










题目一:二叉树的遍历
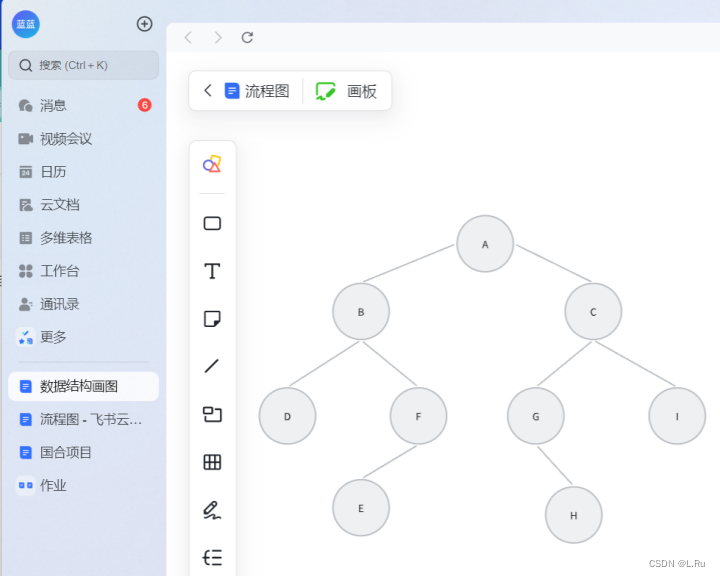
- 本题要求实现给定二叉树的4种遍历(如下图)。
要求4个函数分别按照访问顺序打印出结点的内容,格式为一个空格跟着一个字符。
输出样例(对于图中给出的树):

Inorder: D B E F A G H C I
Preorder: A B D F E C G H I
Postorder: D E F B H G I C A
Levelorder: A B C D F G I E H
解题思路:
图解:

代码实现:
import java.util.Scanner;
//二叉树节点类
class TreeNode {
char val;
TreeNode left;
TreeNode right;
public TreeNode(char val) {
this.val = val;
}
}
public class Main {
static int index = 0;
//创建二叉树
public static TreeNode createBinaryTree(String firstOrder) {
if (firstOrder.charAt(index) == '#' || index>= firstOrder.length()){
index++;
return null;
}
TreeNode root = new TreeNode(firstOrder.charAt(index++));
root.left = createBinaryTree(firstOrder);
root.right = createBinaryTree(firstOrder);
return root;
}
//先序
public static void preOrder(TreeNode root) {
if (root!=null){
System.out.print(root.val);
preOrder(root.left);
preOrder(root.right);
}
}
//中序
public static void inOrder(TreeNode root) {
if (root == null){
return;
}
inOrder(root.left);
System.out.print(root.val);
inOrder(root.right);
}
//后序
public static void postOrder(TreeNode root) {
if (root == null){
return;
}
postOrder(root.left);
postOrder(root.right);
System.out.print(root.val);
}
//深度
public static int getDepth(TreeNode root) {
if (root==null){
return 0;
}
int leftDepth = getDepth(root.left);
int rightDepth = getDepth(root.right);
return Math.max(leftDepth, rightDepth)+1;
}
//叶子节点个数
public static int countLeaves(TreeNode root) {
if (root == null)
return 0;
if (root.left == null && root.right == null)
return 1;
return countLeaves(root.left) + countLeaves(root.right);
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String firstOrder = sc.nextLine();
sc.close();
TreeNode root = createBinaryTree(firstOrder);
System.out.print("PreOrder:");
preOrder(root);
System.out.println();
System.out.print("InOrder:");
inOrder(root);
System.out.println();
System.out.print("PostOrder:");
postOrder(root);
System.out.println();
System.out.println("Depth:" + getDepth(root));
System.out.println("Leaf:" + countLeaves(root));
}
}
运行结果
题目二:是否同一棵二叉搜索树
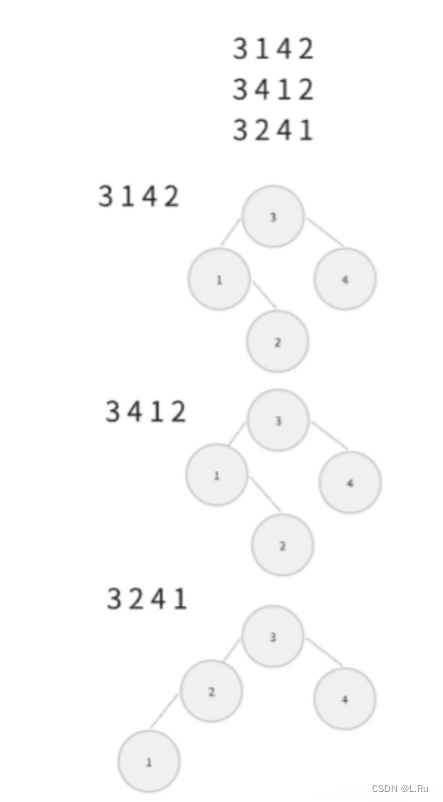
给定一个插入序列就可以唯一确定一棵二叉搜索树。然而,一棵给定的二叉搜索树却可以由多种不同的插入序列得到。例如分别按照序列{2, 1, 3}和{2, 3, 1}插入初始为空的二叉搜索树,都得到一样的结果。于是对于输入的各种插入序列,你需要判断它们是否能生成一样的二叉搜索树。
输入格式:
输入包含若干组测试数据。每组数据的第1行给出两个正整数N (≤10)和L,分别是每个序列插入元素的个数和需要检查的序列个数。第2行给出N个以空格分隔的正整数,作为初始插入序列。最后L行,每行给出N个插入的元素,属于L个需要检查的序列。
简单起见,我们保证每个插入序列都是1到N的一个排列。当读到N为0时,标志输入结束,这组数据不要处理。
输出格式:
对每一组需要检查的序列,如果其生成的二叉搜索树跟对应的初始序列生成的一样,输出“Yes”,否则输出“No”。
输入样例:
4 2
3 1 4 2
3 4 1 2
3 2 4 1
2 1
2 1
1 2
0
输出样例:
Yes
No
No
解题思路:
图解:
代码实现:
import java.io.BufferedReader; // 导入BufferedReader类,用于读取文本文件
import java.io.FileDescriptor; // 导入FileDescriptor类,用于表示文件描述符
import java.io.FileReader; // 导入FileReader类,用于读取文件
public class Main {
public static void main(String[] args){
// 创建Main类的实例
Main self = new Main();
// 创建BufferedReader对象,用于读取标准输入
BufferedReader br = new BufferedReader(new FileReader(FileDescriptor.in));
try {
// 调用readInput方法读取输入
self.readInput(br);
} catch (Exception e) {
// 如果发生异常,打印异常堆栈
e.printStackTrace();
}
}
// 定义readInput方法,用于读取输入并处理数据
public void readInput(BufferedReader br) throws Exception{
String s = "";
while ((s = br.readLine()) != null){
// 使用空格分割字符串,得到字符串数组
String[] strs = s.split(" ");
// 如果输入只有一个数字0,则退出循环
if(strs.length==1 && Integer.parseInt(strs[0])==0){
break;
}
// 如果不是0,继续读取所需的数据
int nodeNum = Integer.parseInt(strs[0]); // 读取节点数量
int lines = Integer.parseInt(strs[1]); // 读取将要处理的行数
String ordinary = br.readLine(); // 读取树的序列
Node2 head = getTree(ordinary); // 根据序列创建树
// 对每一行输入进行处理
for (int i = 0; i < lines; i++) {
String temp = br.readLine(); // 读取将要检查的序列
boolean res = isSameTree(temp, head); // 检查序列是否与树相同
if (res){
System.out.println("Yes"); // 如果相同,打印"Yes"
}else{
System.out.println("No"); // 如果不同,打印"No"
}
reset(head); // 重置树的标记
}
}
}
// 根据给定序列创建一棵树
public Node2 getTree(String str){
String[] s = str.trim().split(" "); // 分割字符串,去除空白字符
Node2 head = new Node2(Integer.parseInt(s[0])); // 创建根节点
// 遍历数组,插入剩余的节点
for (int i = 1; i < s.length; i++) {
insertNode(head,Integer.parseInt(s[i]));
}
return head; // 返回树的根节点
}
// 插入节点的方法
private Node2 insertNode(Node2 head, int val){
if (head == null){
return new Node2(val); // 如果头节点为空,创建新节点
}else {
// 根据值比较,将新节点插入到二叉搜索树的适当位置
if (head.data > val)
head.left = insertNode(head.left,val);
else
head.right = insertNode(head.right,val);
}
return head; // 返回更新后的头节点
}
// 测试一个插入序列与另一颗树是否是同一颗树
public boolean isSameTree(String str, Node2 head){
String[] s = str.trim().split(" "); // 分割字符串,去除空白字符
// 遍历序列,检查每个节点是否存在于树中
for (int i = 0; i < s.length; i++) {
int temp = Integer.parseInt(s[i]);
// 如果序列中的节点在树中不存在,则返回false
if(!checkNodeHasVisit(temp,head)){
return false;
}
}
return true; // 如果所有节点都存在,返回true
}
// 检查节点是否已经访问过
private boolean checkNodeHasVisit(int num, Node2 head){
if (head.flag == 0){ // 如果节点未访问过
if (num == head.data){ // 如果节点值匹配
head.flag = 1; // 标记为已访问
return true;
}else {
return false; // 如果节点值不匹配,返回false
}
}else {
// 如果节点已访问过,根据节点值继续在左或右子树中查找
if (num < head.data){
return checkNodeHasVisit(num, head.left);
}else if(num > head.data){
return checkNodeHasVisit(num,head.right);
}else {
return false; // 如果节点值匹配但节点已访问过,返回false
}
}
}
// 重置树中所有节点的标记为0
private void reset(Node2 head){
head.flag = 0; // 重置当前节点的标记
if (head.left != null){
reset(head.left); // 递归重置左子树
}
if (head.right != null){
reset(head.right); // 递归重置右子树
}
}
}
// 定义树的节点类
class Node2{
int data; // 节点存储的数据
Node2 left; // 左子节点
Node2 right; // 右子节点
int flag; // 标记节点是否已在某个过程中被访问过
public Node2(int data) {
this.data = data; // 构造函数,初始化节点数据
this.flag = 0; // 初始化标记为0
this.left = null; // 初始化左右子节点为null
this.right = null;
}
}运行结果:
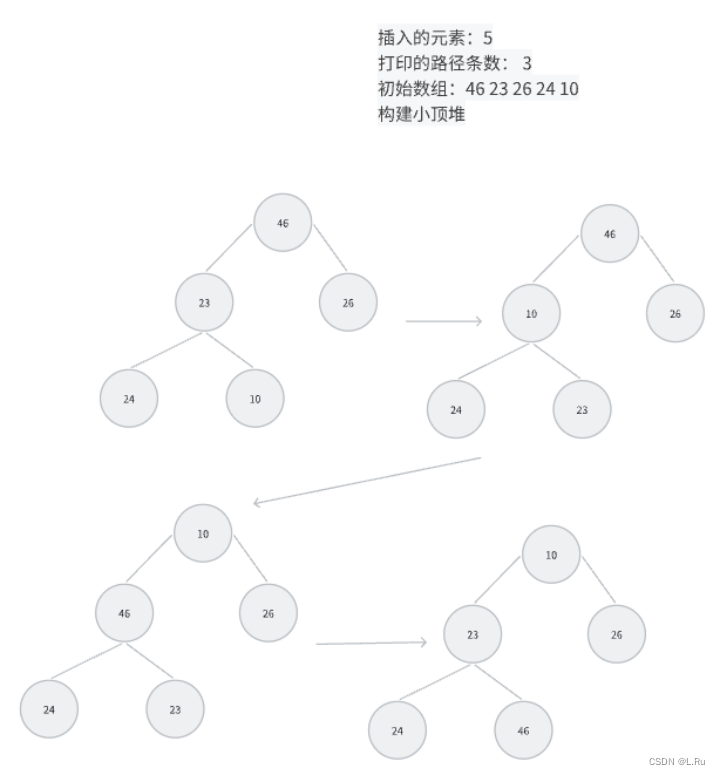
题目三、堆中的路径
将一系列给定数字插入一个初始为空的最小堆 h。随后对任意给定的下标 i,打印从第 i 个结点到根结点的路径。
输入格式:
每组测试第 1 行包含 2 个正整数 n 和 m (≤103),分别是插入元素的个数、以及需要打印的路径条数。下一行给出区间 [−104,104] 内的 n 个要被插入一个初始为空的小顶堆的整数。最后一行给出 m 个下标。
输出格式:
对输入中给出的每个下标 i,在一行中输出从第 i 个结点到根结点的路径上的数据。数字间以 1 个空格分隔,行末不得有多余空格。
输入样例:
5 3
46 23 26 24 10
5 4 3
输出样例:
24 23 10
46 23 10
26 10
解题思路:
实现思路:
1.初始化堆:首先,创建一个数组heap来存储堆中的元素,并设置一个变量size来跟踪堆的大小。
2.插入元素:我们从输入中读取元素,并使用insert函数将它们插入到堆中。在insert函数中,我们首先增加堆的大小,然后将新元素插入到堆的末尾。然后,我们开始一个循环,如果新插入的元素小于其父节点,我们就将其上移。这个过程一直持续到新元素大于其父节点或者成为新的根节点。
3.打印路径:我们从输入中读取需要打印路径的元素的索引,并使用printPath函数来打印从根节点到这些元素的路径。在printPath函数中,我们从指定的元素开始,沿着父节点向上遍历,直到到达根节点。在这个过程中,我们打印出遍历过程中遇到的每一个元素。
图解:
代码实现:
import java.util.*;
public class Main {
private static int[] heap;
private static int size;
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
heap = new int[n + 1];
size = 0;
for (int i = 1; i <= n; i++) {
insert(scanner.nextInt());
}
for (int i = 0; i < m; i++) {
printPath(scanner.nextInt());
}
scanner.close();
}
private static void insert(int x) {
int i = ++size;
for (; i > 1 && x < heap[i / 2]; i /= 2) {
heap[i] = heap[i / 2];
}
heap[i] = x;
}
private static void printPath(int i) {
while (i > 1) {
System.out.print(heap[i] + " ");
i /= 2;
}
System.out.println(heap[i]);
}
}运行结果:
题目四:哈夫曼树
哈夫曼树,第一行输入一个数n,表示叶结点的个数。
需要用这些叶结点生成哈夫曼树,根据哈夫曼树的概念,这些结点有权值,即weight,题目需要输出哈夫曼树的带权路径长度(WPL)。
输入格式:
第一行输入一个数n,第二行输入n个叶结点(叶结点权值不超过1000,2<=n<=1000)。
输出格式:
在一行中输出WPL值。
输入样例:
5
1 2 2 5 9
输出样例:
37
解题思路:
1.读取叶结点的数量:首先,我们从输入中读取叶结点的数量。
2.创建优先队列:然后,我们创建一个优先队列来存储叶结点的权值。优先队列的特性是,队列中的最小元素总是位于队列的头部。
3.将叶结点的权值添加到队列中:我们将每个叶结点的权值添加到优先队列中。
4.计算哈夫曼树的带权路径长度:当队列中的元素多于1个时,我们执行以下操作:
取出队列中的最小元素。
再次取出队列中的最小元素。
将这两个元素的和加到总和中。
将这两个元素的和添加回队列中。
这个过程一直持续到队列中只剩下一个元素。这个过程模拟了哈夫曼树的构建过程,每次都合并权值最小的两个结点,直到所有的结点都被合并到一棵树中。
输出哈夫曼树的带权路径长度:最后,我们输出总和,即哈夫曼树的带权路径长度。
图解:

代码实现:
import java.util.PriorityQueue;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner inputScanner = new Scanner(System.in);
int leafNodeCount = inputScanner.nextInt(); // 读取叶结点的数量
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(); // 创建一个优先队列
for (int i = 0; i < leafNodeCount; i++) {
priorityQueue.offer(inputScanner.nextInt()); // 将每个叶结点的权值添加到队列中
}
int weightedPathLength = 0; // 初始化总和为0
while (priorityQueue.size() > 1) { // 当队列中的元素多于1个时,执行循环
int smallestElement = priorityQueue.poll(); // 取出队列中的最小元素
int secondSmallestElement = priorityQueue.poll(); // 再次取出队列中的最小元素
weightedPathLength += smallestElement + secondSmallestElement; // 将这两个元素的和加到总和中
priorityQueue.offer(smallestElement + secondSmallestElement); // 将这两个元素的和添加回队列中
}
System.out.println(weightedPathLength); // 输出总和,即哈夫曼树的带权路径长度(WPL)
}
}运行结果:















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









