






大模型部署(ChatGLM为例)和推理框架 Xinference
Xinference 介绍
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于各种模型的推理。通过 Xinference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xinference 与最前沿的 AI 模型,发掘更多可能。
Xinference 安装
为避免后期与大模型依赖冲突,请模型部署框架如 Xinference 等放在不同的 Python 虚拟环境中, 比如 conda, venv, virtualenv 等。本文使用conda进行虚拟环境管理。conda安装不做赘述(可参考往期文章内容),下面将列出conda常用命令。python环境版本支持python3.8-3.11,本文推荐使用3.11.
(1)创建虚拟环境
conda create -n env_name(环境名称) python=3.7(对应的python版本号)
(2)激活虚拟环境
conda activate env_name(环境名称)
(3)退出虚拟环境
deactivate env_name(环境名称)
(4)删除虚拟环境
conda remove -n env_name(环境名称) --all
(5)查看已创建的虚拟环境
conda env list 或 conda info -e 或 conda info --env
(6)查看conda信息
conda info
(7)删除已安装的Python环境
conda remove -n env_name(环境名称) --all
Xinference 在 Linux, Windows, MacOS 上都可以通过 pip 来安装。如果需要使用 Xinference 进行模型推理,可以根据不同的模型指定不同的引擎。Xinference 依赖的第三方库比较多,所以安装需要花费一些时间。
如果你希望能够推理所有支持的模型,可以用以下命令安装所有需要的依赖:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "xinference[all]"
备注:如果你想使用 GGML 格式的模型,建议根据当前使用的硬件手动安装所需要的依赖,以充分利用硬件的加速能力。
**注意:**在 Xinference 安装过程中,有可能会安装 PyTorch 的其他版本(其依赖的vllm[3]组件需要安装),从而导致 GPU 服务器无法正常使用,因此在安装完 Xinference 之后,可以执行以下命令看 PyTorch 是否正常:
python -c "import torch; print(torch.cuda.is_available())"
如果输出结果为True,则表示 PyTorch 正常,否则需要重新安装 PyTorch。
vLLM 引擎
vLLM 是一个支持高并发的高性能大模型推理引擎。当满足以下条件时,Xinference 会自动选择 vllm 作为引擎来达到更高的吞吐量:
- 模型格式为
pytorch,gptq或者awq。 - 当模型格式为
pytorch时,量化选项需为none。 - 当模型格式为
awq时,量化选项需为Int4。 - 当模型格式为
gptq时,量化选项需为Int3、Int4或者Int8。 - 操作系统为 Linux 并且至少有一个支持 CUDA 的设备
- 自定义模型的
model_family字段和内置模型的model_name字段在 vLLM 的支持列表中。
目前,支持的模型包括:
llama-2,llama-3,llama-2-chat,llama-3-instructbaichuan,baichuan-chat,baichuan-2-chatinternlm-16k,internlm-chat-7b,internlm-chat-8k,internlm-chat-20bmistral-v0.1,mistral-instruct-v0.1,mistral-instruct-v0.2,mistral-instruct-v0.3codestral-v0.1Yi,Yi-1.5,Yi-chat,Yi-1.5-chat,Yi-1.5-chat-16kcode-llama,code-llama-python,code-llama-instructdeepseek,deepseek-coder,deepseek-chat,deepseek-coder-instructcodeqwen1.5,codeqwen1.5-chatvicuna-v1.3,vicuna-v1.5internlm2-chatqwen-chatmixtral-instruct-v0.1,mixtral-8x22B-instruct-v0.1chatglm3,chatglm3-32k,chatglm3-128kglm4-chat,glm4-chat-1mqwen1.5-chat,qwen1.5-moe-chatqwen2-instruct,qwen2-moe-instructgemma-itorion-chat,orion-chat-ragc4ai-command-r-v01
Llama.cpp 引擎
Xinference 通过 llama-cpp-python 支持 gguf 和 ggml 格式的模型。建议根据当前使用的硬件手动安装依赖,从而获得最佳的加速效果。
不同硬件的安装方式:
-
Apple M系列
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python -
英伟达显卡:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python -
AMD 显卡:
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
SGLang 引擎
SGLang 具有基于 RadixAttention 的高性能推理运行时。它通过在多个调用之间自动重用KV缓存,显著加速了复杂 LLM 程序的执行。它还支持其他常见推理技术,如连续批处理和张量并行处理。
初始步骤:
pip install 'xinference[sglang]'
本地运行 Xinference
首先,请根据前面的指导确保本地安装了 Xinference。使用以下命令拉起本地的 Xinference 服务:
xinference-local --host 0.0.0.0 --port 9997
服务启动后可以通过访问 http://127.0.0.1:9997/ui 来使用 UI,访问 http://127.0.0.1:9997/docs 来查看 API 文档。
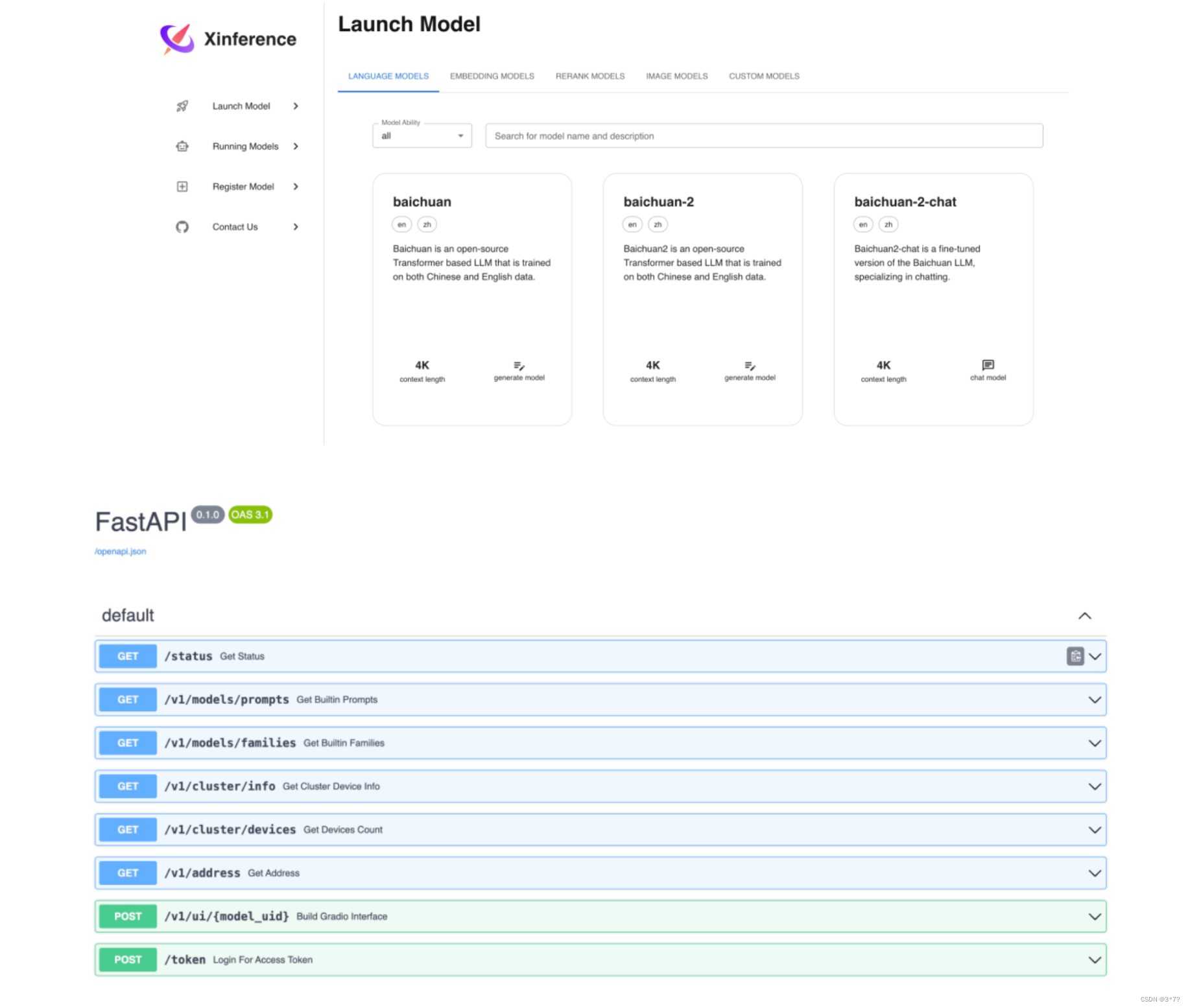
注意:默认情况下,Xinference 会使用 <HOME>/.xinference 作为主目录来存储一些必要的信息,比如日志文件和模型文件,其中 <HOME> 就是当前用户的主目录。
你可以通过配置环境变量 XINFERENCE_HOME 修改主目录, 比如:
XINFERENCE_HOME=/tmp/xinference xinference-local --host 0.0.0.0 --port 9997
模型部署与使用
在 Xinference 的 WebGUI 界面中,我们部署模型非常简单,下面我们来介绍如何部署 LLM 模型。
首先我们在Launch Model菜单中选择LANGUAGE MODELS标签,输入模型关键字chatglm3来搜索我们要部署的 ChatGLM3 模型。
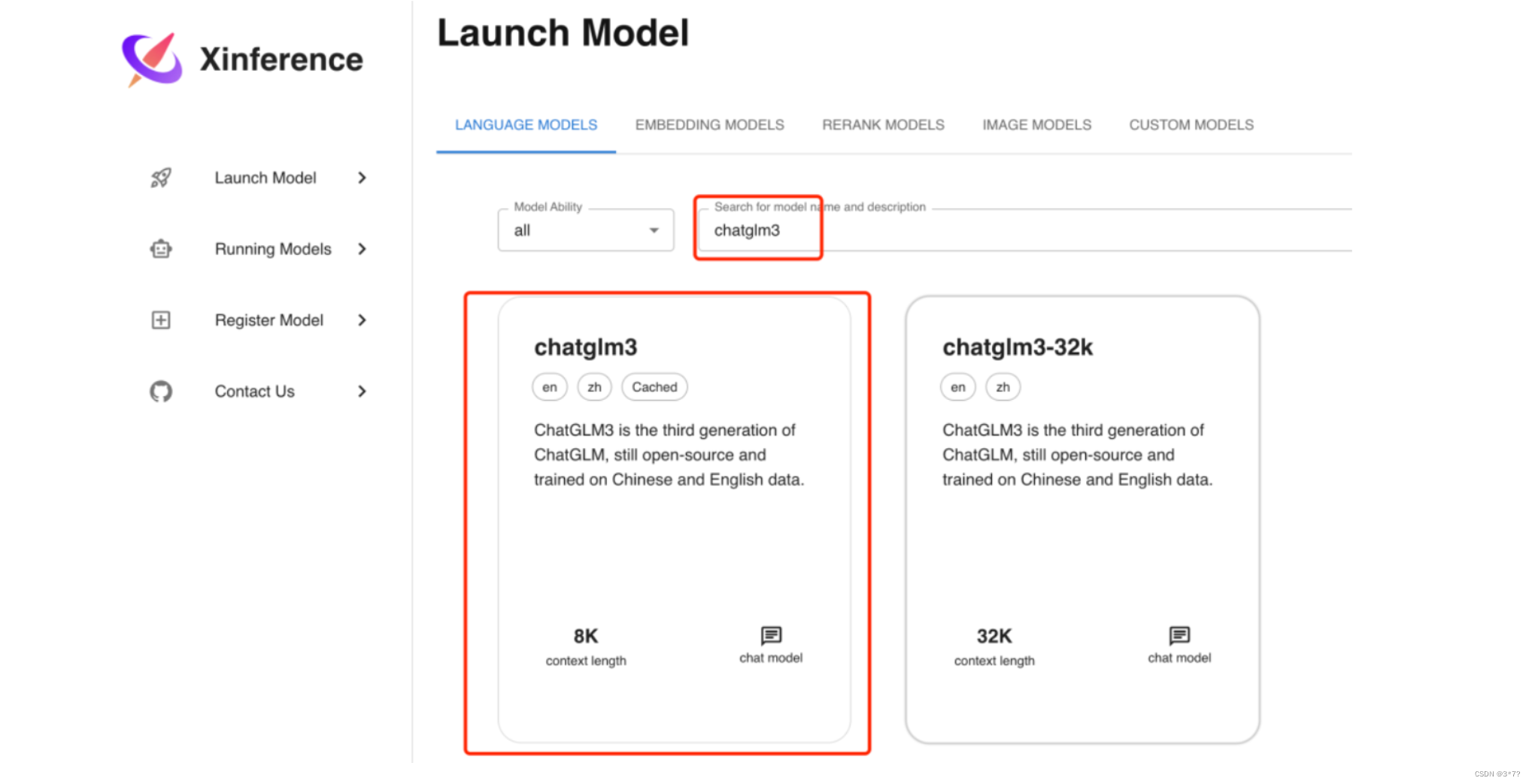
然后点击chatglm3卡片,会出现如下界面:

在部署 LLM 模型时,我们有以下参数可以进行选择:
Model Format: 模型格式,可以选择量化和非量化的格式,非量化的格式是pytorch,量化格式有ggml、gptq等
Model Size:模型的参数量大小,如果是 ChatGLM3 的话就只有 6B 这个选项,而如果是 Llama2 的话,则有 7B、13B、70B 等选项
Quantization:量化精度,有 4bit、8bit 等量化精度选择
N-GPU:选择使用第几个 GPU
Model UID(可选): 模型自定义名称,不填的话就默认用原始模型名称
参数填写完成后,点击左边的火箭图标按钮即开始部署模型,后台会根据参数选择下载量化或非量化的 LLM 模型。部署完成后,界面会自动跳转到Running Models菜单,在LANGUAGE MODELS标签中,我们可以看到部署好的 ChatGLM3-6B 模型。
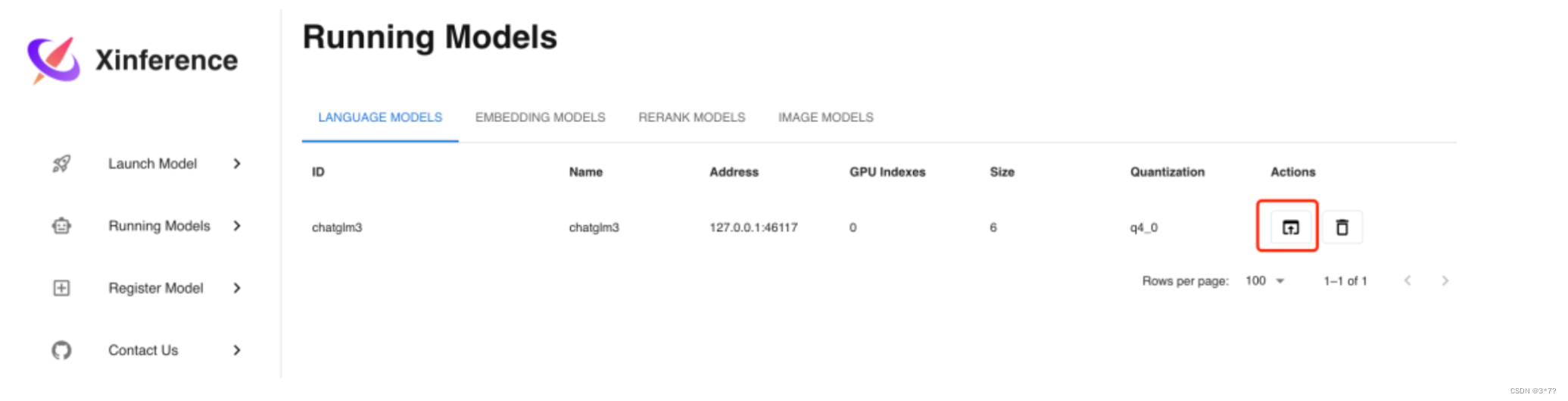
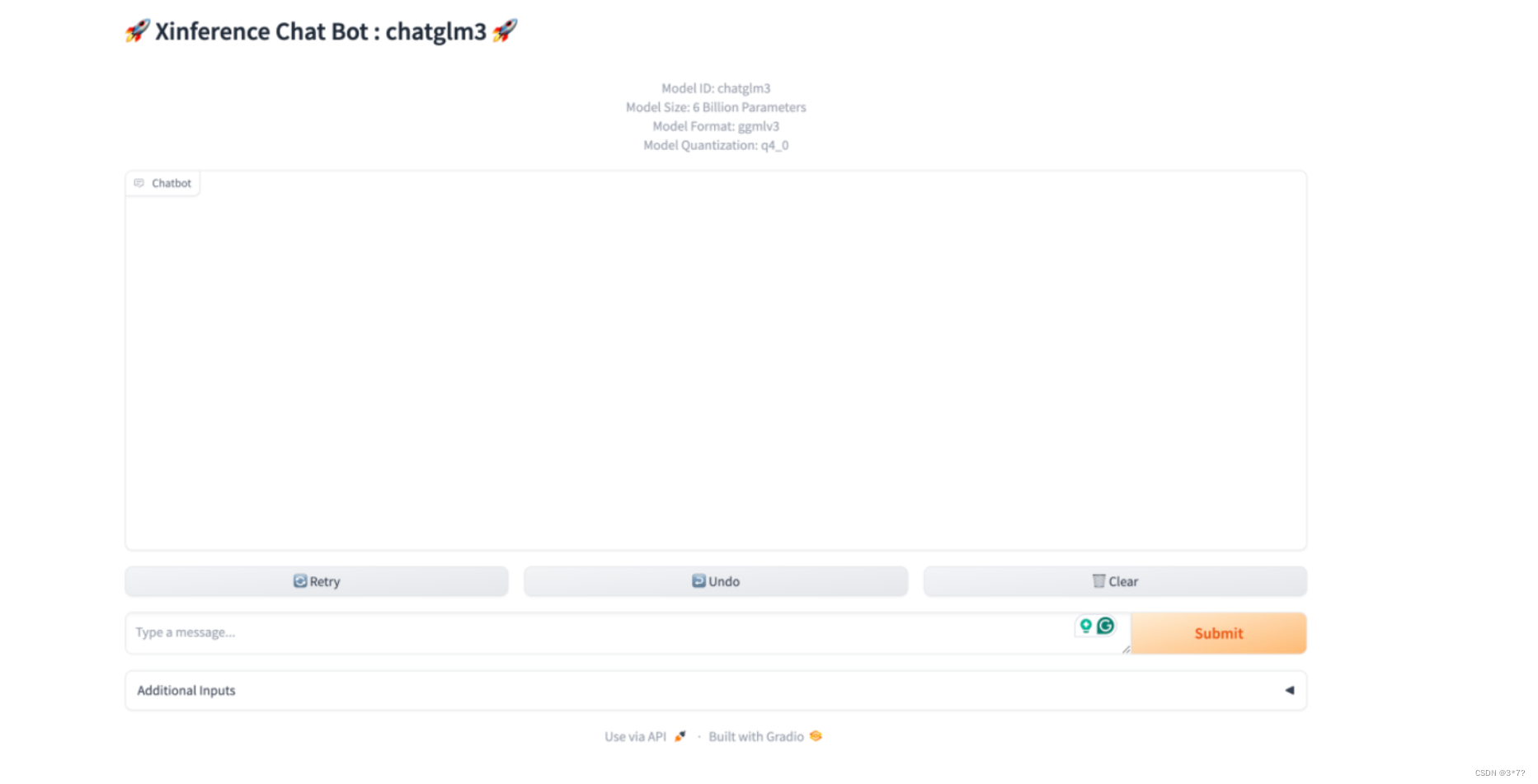
我们如果点击上图的红色方框图标Launch Web UI,浏览器会弹出 LLM 模型的 Web 界面,在这个界面中,你可以与 LLM 模型进行对话,界面如下:
API 接口
如果你不满足于使用 LLM 模型的 Web 界面,你也可以调用 API 接口来使用 LLM 模型,其实在 Xinference 服务部署好的时候,WebGUI 界面和 API 接口已经同时准备好了,在浏览器中访问http://localhost:9997/docs/就可以看到 API 接口列表。
接口列表中包含了大量的接口,不仅有 LLM 模型的接口,还有其他模型(比如 Embedding 或 Rerank )的接口,而且这些都是兼容 OpenAI API 的接口。以 LLM 的聊天功能为例,我们使用 Curl 工具来调用其接口,示例如下:
curl -X 'POST' \
'http://localhost:9997/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "chatglm3",
"messages": [
{
"role": "user",
"content": "hello"
}
]
}'
# 返回结果
{
"model": "chatglm3",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I help you today?",
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 8,
"total_tokens": 29,
"completion_tokens": 37
}
}
Embedding 模型
Embedding 模型是用来将文本转换为向量的模型,使用 Xinference 部署的话更加简单,只需要在Launch Model菜单中选择Embedding标签,然后选择相应模型,不像 LLM 模型一样需要选择参数,只需直接部署模型即可。
Rerank 模型
Rerank 模型是用来对文本进行排序的模型,使用 Xinference 部署的话也很简单,方法和 Embedding 模型类似。
IMAGE 模型
Xinference 还支持图像模型,使用图像模型可以实现文生图、图生图等功能。Xinference 内置了几种图像模型,分别是 Stable Diffusion(SD)的各个版本。部署方式和文本模型类似,都是在 WebGUI 界面上启动模型即可,无需进行参数选择,但因为 SD 模型比较大,在部署图像模型前请确保服务器上有 50GB 以上的空间。
CUSTOM 模型
语音模型是 Xinference 最近新增的功能,使用语音模型可以实现语音转文字、语音翻译等功能。在部署语音模型之前,需要先安装ffmpeg组件,以 Ubuntu 操作系统为例,安装命令如下:
sudo apt update && sudo apt install ffmpeg
目前 Xinference 还不支持在 WebGUI 界面上部署语音模型,需要通过命令行的方式来部署语音模型,在执行部署命令之前需要确保 Xinference 服务已经启动(xinference-local),部署命令如下:
xinference launch -u whisper-1 -n whisper-large-v3 -t audio
-u:表示模型 ID-n:表示模型名称-t:表示模型类型
命令行部署的方式不仅适用语音模型,也同样适用于其他类型的模型。我们通过调用 API 接口来使用部署好的语音模型,接口兼容 OpenAI 的 Audio API 接口,因此我们也可以用 OpenAI 的 Python 包来使用语音模型,示例代码如下:
import openai
# api key 可以随便写一个
client = openai.Client(api_key="not empty", base_url="http://127.0.0.1:9997/v1")
audio_file = open("/your/audio/file.mp3", "rb")
# 使用 openai 的方法来调用语音模型
completion = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
print(f"completion: {completion}")
audio_file.close()
模型来源
Xinference 默认是从 HuggingFace 上下载模型,如果需要使用其他网站下载模型,可以通过设置环境变量XINFERENCE_MODEL_SRC来实现,使用以下代码启动 Xinference 服务后,部署模型时会从Modelscope[5]上下载模型:
XINFERENCE_MODEL_SRC=modelscope xinference-local
模型独占 GPU
在 Xinference 部署模型的过程中,如果你的服务器只有一个 GPU,那么你只能部署一个 LLM 模型或多模态模型或图像模型或语音模型,因为目前 Xinference 在部署这几种模型时只实现了一个模型独占一个 GPU 的方式,如果你想在一个 GPU 上同时部署多个以上模型,就会遇到这个错误:No available slot found for the model。
管理模型
除了启动模型,Xinference 提供了管理模型整个生命周期的能力。同样的,你可以使用命令行:
列出所有 Xinference 支持的指定类型的模型:
xinference registrations -t LLM
列出所有在运行的模型:
xinference list
停止某个正在运行的模型:
xinference terminate --model-uid "chatglm3"
集群中部署、使用 Docker 部署、在 Kubernetes 环境中运行 Xinference请访问官网文档进行了解
推荐一款开源的项目:Langchain-Chatchat
Langchain-Chatchat(原 Langchain-ChatGLM)是一款基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,实现基于可扩展知识库的问答,开源、可离线部署的 RAG 与 Agent 应用项目。持市面上主流的开源 LLM、 Embedding 模型与向量数据库,可实现全部使用开源模型离线私有部署。与此同时,还支持 OpenAI GPT API 的调用。详细使用可点击标题跳转至官网了解。
0.3.x 版本功能一览
| 功能 | 0.2. | 0.3.x |
|---|---|---|
| 模型接入 | 本地:fastchat 在线:XXXModelWorker | 本地:model_provider,支持大部分主流模型加载框架 在线:oneapi 所有模型接入均兼容openai sdk |
| Agent | ❌不稳定 | ✅针对ChatGLM3和QWen进行优化,Agent能力显著提升 |
| LLM对话 | ✅ | ✅ |
| 知识库对话 | ✅ | ✅ |
| 搜索引擎对话 | ✅ | ✅ |
| 文件对话 | ✅仅向量检索 | ✅统一为File RAG功能,支持BM25+KNN等多种检索方式 |
| 数据库对话 | ❌ | ✅ |
| ARXIV文献对话 | ❌ | ✅ |
| Wolfram对话 | ❌ | ✅ |
| 文生图 | ❌ | ✅ |
| 本地知识库管理 | ✅ | ✅ |
| WEBUI | ✅ | ✅更好的多会话支持,自定义系统提示词… |
0.3.x 版本的核心功能由 Agent 实现,但用户也可以手动实现工具调用:
| 操作方式 | 实现的功能 | 适用场景 |
|---|---|---|
| 选中"启用Agent",选择多个工具 | 由LLM自动进行工具调用 | 使用ChatGLM3/Qwen或在线API等具备Agent能力的模型 |
| 选中"启用Agent",选择单个工具 | LLM仅解析工具参数 | 使用的模型Agent能力一般,不能很好的选择工具 想手动选择功能 |
| 不选中"启用Agent",选择单个工具 | 不使用Agent功能的情况下,手动填入参数进行工具调用 | 使用的模型不具备Agent能力 |
已支持的模型部署框架与模型
本项目中已经支持市面上主流的如 GLM-4-Chat 与 Qwen2-Instruct 等新近开源大语言模型和 Embedding 模型,这些模型需要用户自行启动模型部署框架后,通过修改配置信息接入项目,本项目已支持的本地模型部署框架如下:
| 模型部署框架 | Xinference | LocalAI | Ollama | FastChat |
|---|---|---|---|---|
| OpenAI API 接口对齐 | ✅ | ✅ | ✅ | ✅ |
| 加速推理引擎 | GPTQ, GGML, vLLM, TensorRT | GPTQ, GGML, vLLM, TensorRT | GGUF, GGML | vLLM |
| 接入模型类型 | LLM, Embedding, Rerank, Text-to-Image, Vision, Audio | LLM, Embedding, Rerank, Text-to-Image, Vision, Audio | LLM, Text-to-Image, Vision | LLM, Vision |
| Function Call | ✅ | ✅ | ✅ | / |
| 更多平台支持(CPU, Metal) | ✅ | ✅ | ✅ | ✅ |
| 异构 | ✅ | ✅ | / | / |
| 集群 | ✅ | ✅ | / | / |
| 操作文档链接 | Xinference 文档 | LocalAI 文档 | Ollama 文档 | FastChat 文档 |
| 可用模型 | Xinference 已支持模型 | LocalAI 已支持模型 | Ollama 已支持模型 | FastChat 已支持模型 |
备注:关于 Xinference 加载本地模型: Xinference 内置模型会自动下载,如果想让它加载本机下载好的模型,可以在启动 Xinference 服务后,到项目 tools/model_loaders 目录下执行 streamlit run xinference_manager.py,按照页面提示为指定模型设置本地路径即可.

















 7824
7824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









