;
v = 0;
hit_count = miss_count = eviction_count = 0;
int opt; // 接收getopt的返回值
// getopt 第三个参数中,不可省略的选项字符后要跟冒号,这里h和v可省略
while(-1 != (opt = (getopt(argc, argv, "hvs:E:b:t:"))))
{
switch(opt)
{
case 'h':
h = 1;
printUsage();
break;
case 'v':
v = 1;
printUsage();
break;
case 's':
s = atoi(optarg);
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
strcpy(t, optarg);
break;
default:
printUsage();
break;
}
}
if(s<=0 || E<=0 || b<=0 || t==NULL) // 如果选项参数不合格就退出
return -1;
S = 1 << s; // S=2^s
FILE* fp = fopen(t, "r");
if(fp == NULL)
{
printf("open error");
exit(-1);
}
init_cache(); // 初始化cache
parse_trace(); // 更新最终的三个参数
printSummary(hit_count, miss_count, eviction_count);
//调用函数printSummmary()来输出命中、未命中和驱逐的数量
return 0;
}编写完代码后:在cachelab-handout/路径下打开终端并执行“make clean”、“make”这两条指令对程序进行编译:
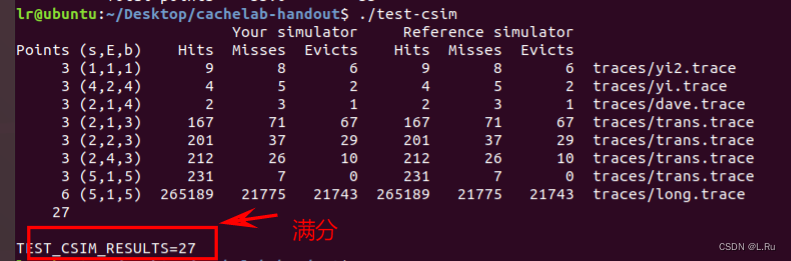
然后,运行指令“./test-csim”对自己所实现的缓存模拟器进行评分。
part2 实现矩阵转置
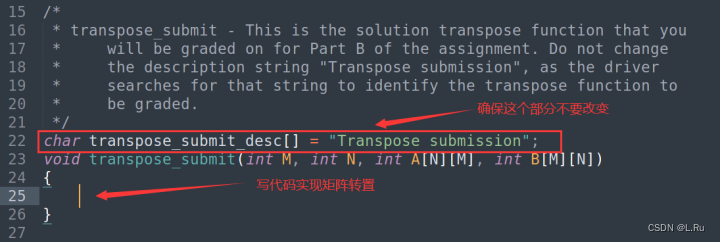
打开cachelab-handout/trans.c文件,找到transpose_submit函数,在该函数体内实现矩阵转置功能。
缓存采用的是直接映射高速缓存,s = 5,b = 5,E = 1。对于该缓存,总共存在32个组,每个组共32个字节,可以装入8个int型变量,是非常有限的缓存,矩阵大小>cache大小。主要需要解决以下两个问题:
直接映射缓存所带来的冲突不命中。观察程序中矩阵存储的位置即可以发现,矩阵A和矩阵B的同一行实际上被映射到了同一个缓存组。当进行对角线的引用时,一定会发生缓存的冲突不命中。需要仔细地处理对角线上的元素。
所需优化的矩阵的总大小超出了缓存的总大小。必然导致程序的访存效率低下。
为了解决第一个问题,我们需要仔细地考虑对于矩阵访问顺序;第二个问题,采用矩阵的分块(Blocking)方法降低miss
一、32*32
第一个测试矩阵大小是 32 x 32 的。我们先来分析一下,一个 int 类型数字是 4 字节,cache 中一行 32 字节,可以放 8 个 int 。通过使用分块技术,我们 cache 一行能放 8 个,所以我们分块最好也能用 8 的倍数。然后对于非对角线上的块,本身就没有额外的冲突;对于对角线上的块,写入A每一行的第一个元素后,这一行的元素都进入了缓存,我们就立即用本地变量存下这 8 个元素,随后再复制给B。这样,就避免了第一个元素复制时,B把A的缓冲行驱逐,导致没有利用上A的缓冲。
代码实现
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, k, l, a0, a1, a2, a3, a4, a5, a6, a7;
if(M == 32){
//一个 int 类型数字是 4 字节,cache 中一行 32 字节,可以放 8 个 int 。通过使用分块技术,我们 cache 一行能放 8 个,所以我们分块最好也能用 8 的倍数。
for (i = 0; i < N; i+=8) { //枚举每八行
for (j = 0; j < M; j+=8) { // 枚举每八列
if(i == j){
for(k = i ;k < i + 8 && k<N;k++){ // 枚举0~8中的每一行,一行八列
a0 = A[k][j]; // 这八个只会发生一次miss
a1 = A[k][j+1];
a2 = A[k][j+2];
a3 = A[k][j+3];
a4 = A[k][j+4];
a5 = A[k][j+5];
a6 = A[k][j+6];
a7 = A[k][j+7];
B[j][k] = a0; //第一次 这八个都会 miss,后面就会命中,当然对角线有些例外
B[j+1][k] = a1;
B[j+2][k] = a2;
B[j+3][k] = a3;
B[j+4][k] = a4;
B[j+5][k] = a5;
B[j+6][k] = a6;
B[j+7][k] = a7;
}
}
else{
for(k = i ;k < i + 8 && k<N;k++){
for(l = j ; l < j + 8 && l < M;l++)
B[l][k] = A[k][l];
}
}
}
}
}为了保证程序的正确性和可靠性。每次评分前先执行“make clean”和“make”指令对代码进行重新编译
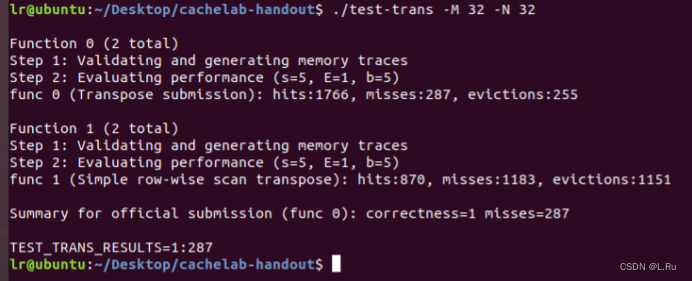
然后执行./test-trans -M 32 -N 32
二、64*64
数组一行有64个int,即8个block,所以每四行就会填满一个cache,即两个元素相差四行就会发生冲突。
else if(M == 64){
for (i = 0; i < N; i += 8) { // 枚举每八行
for (j = 0; j < M; j += 8) { // 枚举每八列
for (k = i; k < i + 4; k++) {
a0 = A[k][j];
a1 = A[k][j + 1];
a2 = A[k][j + 2];
a3 = A[k][j + 3];
a4 = A[k][j + 4];
a5 = A[k][j + 5];
a6 = A[k][j + 6];
a7 = A[k][j + 7];
B[j][k] = a0;
B[j + 1][k] = a1;
B[j + 2][k] = a2;
B[j + 3][k] = a3;
B[j][k + 4] = a4;
B[j + 1][k + 4] = a5;
B[j + 2][k + 4] = a6;
B[j + 3][k + 4] = a7;
}
for (l = j + 4; l < j + 8; l++) {
a4 = A[i + 4][l - 4]; // A left-down col
a5 = A[i + 5][l - 4];
a6 = A[i + 6][l - 4];
a7 = A[i + 7][l - 4];
a0 = B[l - 4][i + 4]; // B right-above line
a1 = B[l - 4][i + 5];
a2 = B[l - 4][i + 6];
a3 = B[l - 4][i + 7];
B[l - 4][i + 4] = a4; // set B right-above line
B[l - 4][i + 5] = a5;
B[l - 4][i + 6] = a6;
B[l - 4][i + 7] = a7;
B[l][i] = a0; // set B left-down line
B[l][i + 1] = a1;
B[l][i + 2] = a2;
B[l][i + 3] = a3;
B[l][i + 4] = A[i + 4][l];
B[l][i + 5] = A[i + 5][l];
B[l][i + 6] = A[i + 6][l];
B[l][i + 7] = A[i + 7][l];
}
}
}
} 为了保证程序的正确性和可靠性。每次评分前先执行“make clean”和“make”指令对代码进行重新编译
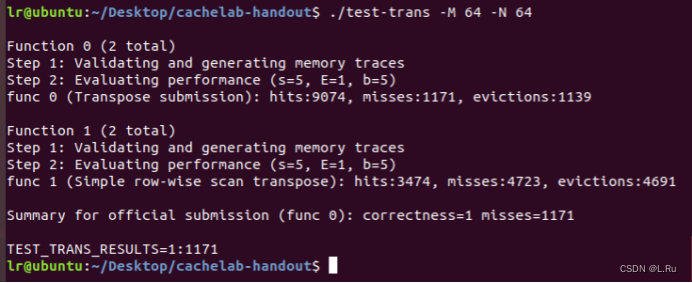
然后执行./test-trans -M 64 -N 64
三、61*67
用8分块去稍微对对角线做下操作,因为 32 x 32 最小的 miss 的方法和这边是一样的,而且写起来太多了,我们就用最简单的存变量的方式去做。
else if(M == 61)
{
int i, j, v1, v2, v3, v4, v5, v6, v7, v8;
int n = N / 8 * 8;
int m = M / 8 * 8;
for (j = 0; j < m; j += 8)
for (i = 0; i < n; ++i)
{
v1 = A[i][j];
v2 = A[i][j+1];
v3 = A[i][j+2];
v4 = A[i][j+3];
v5 = A[i][j+4];
v6 = A[i][j+5];
v7 = A[i][j+6];
v8 = A[i][j+7];
B[j][i] = v1;
B[j+1][i] = v2;
B[j+2][i] = v3;
B[j+3][i] = v4;
B[j+4][i] = v5;
B[j+5][i] = v6;
B[j+6][i] = v7;
B[j+7][i] = v8;
}
for (i = n; i < N; ++i)
for (j = m; j < M; ++j)
{
v1 = A[i][j];
B[j][i] = v1;
}
for (i = 0; i < N; ++i)
for (j = m; j < M; ++j)
{
v1 = A[i][j];
B[j][i] = v1;
}
for (i = n; i < N; ++i)
for (j = 0; j < M; ++j)
{
v1 = A[i][j];
B[j][i] = v1;
}
}为了保证程序的正确性和可靠性。每次评分前先执行“make clean”和“make”指令对代码进行重新编译
然后执行./test-trans -M 61 -N 67
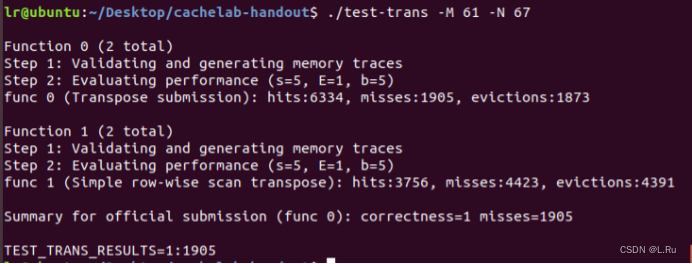
注意:未命中数量会有不同的要求,规则如下:
32 × 32: 满分8 分 if 未命中 < 300, 0 points if 未命中 > 600
64 × 64: 满分8 分 if 未命中 < 1, 300, 0 points if 未命中 > 2, 000
61 × 67: 满分10 分 if 命中 < 2, 000, 0 points if 未命中 > 3, 000
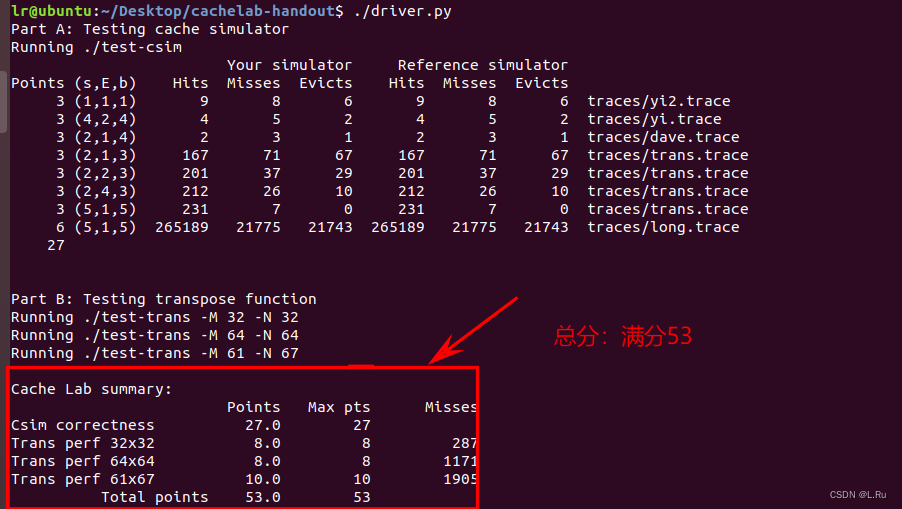
最后利用总分数的自动评分
在cachelab-handout/路径下打开终端并执行指令“./driver.py”进行自动总分评分。















 3158
3158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









