







在 PyTorch 中,torch.optim.SGD 是一种常用的优化器,基于随机梯度下降(Stochastic Gradient Descent),它可以通过指定参数实现各种变体,如带动量的 SGD、带权重衰减的 SGD 等。以下是对其参数的详细介绍:
定义
torch.optim.SGD(
params,
lr,
momentum=0,
dampening=0,
weight_decay=0,
nesterov=False
)
参数详解
1. params
- 含义:待优化的参数。
- 类型:
iterable或dict - 作用:告诉优化器需要更新哪些模型的参数,一般通过
model.parameters()获取。 - 示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
2. lr(学习率)
- 含义:优化器的学习率,用于控制每次参数更新的步长。
- 类型:浮点数
- 作用:较大的学习率可能导致训练过程不稳定,而较小的学习率可能导致训练收敛过慢。
- 示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
3. momentum
- 含义:动量因子,用于加速梯度下降的收敛速度。
- 默认值:
0(表示不使用动量) - 类型:浮点数
- 作用:
- 动量帮助优化器在某一方向上积累动量,防止陷入局部最优或在谷底震荡。
- 公式: 其中,
v是动量向量。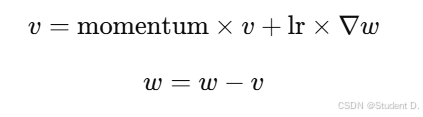
- 推荐值:常用
momentum=0.9。 - 示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
4. dampening
- 含义:抑制动量的因子。
- 默认值:
0 - 类型:浮点数
- 作用:
- 控制动量的衰减。如果
dampening=0,则动量一直累加;如果大于 0,则动量逐步减弱。 - 一般情况下,
dampening很少被使用。
- 控制动量的衰减。如果
- 示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, dampening=0.1)
5. weight_decay
- 含义:权重衰减(L2 正则化)。
- 默认值:
0 - 类型:浮点数
- 作用:
- 防止模型过拟合,通过在损失函数中增加权重的平方惩罚项来实现:
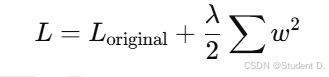
- 其中,
lambda是weight_decay,w是模型的权重。
- 防止模型过拟合,通过在损失函数中增加权重的平方惩罚项来实现:
- 推荐值:
1e-4或5e-4通常在实践中表现较好。 - 示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
6. nesterov
- 含义:是否使用 Nesterov 动量。
- 默认值:
False - 类型:布尔值
- 作用:

- 示例:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=True)
综合示例
import torch
import torch.nn as nn
# 定义一个简单的模型
model = nn.Linear(10, 1)
# 定义优化器
optimizer = torch.optim.SGD(
model.parameters(),
lr=0.01,
momentum=0.9,
weight_decay=1e-4,
nesterov=True
)
# 定义损失函数
criterion = nn.MSELoss()
# 训练步骤
inputs = torch.randn(5, 10) # 输入张量
targets = torch.randn(5, 1) # 目标张量
for epoch in range(100):
optimizer.zero_grad() # 清空梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, targets) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
小结
torch.optim.SGD 的灵活性体现在它可以实现:
- 普通 SGD:设置
momentum=0。 - 带动量的 SGD:设置
momentum>0。 - Nesterov 动量:设置
momentum>0且nesterov=True。 - L2 正则化:设置
weight_decay>0。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









