






 本文提供了一步一步的指南,包括如何申请武大超算账号,下载并使用PuTTY和FileZilla连接超算,安装miniconda创建虚拟环境,特别是针对yolov5的环境配置。此外,还详细介绍了Slurm作业系统的使用和相关命令,以及在超算上进行GPU训练的基本步骤和常见问题的解决方案。
本文提供了一步一步的指南,包括如何申请武大超算账号,下载并使用PuTTY和FileZilla连接超算,安装miniconda创建虚拟环境,特别是针对yolov5的环境配置。此外,还详细介绍了Slurm作业系统的使用和相关命令,以及在超算上进行GPU训练的基本步骤和常见问题的解决方案。
仅供初次使用借鉴
目录
一、申请账号
进入官网申请武大超算,两三个工作日后学生邮箱会收到hpc邮箱,内含:
- 用户名 seawithstars
- 初始密码 xxxxxxxx
- 登录地址 202.114.96.180
二、下载软件
1.PuTTY
下载地址:PuTTY 连接超算!
2.FileZilla
下载地址: FileZilla 传输文件!
三、连接超算
1.使用PuTTY连接
如图:
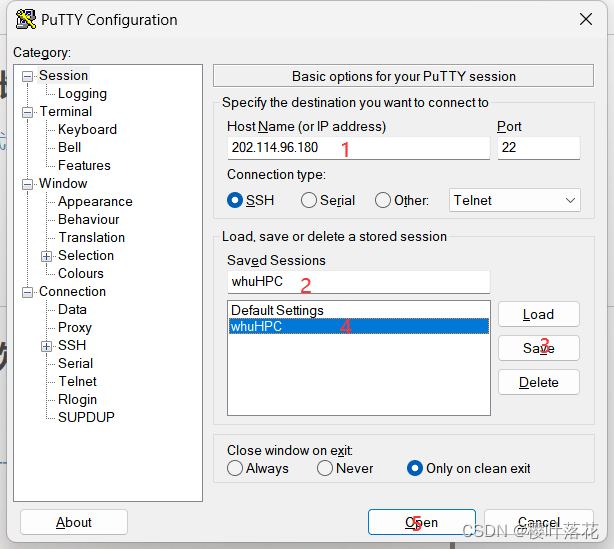
- 填入登录地址
- 输入Sessions名称
- Save Sessions ( 这样下次就不用再次输入登录地址,直接点击新建的Session)
- 点击刚才的Session
- Open
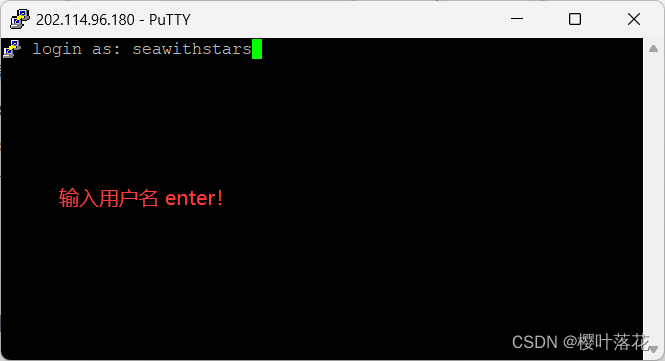
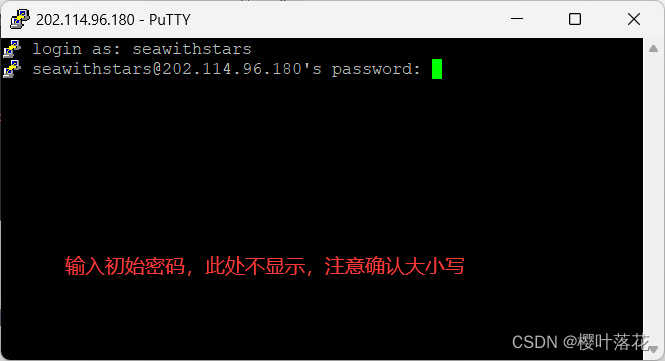
6.输入用户名以及初始密码后,即可进入超算中自己的账户,出现以下内容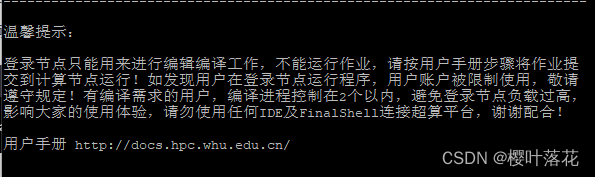
此时我们可以更改初始密码,需要至少一个小写字母一个大写字母。输入:
passwd会出现修改密码,按照提示修改即可。
[seawithstars@swarm02 ~]$ passwd
Changing password for user seawithstars.
Changing password for seawithstars.
(current) UNIX password:其中 seawithstars就是用户名,swarm02就是登录节点,登录节点不允许长时间计算占用资源
2.使用FileZilla进入文件传输
如图:
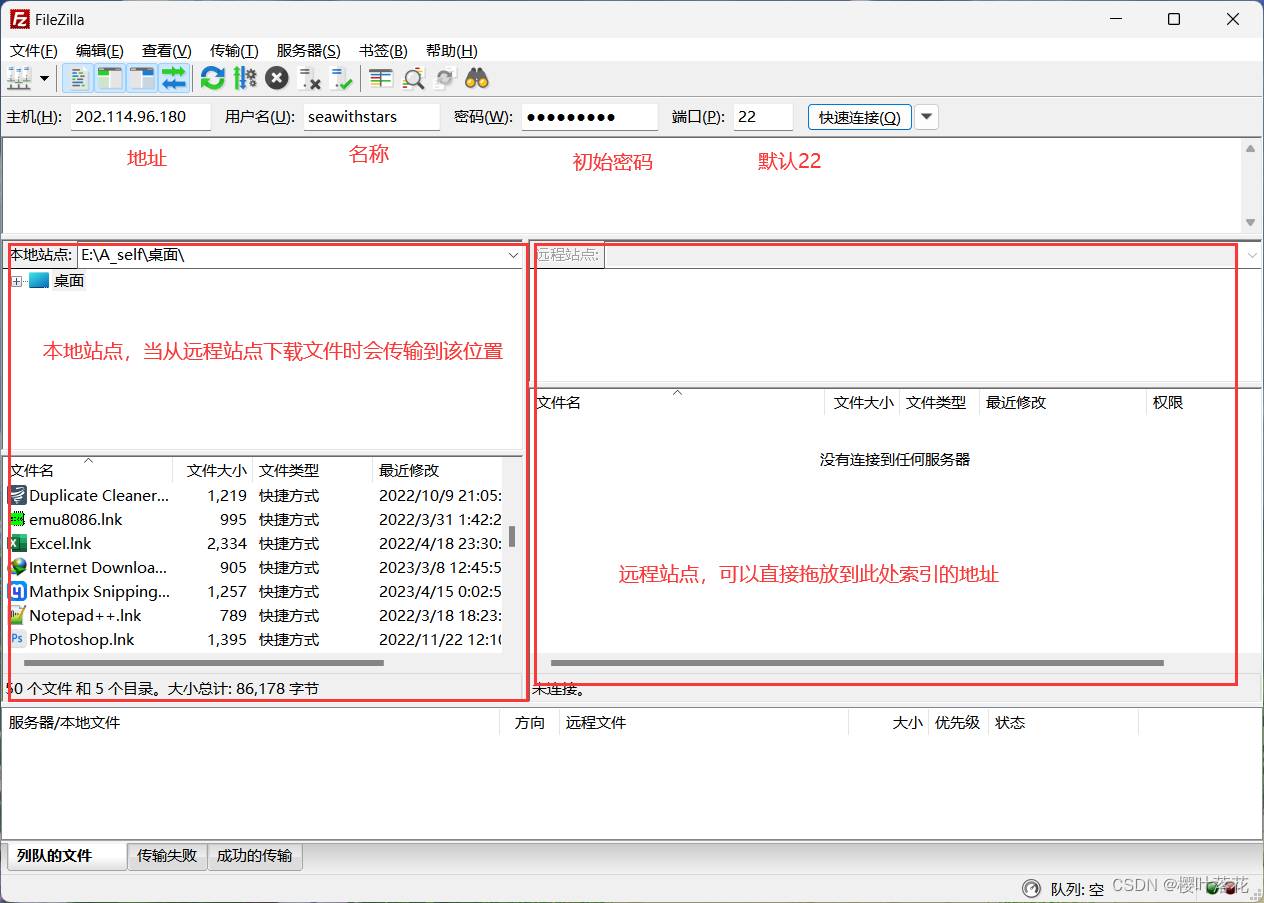
现在我们来认识一下武大超算给我们的存储空间:
/home/seawithstars/
- 文件容量限额
1GB - 文件数量限额
10000 - 目录下的文件长期保存
- 建议仅用来保存用户的环境变量等设置信息
/project/seawithstars/ 其实该地址也可以 /home/seawithstars/project/
- 文件容量限额
500GB - 文件数量限额
500000 - 目录下的文件长期保存
- 主要的计算程序和数据存储空间
四、配置环境
1.安装miniconda
这里我们参考官方指导:
Conda在安装(升级)软件包或者使用虚拟环境的时候,需要用到~/.conda和~/.cache目录,因为武大超算~/目录的容量限制,将这两个目录移动到~/project下面有助于消除因容量限制引起的问题
首先创建文件:
mkdir ~/project/conda_user
ln -s ~/project/conda_user ~/.conda
mkdir ~/project/conda_cache
ln -s ~/project/conda_cache ~/.cache然后移动文件指向:
mv ~/.conda ~/project/conda_user
ln -s ~/project/conda_user ~/.conda
mv ~/.cache ~/project/conda_cache
ln -s ~/project/conda_cache ~/.cache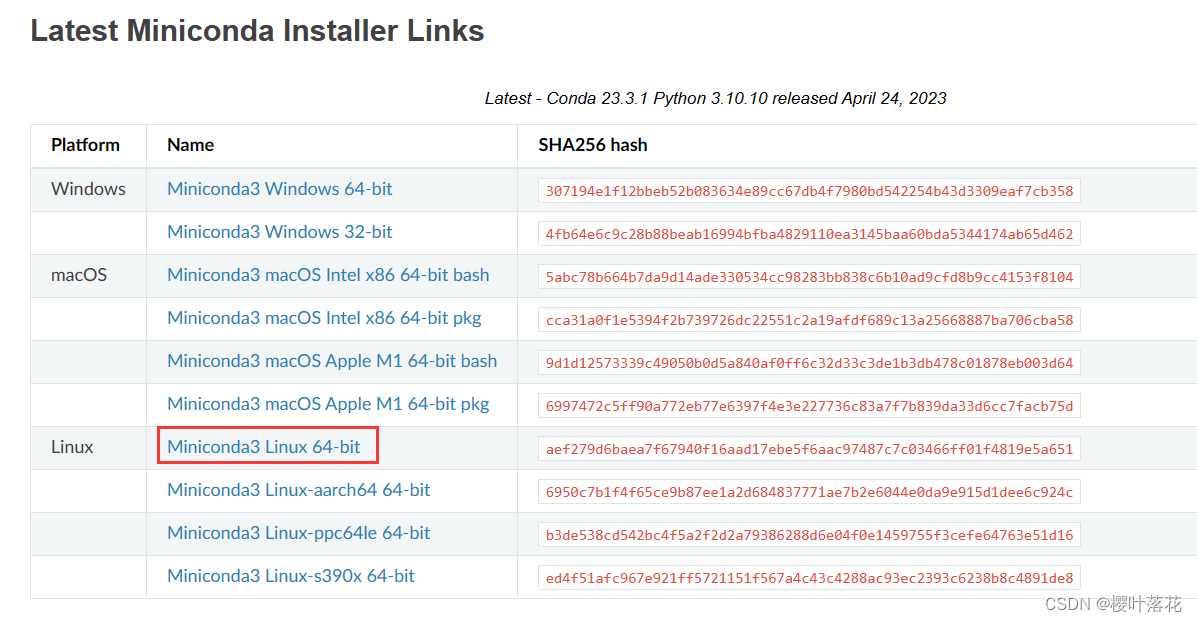
下载后使用FileZilla传输到/project/liuyuhao/ 使用PuTTY执行一下命令:
cd project
ls
进入project文件夹并列出所含文件(夹),命令行下会出现:
conda_cache conda_user Miniconda3-latest-Linux-x86_64.sh
安装sh文件:
sh Miniconda3-latest-Linux-x86_64.sh1.会出现一些协议确定,一直点 enter
2.输入 yes 同意协议

3.选择存储位置,将home 改为 project,然后执行安装并等待

4.安装程序会询问是否在 ~/.bashrc 中加入环境变量控制,选择是,用户每次登录后就可以直接使用这次安装的 miniconda3的base环境中

5.结束安装,出现:
Thank you for installing Miniconda3!
6.验证conda指令,会列出当前的环境
conda env list

7.为conda换源,在控制台输入
vim ~/.condarcvim是一个编辑器 ~/即/home/liuyuhao/ .condarc是文件名
进入vim之后 点击输入小写 i 复制一下channels然后在控制台点击右键(粘贴)
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/MindSpore
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/auto
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/biobakery
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/c4aarch64
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/caffe2
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/deepmodeling
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/dglteam
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fermi
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/idaholab
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/intel
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/matsci
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/mordred-descriptor
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/numba
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/ohmeta
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/omnia
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/peterjc123
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/plotly
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/psi4
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch-lts
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch-test
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch3d
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pyviz
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/qiime2
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/rapidsai
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/rdkit
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/simpleitk
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/stackless
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/ursky
- defaults
show_channel_urls: true输入完成后点击 Esc ,随后输入(保存并退出)
:wq
同理给pip换源
mkdir ~/.pip # 配置文件位置在 ~/.pip/pip.conf(如果不存在创建该目录和文件)
vim ~/.pip/pip.conf # 打开配置文件,修改如下:插入
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = https://pypi.tuna.tsinghua.edu.cn保存并退出即可。
2.创建适用于yolov5的虚拟环境
1.导入yolov5项目(访问github可能需要魔法),项目地址,下载后传输到 /project/liuyuhao/
2.进入yolov5-master文件夹并创建虚拟环境yolo38
cd yolov5-master
conda create -n yolo38 python=3.83.输入y确定创建并下载依赖包
4.进入虚拟环境
conda activate yolo385.安装依赖库文件
如果是使用cpu训练那么可以不用介意使用什么版本的torch,直接pip
如果使用GPU则要查询超算cuda版本对应的torch以及torchvision
为避免安装torch出现问题,先手动安装torch,torchvision
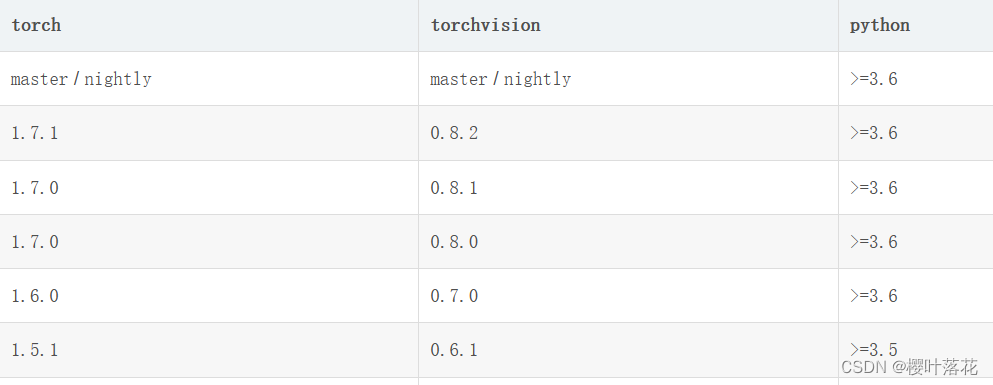
pip install torch==1.7.0
pip install torchvision==0.8.1然后再根据requirements安装:
pip install -r requirements.txt最后再跑一遍确认所有库安装完成
pip install -r requirements.txt6.下载字体文件,yolov5需要字体,下载过程比较慢,在电脑上下载(需要魔法)后移动到超算上
移动到
/home/seawithstars/.config/Ultralytics/7.在登录节点试运行
conda activate yolo38
python train.py出现训练过程即可 ctrl+C终止运行

3.提交训练
使用srun或者sbatch更换节点计算
参见下一章节
五、超算相关命令
注:学生只能使用hpxg分区 最大使用16个cpu核 最多占用两个节点
1.Slurm作业系统
①使用sbatch提交
- 第一行是脚本语言解释器的路径,一般选择
bash作为解释器 - 若干行由
#SBATCH引导的 Slurm 设置选项 - 计算程序运行需要设置的环境变量
- 运行程序的命令
vim yolo.sbatch插入:
#!/bin/bash
#SBATCH --partition=hpxg #申请分区 `hpxg` 的计算资源
#SBATCH --cpus-per-task=15
#SBATCH --ntasks=1
conda init
source ~/.bashrc
cd $SLURM_SUBMIT_DIR
conda activate yolo38
python train.py
添加权限:
chmod +x yolo.sbatch交互式提交任务
使用srun不会读取#SBATCH 需要指定,like
srun -c 15 yolo.sbatch
非交互式提交任务
sbatch yolo.sbatch#SBATCH 指令 ,红色为srun指令
#SBATCH --account=supervisor #付费账号关联,用户使用收费分区时,需要关联付费账号,supervisor是导师账户名
#SBATCH --cpus-per-task==16 #每个任务使用16个cpu核 -c
#SBATCH --gres=gpu:2 #使用2块gpu,小于等于每个节点GPU数量4
#SBATCH --nodes=1 #使用1个节点
#SBATCH --ntasks-per-node=1 #每个节点有一个任务
#SBATCH --partition=hpxg #使用hpxg分区
2.相关指令
①运行以下命令查看计算节点的状态信息
sinfo
其中 STATE 常见的有
alloc,节点已经被分配给作业任务down,节点当前不可用drain,节点被管理员设置为退出服务idle,节点当前空闲mix,节点有部分计算资源已被分配,还有部分资源空闲可用
②作业运行状态
squeue
squeue 显示的信息包括以下内容
-
JobID,作业编号 -
PARTITION,作业在哪个分区上运行 -
NAME,作业名称,默认是作业脚本的名字 -
USER,作业的所有者 -
ST,作业当前状态,详见 Job State Codes,常见的有CG作业正在完成F作业失败PD作业正在等待分配资源R作业正在运行
-
TIME,作业已运行时间 -
NODES,作业占用的计算节点数 -
NODELIST,作业占用的计算节点名 -
(REASON),作业正在等待执行的原因,详见 Job Reason Codes,常见的有AssoGrpCpuLimit导师名下所有学生正在使用的CPU总数达到了导师开通的CPU数量限额AssoGrpGRES导师名下所有学生正在使用的GPU总数达到了导师开通的GPU数量限额Priority作业正在排队等待QOSMinGRES提交到GPU分区的作业没有申请GPU资源
③进入运行节点查看资源占用
ssh 计算节点名
- 在计算节点上,使用
top命令可以查看程序使用 CPU 的状况 - 如果是 GPU 程序,在计算节点上使用
nvidia-smi命令可以查看程序使用 GPU 的状况 - 用户有程序正在运行的计算节点才允许登录
④取消作业
如果用户要取消作业,先运行 squeue 命令查询作业编号数字 JobID ,然后运行以下命令取消作业
scancel JobID
如果要取消用户的所有作业
scancel -u 用户名六、常见问题
问题1: -bash: conda: command not found
vim ~/.bashrc
最后一行加入:
export PATH=$PATH:/project/liuyuhao/miniconda3/bin
source ~/.bashrc
#更新配置文件
问题2: 删除了 .bashrc 或者 .bash_profile
cp /etc/skel/.bash* ~/问题3: 提示 ): No such file or directory bad interpreter(/bin/bash
删除yolo.sbatch 重新创建yolo.sbatch,重新提交任务
rm yolo.sbatch
vim yolo.sbatch
参考网址:
1.武汉大学超算中心


















 8399
8399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











