







支持向量机(Support Vector Machine,简称 SVM)是一种常用于分类和回归任务的监督学习算法。它的核心思想是通过在特征空间中找到一个能够最大化分类间隔的超平面,将不同类别的数据分离开来。
SVM的目标是找到一个最优的决策边界(即超平面),使得分类间隔(即边界到各类别数据点的最小距离)最大化。SVM可以处理线性可分和线性不可分的数据集。
1. 直观理解SVM
我们先来看看下面这个图:
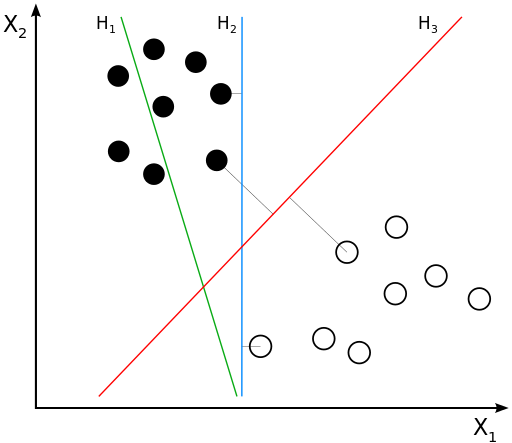
图中有分别属于两类的一些二维数据点和三条直线。如果三条直线分别代表三个分类器的话,请问哪一个分类器比较好

- 线性可分SVM:当训练数据线性可分时,通过硬间隔(hard margin,见下文)最大化可以学习得到一个线性分类器,即硬间隔SVM,如上图的H3.
- 线性SVM:当训练数据不能线性可分但是可以近似线性可分时,通过软间隔(soft margin)最大化也可以学习到一个线性分类器,即软间隔SVM。
- 非线性SVM:当训练数据线性不可分时,通过使用核技巧(kernel trick)和软间隔最大化,可以学习到一个非线性SVM。

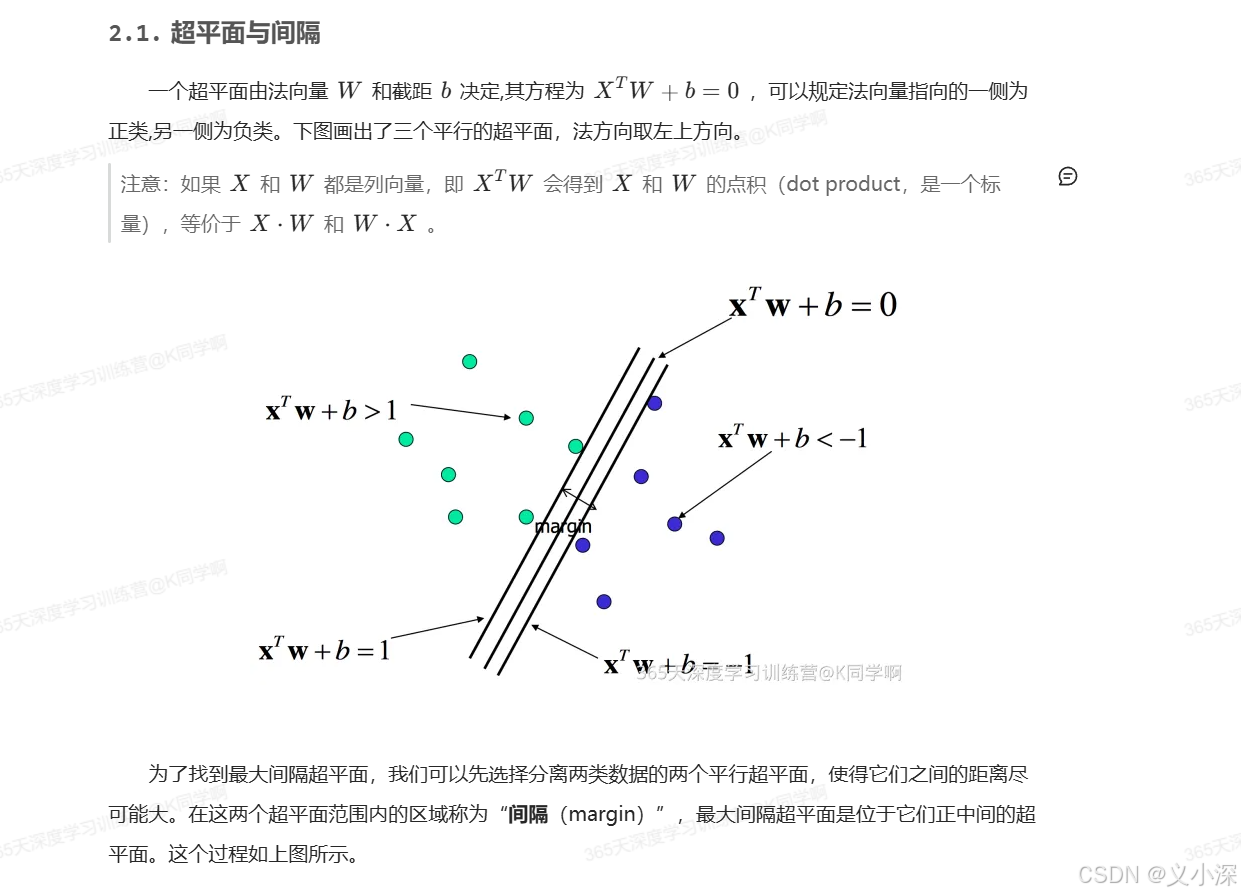
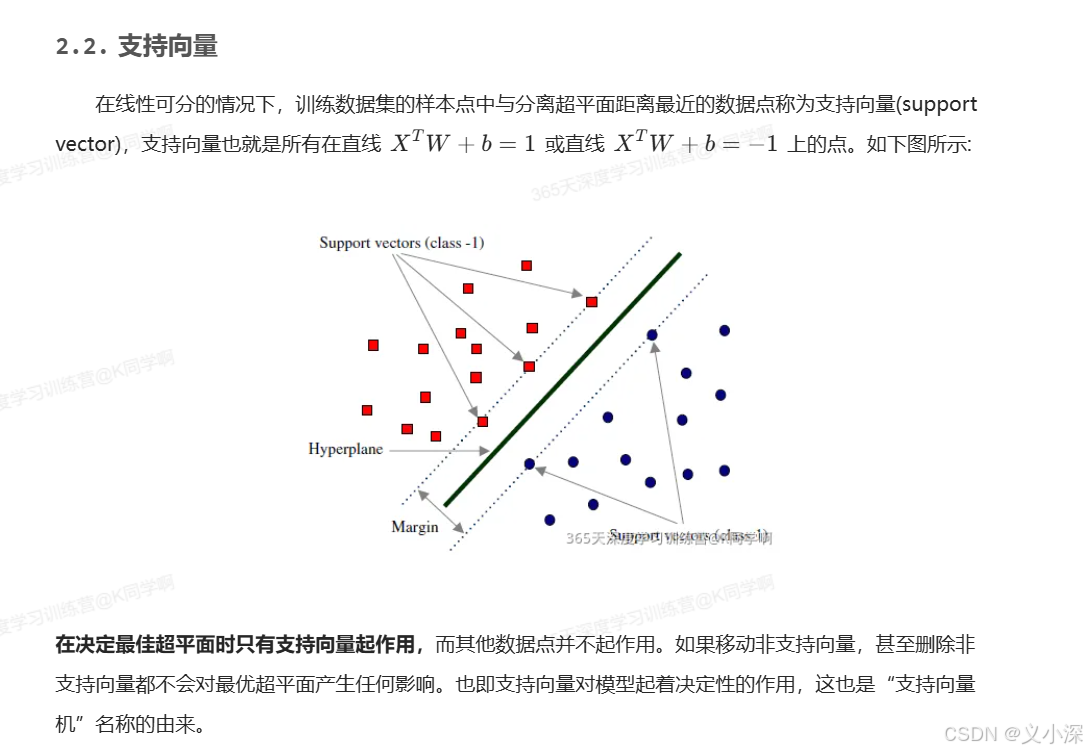


2. 支持向量机实战
1. scikit-learn库实现线性可分的SVM
加载数据集
导入鸢尾花数据集:
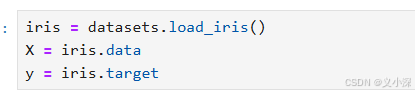
datasets.load_iris() 是 scikit-learn 库中的一个函数,用于加载鸢尾花数据集。该数据集包含 150 个样本,每个样本有四个特征和三个不同的类别(鸢尾花的种类)。
X = iris.data:将数据集中的特征数据(一个 150x4 的数组)赋值给变量X。每一行代表一个样本,每一列代表一个特征(例如,花萼长度、花萼宽度、花瓣长度和花瓣宽度)。y = iris.target:将数据集中的目标变量(一个包含样本对应类别的数组)赋值给变量y。这个数组包含类别标签,通常为 0、1 或 2,分别表示三种不同的鸢尾花
数据预处理——标准化特征数据
这段代码的整体作用是加载鸢尾花数据集,并将特征数据和目标变量分别存储在 X 和 y 中。这为后续的数据分析或机器学习建模提供了基础。鸢尾花数据集是机器学习中的经典示例,常用于分类任务。

fit_transform(X)方法同时执行两个操作:- 拟合(fit):计算输入数据
X的均值和标准差。这些统计量用于后续的标准化。 - 转换(transform):使用计算出的均值和标准差,将
X中的每个特征标准化为均值为 0,标准差为 1 的分布。
- 拟合(fit):计算输入数据
X变量将存储标准化后的特征数据,这意味着每个特征的值都已被调整,以消除不同特征之间的量纲差异
这段代码的整体作用是对特征数据进行标准化处理,使得每个特征在同一尺度上,这有助于提高许多机器学习算法的性能,尤其是基于距离的算法(如 KNN 和线性回归)。标准化使得模型训练更加稳定和快速,同时也有助于提高模型的泛化能力。
训练集和测试集的分割

创建SVM模型
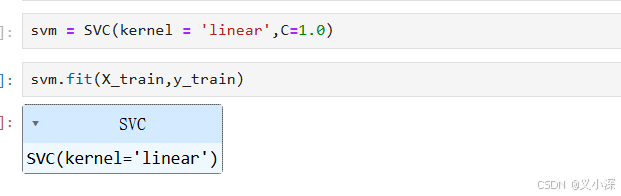
kernel='linear':指定使用线性核函数。线性核适合于线性可分的数据集,表示算法将尝试找到一个超平面来分隔不同的类。C=1.0:是一个正则化参数,控制模型的复杂度。较大的C值会使模型更关注于训练数据中的每个样本,可能导致过拟合;较小的C值则会使模型更加简单,从而可能提高泛化能力。
这段代码的整体作用是创建一个线性支持向量机分类器的实例,用于后续的模型训练和预测。通过调整核函数和正则化参数,可以优化模型以适应不同类型的数据分布。这使得 SVM 成为一种灵活且强大的分类算法,广泛应用于各种机器学习任务中。
训练模型
svm.fit(X_train, y_train):调用 fit 方法,将训练数据 X_train 和对应的目标变量 y_train 传递给 SVM 模型
这个过程包括:
- 学习:模型分析训练数据,寻找最佳的超平面来分隔不同的类别。对于线性核,SVM 将尝试找到一个线性边界(超平面)来最大化不同类之间的间隔。
- 优化:通过求解一个优化问题,确定模型的参数,使得分类器能够有效地将样本分为不同的类别。
这段代码的整体作用是使用训练数据来拟合支持向量机模型,使其能够识别并分类输入数据的模式。完成这一过程后,模型将能够对新样本进行预测。训练好的 SVM 模型将存储在 svm 变量中,随时可以用于后续的预测或评估
预测

-
svm.predict(X_test):调用predict方法,将测试特征数据X_test传递给 SVM 模型。- 该过程包括:
- 分类:模型利用之前学习到的边界(超平面)来判断测试样本的类别。每个测试样本将被分配一个类标签(通常是 0、1 或 2,对于鸢尾花数据集而言)。
-
结果存储:
y_pred变量将存储模型对测试数据的预测结果。这是一个数组,包含与X_test中样本对应的预测类别。
这段代码的整体作用是生成模型对未见过的测试数据的预测结果。这是模型评估的重要一步,能够帮助判断模型的性能和准确性。通过比较 y_pred 和实际的 y_test 值,可以评估模型的分类效果
![]()
评估模型性能
accuracy_score是scikit-learn中的一个函数,用于计算分类模型的准确率。y_test:实际的测试标签。y_pred:模型对测试数据的预测结果。- 该函数会返回一个值,表示正确预测的样本占总样本的比例,范围在 0 到 1 之间。
2. scikit-learn库实现非线性可分的SVM

3. sklearn.svm.SVC函数详解
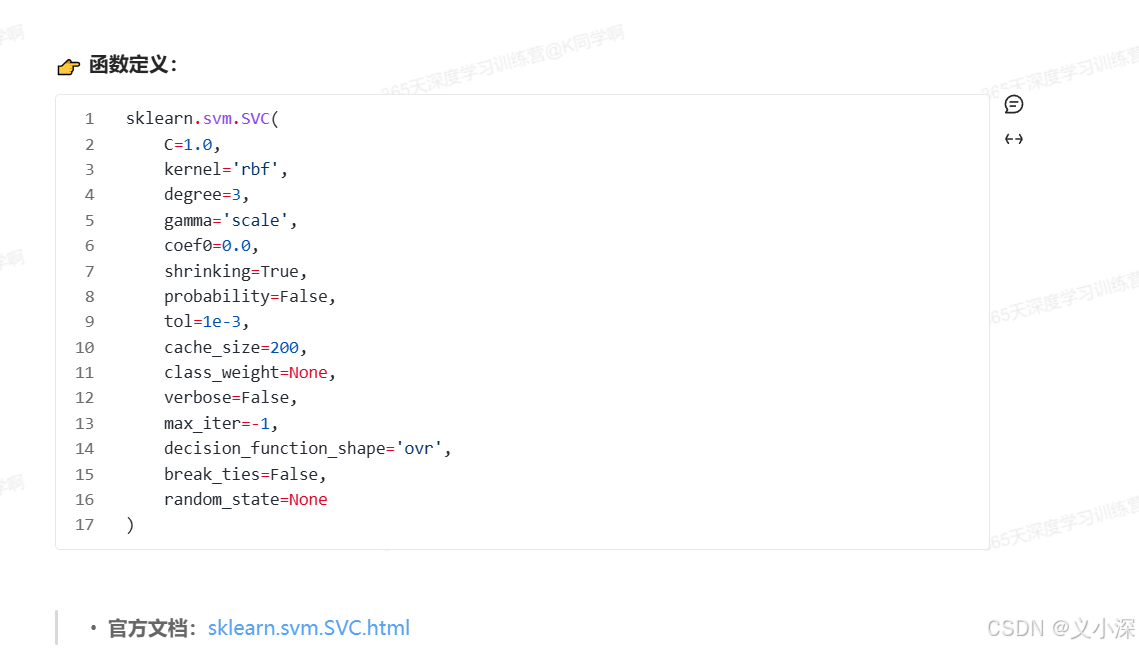
常用参数详解:
C(默认值:1.0)
-
- 作用:惩罚参数,用于平衡最大化分类间隔和误分类惩罚之间的关系。
- 解释:较大的
C值意味着对误分类的惩罚更大,模型会倾向于将更多的训练数据点分类正确,但可能会导致间隔变小,可能出现过拟合;较小的C值则会更关注于间隔的大小,而允许更多的误分类,从而提高模型的泛化能力。 - 常用范围:通常在
0.001到1000之间进行调节。
kernel(默认值:'rbf')
-
- 作用:指定要使用的核函数,支持不同的非线性映射方法。
- 可选值:
-
-
'linear':线性核函数,即不进行任何非线性映射。'poly':多项式核函数,通常用于多项式可分的情况。'rbf':径向基函数(Radial Basis Function),又称高斯核,是最常用的非线性核函数。'sigmoid':类似于神经网络的激活函数,较少使用。- 你也可以传递自定义核函数,方法是传递一个函数。
-
degree(默认值:3)
-
- 作用:当
kernel='poly'时,指定多项式核的多项式次数。 - 解释:如果使用多项式核函数(
poly),degree参数决定多项式的阶数,通常是 2 或 3。
- 作用:当
gamma(默认值:'scale')
-
- 作用:核函数系数,适用于
'rbf'、'poly'和'sigmoid'核函数。 - 可选值:
- 作用:核函数系数,适用于
-
-
'scale':使用1 / (n_features * X.var())作为默认值。这个值会根据输入特征的数量和方差自动调整。'auto':使用1 / n_features作为值。
-
-
- 解释:
gamma值越大,模型越倾向于拟合训练数据,但可能会导致过拟合;gamma值越小,模型更倾向于平滑。
- 解释:
coef0(默认值:0.0)
-
- 作用:核函数中的独立项,仅在
kernel='poly'或kernel='sigmoid'时有意义。 - 解释:用于控制多项式核函数和 sigmoid 核函数中的偏移量。
- 作用:核函数中的独立项,仅在


















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











