










一、实验目的与要求
目的:
1.理解排序、散列的概念。
2.掌握选择与插入排序、快速与归并排序、散列查找等算法
要求:
- 请写出解题的思路(可采用思维导图、流程图或伪代码说明等,任何能说明的方式);
- 给出关键代码;
请提供以上的输入测试数据和输出结果截图;
二、实验原理与内容(共三题)
(1)有序数组的插入
使用插入法排序,假设x数组的n个数据已经按降序排列,现在插入一个数y到数组中,使数组x仍然是降序排列的。
输入格式:
在第一行中输入正整数n值。
在第二行中输入n个用空格间隔的降序排好的整数,数据之间只能用1个空格间隔。
在第三行中输入一个待插入的整数y。
所有数据均是100以内的正整数。
输出格式:
在一行中输出将y插入后的有序数组,每个数据输出占3列。
输入样例:
5
7 6 3 2 1
4
输出样例:
7 6 4 3 2 1
(2)英文单词排序
本题要求编写程序,输入若干英文单词,对这些单词按长度从小到大排序后输出。如果长度相同,按照输入的顺序不变。
输入格式:
输入为若干英文单词,每行一个,以#作为输入结束标志。其中英文单词总数不超过20个,英文单词为长度小于10的仅由小写英文字母组成的字符串。
输出格式:
输出为排序后的结果,每个单词后面都额外输出一个空格。
输入样例:
blue
red
yellow
green
purple
#
输出样例:
red blue green yellow purple
(3)点赞狂魔
微博上有个“点赞”功能,你可以为你喜欢的博文点个赞表示支持。每篇博文都有一些刻画其特性的标签,而你点赞的博文的类型,也间接刻画了你的特性。然而有这么一种人,他们会通过给自己看到的一切内容点赞来狂刷存在感,这种人就被称为“点赞狂魔”。他们点赞的标签非常分散,无法体现出明显的特性。本题就要求你写个程序,通过统计每个人点赞的不同标签的数量,找出前3名点赞狂魔。
输入格式:
输入在第一行给出一个正整数N(≤100),是待统计的用户数。随后N行,每行列出一位用户的点赞标签。格式为“Name K F1⋯FK”,其中Name是不超过8个英文小写字母的非空用户名,1≤K≤1000,Fi(i=1,⋯,K)是特性标签的编号,我们将所有特性标签从 1 到 107 编号。数字间以空格分隔。
输出格式:
统计每个人点赞的不同标签的数量,找出数量最大的前3名,在一行中顺序输出他们的用户名,其间以1个空格分隔,且行末不得有多余空格。如果有并列,则输出标签出现次数平均值最小的那个,题目保证这样的用户没有并列。若不足3人,则用-补齐缺失,例如mike jenny -就表示只有2人。
输入样例:
5
bob 11 101 102 103 104 105 106 107 108 108 107 107
peter 8 1 2 3 4 3 2 5 1
chris 12 1 2 3 4 5 6 7 8 9 1 2 3
john 10 8 7 6 5 4 3 2 1 7 5
jack 9 6 7 8 9 10 11 12 13 14
输出样例:
jack chris john
三、实验设备与软件环境
硬件环境要求:
PC机(单机)
使用的软件名称、版本号:
Dev C++、C free
四、实验过程与结果(可贴图)
第一题:
解题思路:
- 先输入读取
- 创建并填充数组
- 读取插入的整数
- 找到插入的位置,进行插入操作
- 输出结果并释放资源
图解:
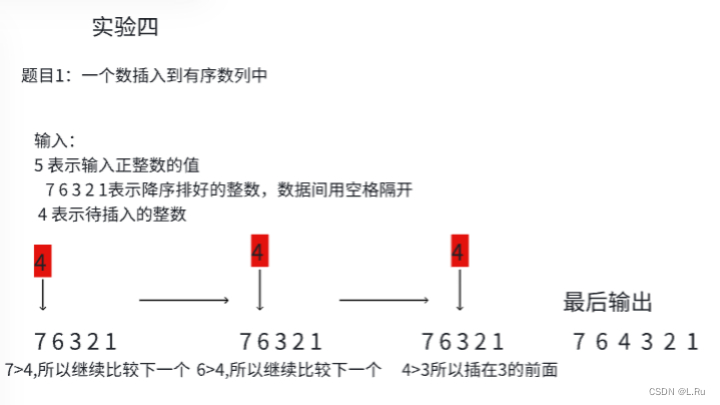
代码如下:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
// 创建一个扫描器对象来读取用户输入
Scanner scanner = new Scanner(System.in);
// 读取用户输入的整数n
int n = scanner.nextInt();
// 创建一个数组,长度为n+1,用于存储用户输入的n个整数和待插入的整数y
int[] array = new int[n + 1];
// 读取用户输入的n个整数并存储在数组中
for (int i = 0; i < n; i++) {
array[i] = scanner.nextInt();
}
// 读取用户输入的待插入的整数y
int y = scanner.nextInt();
// 找到插入y的位置,使得插入后的数组仍然是降序排列
int j = n - 1;
while (j >= 0 && array[j] < y) {
array[j + 1] = array[j];
j--;
}
// 插入整数y
array[j + 1] = y;
// 打印出插入y后的数组,每个元素占3列
for (int i = 0; i <= n; i++) {
System.out.printf("%3d", array[i]);
}
// 关闭扫描器
scanner.close();
}
}运行结果:
第二题:
思路步骤:
- 创建一个列表用来存储单词
- 读取用户输入并存放到列表中
- 比较字符串的长度并按升序排序
- 输出排序好的单词
图解:
 代码如下:
代码如下:
import java.util.*; // 导入Java标准库中的一些类
public class Main {
public static void main(String[] args) {
// 创建Scanner对象用于读取用户输入
Scanner scanner = new Scanner(System.in);
// 创建一个ArrayList来存储用户输入的单词
List<String> words = new ArrayList<>();
String input; // 用于存储每次读取的输入
// 循环读取用户输入,直到用户输入"#"作为结束标志
while (!(input = scanner.nextLine()).equals("#")) {
// 将每次读取的输入添加到words列表中
words.add(input);
}
// 使用Collections.sort方法和Comparator.comparingInt来对words列表进行排序
// 这里比较的是单词的长度,即按字符串的长度升序排序
Collections.sort(words, Comparator.comparingInt(String::length));
// 遍历排序后的words列表
for (String word : words) {
// 打印每个单词,单词之间用空格分隔
System.out.print(word + " ");
}
// 关闭scanner对象,释放资源
scanner.close();
}
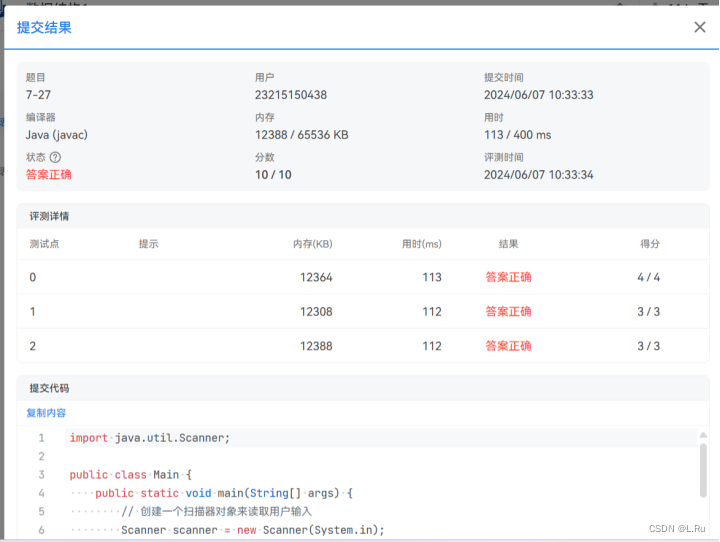
}运行结果:
第三题:
思路步骤:
- 读取输入数据
- 统计点赞不同标签数量,需要去重 HashSet
- 如果两个用户点赞的不同标签数量相同,则比较他们点赞的总标签数量,
- 赞总标签数量少的用户排在前面。
- 输出排序结果
图解:

代码如下:
import java.io.*; // 导入Java I/O包中的类
import java.util.*; // 导入Java util包中的类
public class Main {
// 定义了一个User类,它实现了Comparable接口,可以进行自定义排序
static class User implements Comparable<User> {
String name; // 用户名
int uniqueTags; // 用户的独特标签数
int totalTags; // 用户的总标签数
public User(String name) {
this.name = name; // User类的构造函数
}
// compareTo方法用于比较两个User对象,首先根据uniqueTags降序排序,如果相同,则根据totalTags降序排序
@Override
public int compareTo(User o) {
if (this.uniqueTags != o.uniqueTags) {
return o.uniqueTags - this.uniqueTags; // 降序排序
} else {
return this.totalTags - o.totalTags; // 降序排序
}
}
}
public static void main(String[] args) throws IOException {
// 创建BufferedReader对象用于读取用户输入
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in), 8192);
// 创建PrintWriter对象用于输出结果
PrintWriter writer = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out), 8192));
int N = Integer.parseInt(reader.readLine()); // 读取用户数
User[] users = new User[N]; // 创建User数组
HashSet<Integer> tags = new HashSet<>(); // 创建HashSet用于存储标签
// 读取每个用户的输入
for (int i = 0; i < N; i++) {
StringTokenizer st = new StringTokenizer(reader.readLine());
String name = st.nextToken(); // 读取用户名
int K = Integer.parseInt(st.nextToken()); // 读取标签数
tags.clear(); // 清空HashSet,准备存储新用户的标签
for (int j = 0; j < K; j++) {
tags.add(Integer.parseInt(st.nextToken())); // 读取标签并添加到HashSet中
}
User user = (i < users.length && users[i] != null) ? users[i] : new User(name); // 创建User对象
user.name = name; // 设置用户名
user.uniqueTags = tags.size(); // 设置独特标签数
user.totalTags = K; // 设置总标签数
users[i] = user; // 将User对象添加到数组中
}
// 对User数组进行快速排序
quickSort(users, 0, users.length - 1);
// 创建StringBuilder用于构建输出字符串
StringBuilder sb = new StringBuilder();
// 只输出前3个用户的用户名,如果用户数小于3,则输出"-"
for (int i = 0; i < Math.min(3, N); i++) {
if (i > 0) {
sb.append(" "); // 添加空格分隔用户名
}
sb.append(users[i].name); // 添加用户名到StringBuilder
}
for (int i = N; i < 3; i++) {
if (i > 0) {
sb.append(" ");
}
sb.append("-"); // 添加"-"表示不足3个用户
}
writer.println(sb.toString()); // 输出构建好的字符串
writer.flush(); // 刷新PrintWriter,确保输出被立即执行
}
// 快速排序的辅助方法,对User数组进行排序
public static void quickSort(User[] users, int low, int high) {
if (low < high) {
int pivotIndex = partition(users, low, high); // 获取基准索引
quickSort(users, low, pivotIndex - 1); // 递归排序左侧子数组
quickSort(users, pivotIndex + 1, high); // 递归排序右侧子数组
}
}
// 快速排序中的分区操作
public static int partition(User[] users, int low, int high) {
User pivot = users[high]; // 选择最右侧元素作为基准
int i = low - 1;
// 遍历数组,根据compareTo方法比较元素,并进行交换
for (int j = low; j < high; j++) {
if (users[j].compareTo(pivot) < 0) {
i++;
User temp = users[i];
users[i] = users[j];
users[j] = temp;
}
}
// 交换基准元素到正确的位置
User temp = users[i + 1];
users[i + 1] = users[high];
users[high] = temp;
return i + 1; // 返回基准索引
}
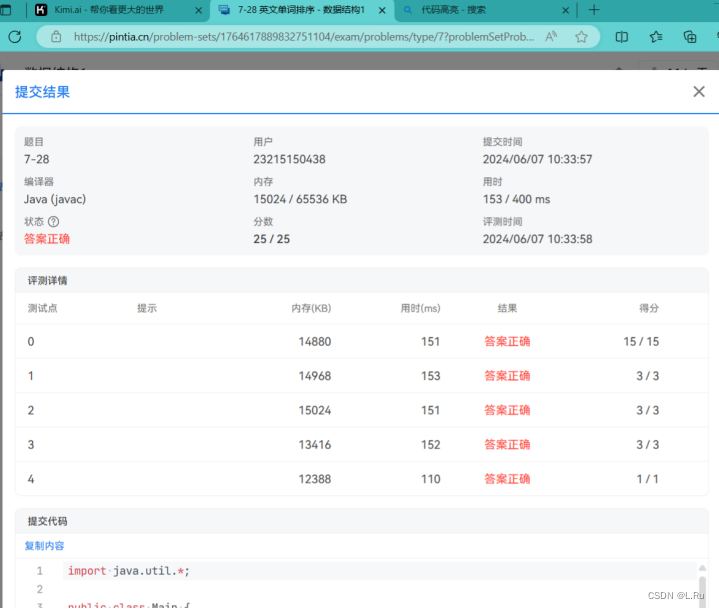
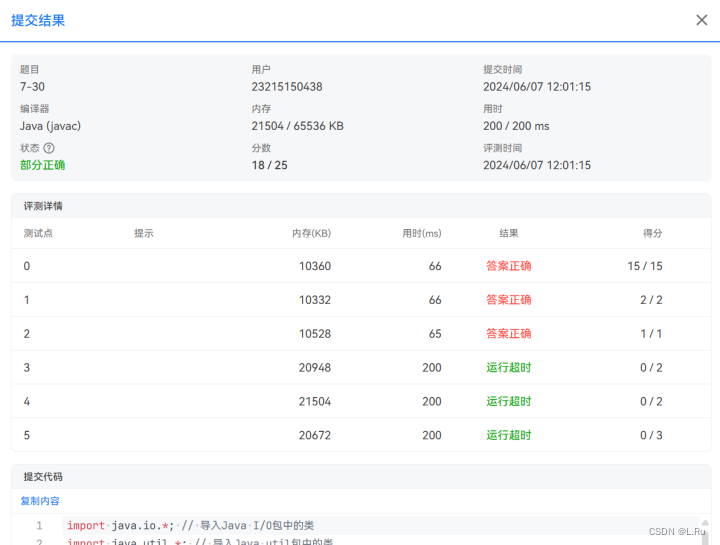
}运行结果:















 3111
3111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









