






1.导入库函数
 2.导入数据
2.导入数据
 3.数据预处理
3.数据预处理
缺失值处理、异常值处理、相关性分析
print(student.isna().sum()) # 统计数据集各列缺失值个数
student.info() #来查看一下变量的数据类型
#相关性分析
most_correlated = student.corr().abs()['G3'].sort_values(ascending=False)
most_correlated = most_correlated[:13]
print(most_correlated)
df = df.drop([ 'G1', 'G2'], axis='columns')
df = pd.get_dummies(df)
# 选取相关性最强的11个
most_correlated = df.corr().abs()['G3'].sort_values(ascending=False)
most_correlated = most_correlated[:11]
print(most_correlated)
#热力图展示
df1=df[['G3', 'failures', 'Medu', 'higher_yes', 'higher_no', 'age', 'Fedu',
'goout', 'romantic_no', 'romantic_yes', 'traveltime']]
df_cor=df1.corr()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
plt.rcParams['figure.dpi'] = 100
plt.style.use('ggplot')
fig=plt.figure(figsize=(25,15),facecolor='w')
fig.add_subplot(111)
#Start Station 开始站
#end Station 终点站
sns.heatmap(data = df_cor, # 指定绘图数据
cmap = 'PuBuGn', # 指定填充色
linewidths = .5, # 设置每个单元格边框的宽度
annot = True, # 显示数值annot = True,
fmt = '2.3f', # 以科学计算法显示数据 fmt = ''
#cbar_kws={"orientation":"horizontal"},
annot_kws={"size":20}
)
#添加标题center=0.5,
plt.xticks(fontsize=20,rotation=20)
plt.yticks(fontsize=20,rotation=20)
plt.xlabel("前十个重要特征",fontsize=30)
plt.ylabel("前十个重要特征",fontsize=30)
plt.title('前十个特征之间的热力图',fontsize=30)
# 显示图形
plt.savefig("前十个特征之间的热力图.png")
warnings.filterwarnings("ignore") #过滤掉警告的意思 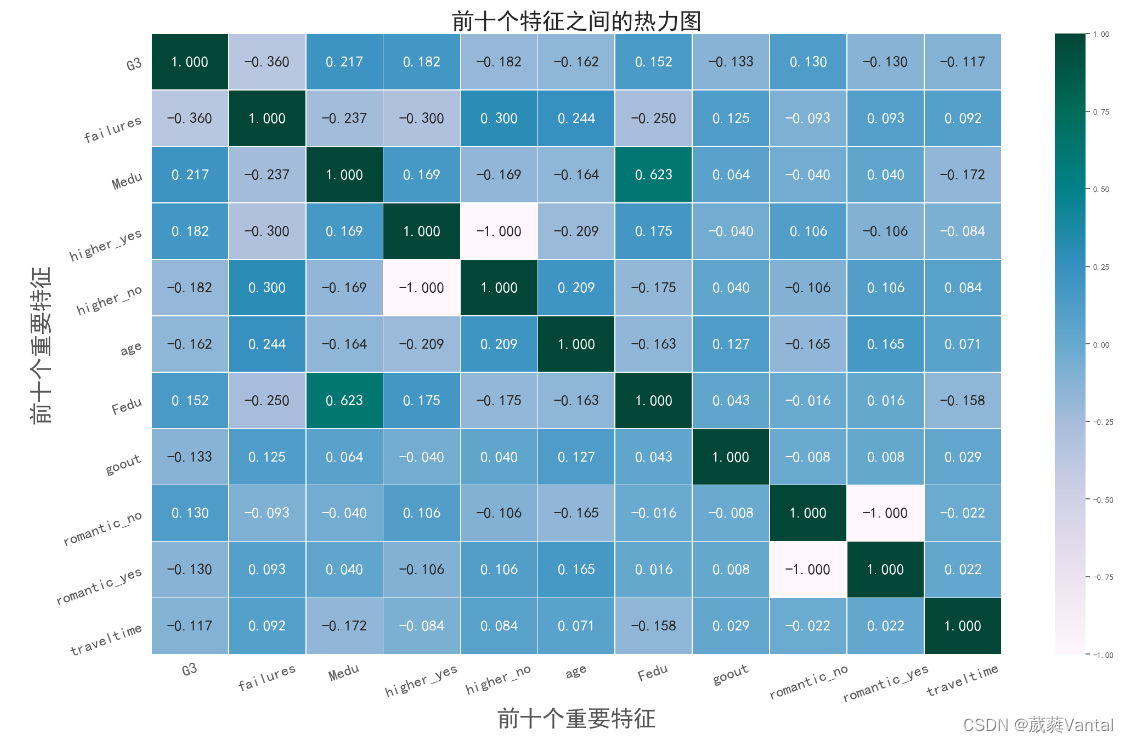
4.成绩可视化展示与分析
v=student.G3.value_counts() #查看该成绩值的分布
#print(type(v))
#print(v)
# 获取数据的值
#print(v.values)
# 获取索引的值
#print(v.index.tolist())
x1=list(v.values)
y1=list(v.index.tolist())
#print(x1,y1)
#柱状图
fig = plt.figure(figsize=(8, 6), facecolor='#B0C4DE')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
plt.rcParams['figure.dpi'] = 100
plt.rcParams['figure.figsize'] = (5,3)
plt.title("成绩分布柱状图")
plt.grid(ls="--", alpha=0.5)
plt.bar(y1, x1)
plt.legend(['数量'],loc="upper left",fontsize=16)
plt.xlabel('成绩',fontsize=15)
plt.ylabel('人数',fontsize=15)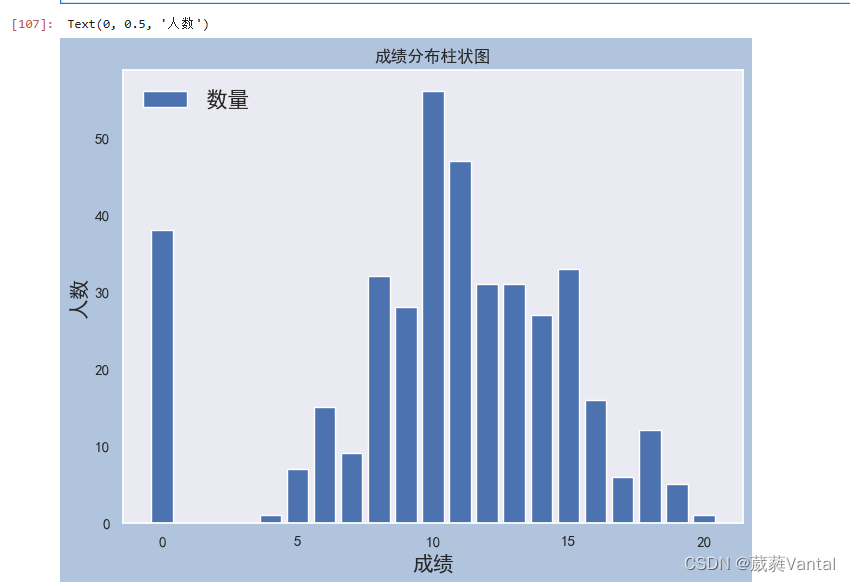
# 从低到高展示成绩分布图
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
grade_distribution = sns.countplot(student['G3'])
grade_distribution.set_title('成绩分布图', fontsize=20)
grade_distribution.set_xlabel('最终成绩', fontsize=15)
grade_distribution.set_ylabel('人数统计', fontsize=15)
plt.show() 
#学生年龄分析
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
# 分析年龄分布比例(曲线图)
age_distribution = sns.kdeplot(student['age'], shade=True)
age_distribution.axes.set_title('学生年龄分布图', fontsize=30)
age_distribution.set_xlabel('年龄', fontsize=20)
age_distribution.set_ylabel('比例', fontsize=20)
plt.show() 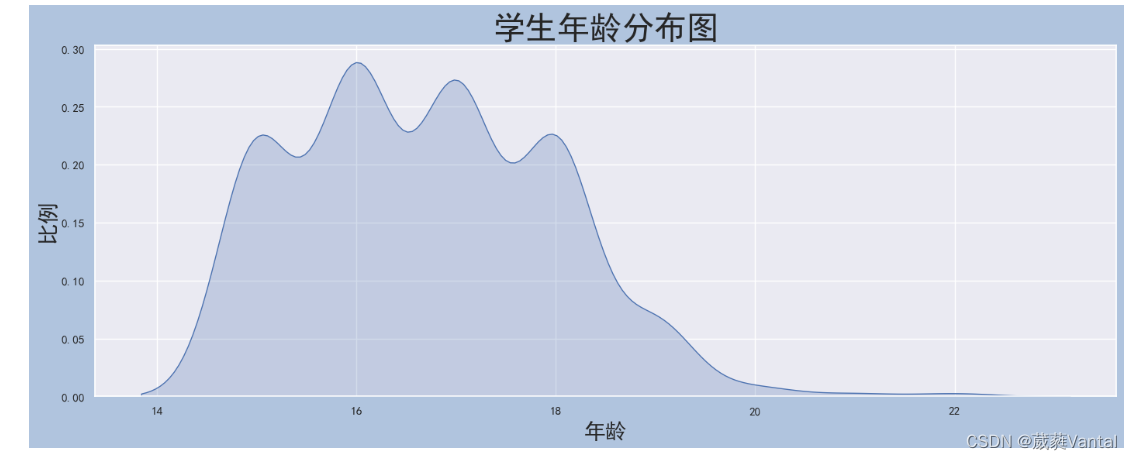
# 分性别年龄分布图(柱状图)
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
age_distribution_sex = sns.countplot('age', hue='sex', data=student,palette="Set3")
age_distribution_sex.axes.set_title('不同年龄段的学生人数', fontsize=30)
plt.legend(loc="upper right",fontsize=18)
age_distribution_sex.set_xlabel('年龄', fontsize=30)
age_distribution_sex.set_ylabel('人数', fontsize=30)
plt.show()
# x: x轴上的条形图,以x标签划分统计个数
# y: y轴上的条形图,以y标签划分统计个数
# hue: 在x或y标签划分的同时,再以hue标签划分统计个数 
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
# 各年龄段的成绩箱型图
age_grade_boxplot = sns.boxplot(x='age', y='G3', data=student)
age_grade_boxplot.axes.set_title('年龄与分数', fontsize = 20)
age_grade_boxplot.set_xlabel('年龄', fontsize = 15)
age_grade_boxplot.set_ylabel('分数', fontsize = 15)
plt.show()
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
# 各年龄段的成绩分布图
age_grade_swarmplot = sns.swarmplot(x='age', y='G3', data=student,size=8)
age_grade_swarmplot.axes.set_title('年龄与成绩', fontsize = 30)
age_grade_swarmplot.set_xlabel('年龄', fontsize = 20)
age_grade_swarmplot.set_ylabel('最终成绩G3', fontsize = 20)
plt.show()
# 城乡学生计数
areas_countplot = sns.countplot(student['address'])
areas_countplot.axes.set_title('城乡学生', fontsize = 30)
areas_countplot.set_xlabel('家庭住址', fontsize = 20)
areas_countplot.set_ylabel('计数', fontsize = 20)
plt.show()
# Grade distribution by ad
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
#plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei')
# Grade distribution by address
sns.kdeplot(student.loc[student['address'] == 'U', 'G3'], label='Urban', shade = True)
sns.kdeplot(student.loc[student['address'] == 'R', 'G3'], label='Rural', shade = True)
plt.title('城市学生获得了更好的成绩吗?', fontsize = 20)
plt.legend(fontsize = 20)
plt.xlabel('分数', fontsize = 15)
plt.ylabel('占比', fontsize = 15)
plt.show() 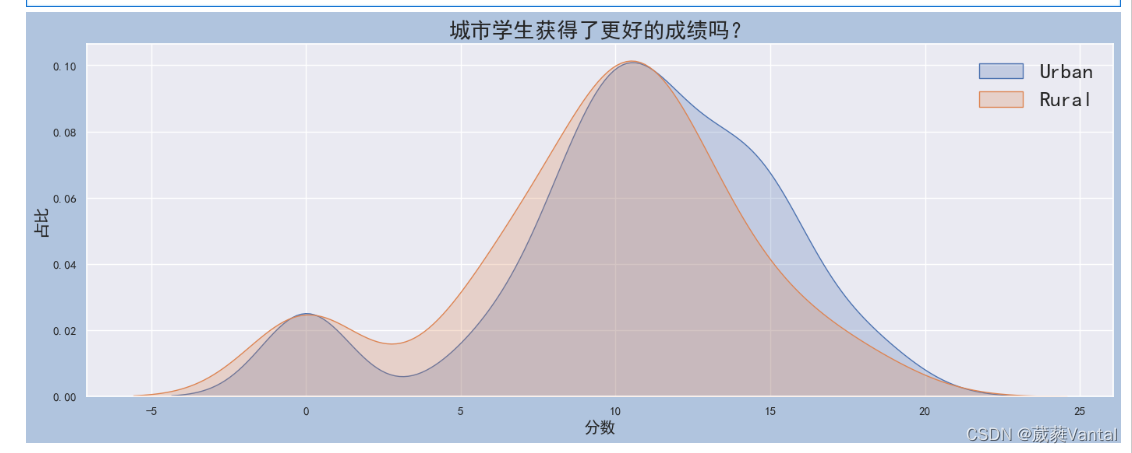
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
# 失败次数成绩分布图
failures_swarmplot = sns.swarmplot(x=student['failures'],y=student['G3'],size=8)
failures_swarmplot.axes.set_title('学生的失败次数', fontsize = 30)
failures_swarmplot.set_xlabel('失败次数', fontsize = 20)
failures_swarmplot.set_ylabel('最终成绩', fontsize = 20)
plt.show()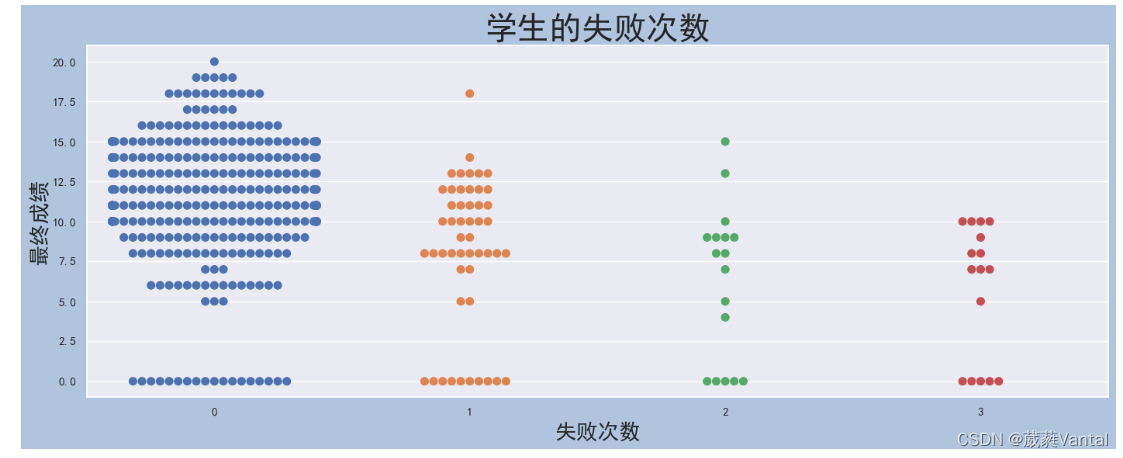
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
# 双亲受教育水平的影响
family_ed = student['Fedu'] + student['Medu']
family_ed_boxplot = sns.boxplot(x=family_ed,y=student['G3'])
family_ed_boxplot.axes.set_title('双亲受教育水平的影响', fontsize = 15)
family_ed_boxplot.set_xlabel('家庭教育水平', fontsize = 15)
family_ed_boxplot.set_ylabel('最终成绩', fontsize = 15)
plt.show()
#是否恋爱
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
ax1=plt.figure(figsize=(8,5),facecolor='#B0C4DE')
ax1=plt.subplot(111)
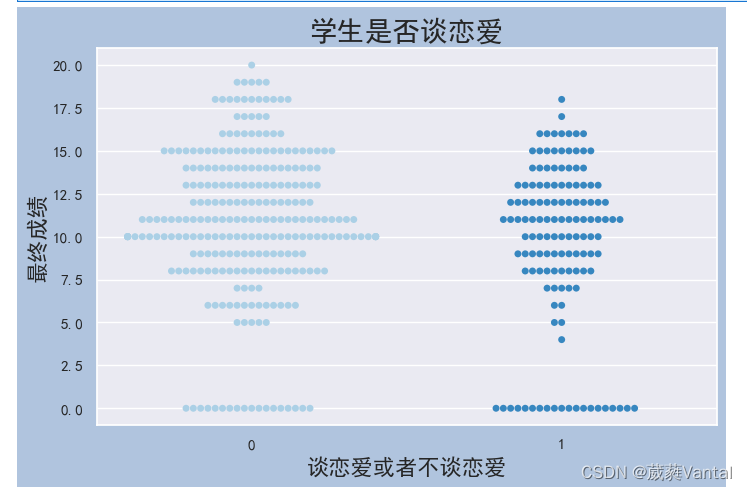
# 学生自己的升学意志对成绩的影响
romantic_swarmplot = sns.swarmplot(x = student['romantic_yes'], y=student['G3'],palette='Blues')
#personal_wish = sns.boxplot(x = student['romantic_yes'], y=student['G3'],palette='Blues')
romantic_swarmplot.axes.set_title('学生是否谈恋爱', fontsize = 20)
romantic_swarmplot.set_xlabel('谈恋爱或者不谈恋爱', fontsize = 16)
romantic_swarmplot.set_ylabel('最终成绩', fontsize = 16)
plt.show() 
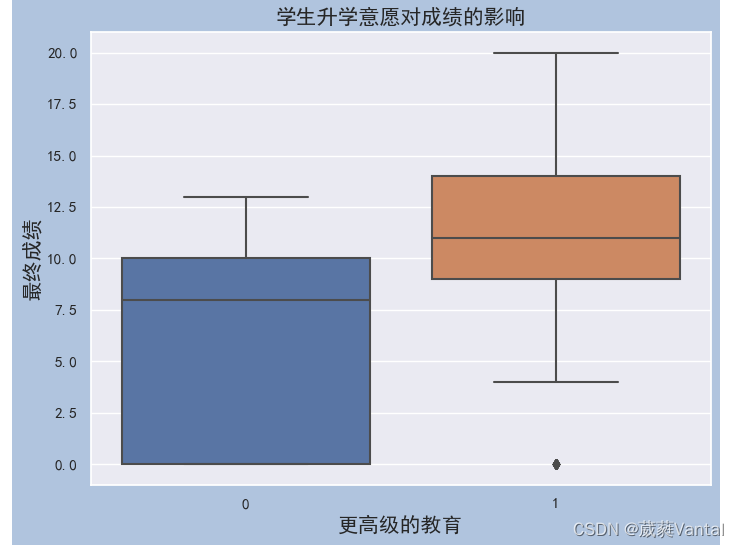
5.数据集切分
y=data["G3"]
x=data.drop(labels=["G1","G2","G3"],axis="columns")5.1.独热编码
# 选取G3属性值
labels = data["G3"]
# 删除school,G1和G2属性
data = data.drop(labels=["G1","G2","G3"],axis="columns")
# 对离散变量进行独热编码
data = pd.get_dummies(data)
#y = pd.get_dummies(y )5.2数据切分
X_train,X_test,y_train,y_test=train_test_split(data,y,test_size=0.15,random_state=42)6.模型对比
6.1XGboost
import xgboost as xgb
xgb_model = xgb.XGBRegressor() #调用
xgb_model.fit(X_train, y_train) # 拟合
y_pred4 = xgb_model.predict(X_test) # 预测
xgb_model.score(X_test,y_test)6.2 SVM
from sklearn.svm import SVC
model = SVC(kernel='linear', C=1000)
model.fit(X_train, y_train)
y_pred1 = model.predict(X_test)
model.score(X_test,y_test)6.3 随机森林
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators = 100, random_state = 0)
# 拟合数据集
clf = clf.fit(X_train, y_train)
y_pred2 = clf.predict(X_test)
print(clf.score(X_test,y_test))6.4 决策树
clf = tree.DecisionTreeClassifier(max_depth = 4) #创建DecisionTreeClassifier()类 分类器我们主要用回归模型 此处仅用来对比
clf = clf.fit(X_train, y_train) #使用数据,构建决策树
#dot_data = StringIO()
y_pred3=clf.predict(X_test)
#print(y_pred3)6.5 线性回归
model5=LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
model5=model5.fit(X_train,y_train)
y_pred5=model5.predict(X_test)7.模型评估
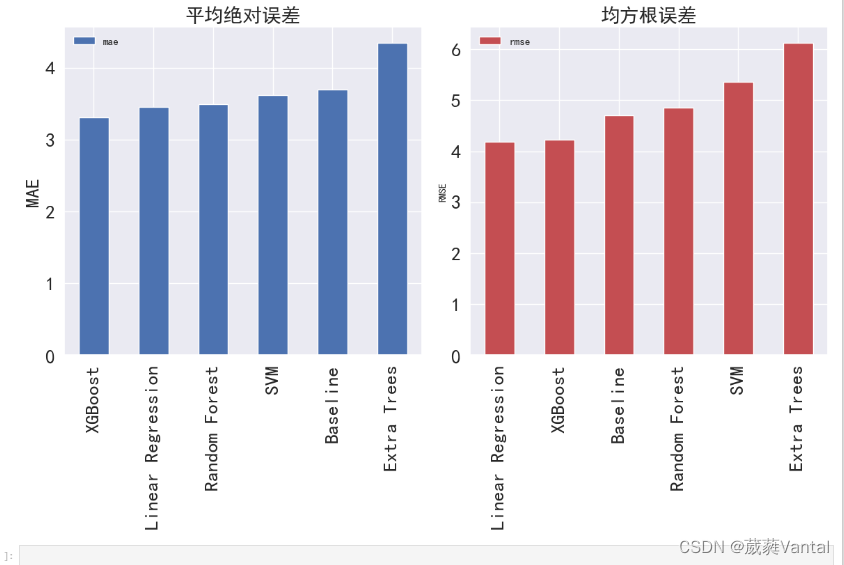
print('svm均方误差:{}'.format(round(metrics.mean_squared_error(y_test, y_pred1), 2)))
print('随机森林均方误差:{}'.format(round(metrics.mean_squared_error(y_test,y_pred2), 2)))
print('决策树均方误差:{}'.format(round(metrics.mean_squared_error(y_test,y_pred3), 2)))
print('xgboost均方误差:{}'.format(round(metrics.mean_squared_error(y_test,y_pred4), 2)))
print('线性回归均方误差:{}'.format(round(metrics.mean_squared_error(y_test,y_pred5), 2)))
#数据少,避免过拟合 泛化能力好,大数据要求拟合好model_list=['svm','随机森林','决策树','xgboost','线性回归']
model_msa=[]
model_msa.append(round(metrics.mean_squared_error(y_test, y_pred1), 2))
model_msa.append(round(metrics.mean_squared_error(y_test,y_pred2), 2))
model_msa.append(round(metrics.mean_squared_error(y_test,y_pred3), 2))
model_msa.append(round(metrics.mean_squared_error(y_test,y_pred4), 2))
model_msa.append(round(metrics.mean_squared_error(y_test,y_pred5), 2))
model_mea=[]
model_mea.append(round(metrics.mean_absolute_error(y_test, y_pred1), 2))
model_mea.append(round(metrics.mean_absolute_error(y_test,y_pred2), 2))
model_mea.append(round(metrics.mean_absolute_error(y_test,y_pred3), 2))
model_mea.append(round(metrics.mean_absolute_error(y_test,y_pred4), 2))
model_mea.append(round(metrics.mean_absolute_error(y_test,y_pred5), 2))
#print(model_mea)
fig = plt.figure(figsize=(10, 3), facecolor='#B0C4DE')
plt.subplot(121)
plt.title("五个模型均方误差")
plt.grid(ls="--", alpha=0.5)
plt.bar(model_list, model_msa)
plt.xticks(rotation=20) # 设置横坐标显示的角度
for a,b in zip(model_list,model_msa): #柱子上的数字显示
plt.text(a,b,'%.2f'%b,ha='center',va='bottom',fontsize=8)
plt.xlabel("模型",fontsize=15)
plt.ylabel(" 均方误差值",fontsize=15)
plt.subplot(122)
plt.title("五个模型平均绝对误差")
plt.grid(ls="--", alpha=0.5)
plt.bar(model_list, model_mea)
plt.xticks(rotation=20) # 设置横坐标显示的角度
for a,b in zip(model_list,model_mea): #柱子上的数字显示
plt.text(a,b,'%.2f'%b,ha='center',va='bottom',fontsize=8)
plt.xlabel("模型",fontsize=15)
plt.ylabel(" 平均绝对误差值",fontsize=15)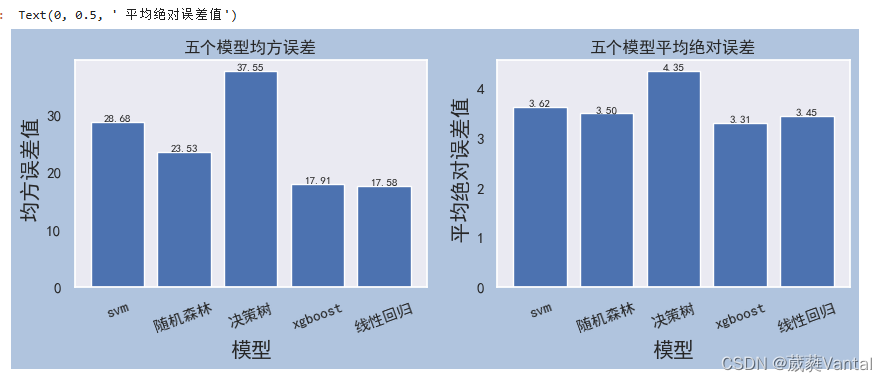
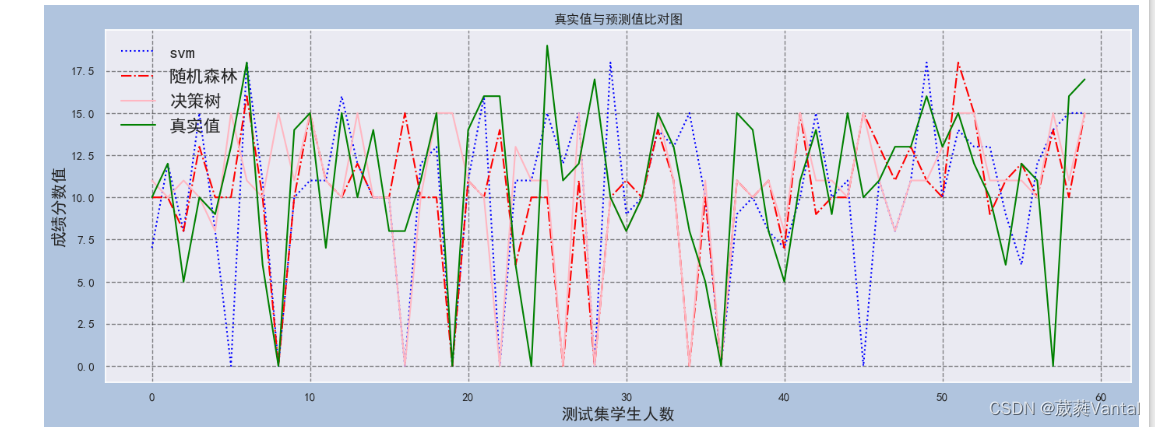
7.1 预测模型对比
ax1=plt.figure(figsize=(17,6),facecolor='#B0C4DE')
ax1=plt.subplot(111)
ax1.plot(range(y_test.shape[0]),y_pred1, color="blue", linewidth=1.5, linestyle="dotted",markersize=8)
ax1.plot(range(y_test.shape[0]),y_pred2, color="red", linewidth=1.5, linestyle="-.")
ax1.plot(range(y_test.shape[0]),y_pred3, color="lightpink", linewidth=1.5, linestyle="-")
ax1.plot(range(y_test.shape[0]),y_test, color="green", linewidth=1.5, linestyle="-")
plt.legend(['svm', '随机森林','决策树','真实值'],loc="upper left",fontsize=16)
plt.title("真实值与预测值比对图")
plt.grid(True,color='k',axis='both',ls='--',alpha=0.5)
plt.xlabel('测试集学生人数',fontsize=15)
plt.ylabel('成绩分数值',fontsize=15)
plt.savefig('预测值与真实值拟合.png')
 8.网格搜索算法训练模型参数
8.网格搜索算法训练模型参数
8.1训练XGboost模型参数
import multiprocessing
from sklearn.model_selection import GridSearchCV
#训练参数 训练模型最合适的参数
optimized_param = GridSearchCV(
xgb_model,
{"learn_rate":[0.05,0.04],"max_depth": [6,7,8,9,10,11], "n_estimators": [190,200]},
#'min_child_weight':[2,3,4]
# verbose=1,
# n_jobs=2, cv=5,
#error_score="raise"
) # 模型训练
optimized_param.fit(X_train, y_train) # 对应参数的k折交叉验证平均得分
means = optimized_param.cv_results_['mean_test_score']
params = optimized_param.cv_results_['params']
for mean, param in zip(means, params):
print("mean_score: %f, params: %r" % (mean, param)) # 最佳模型参数
print('参数的最佳取值:{0}'.format(optimized_param.best_params_))# 最佳参数模型得分
print('最佳模型得分:{0}'.format(optimized_param.best_score_))
# 模型参数调整得分变化曲线绘制
parameters_score = pd.DataFrame(params, means)
parameters_score['means_score'] = parameters_score.index
parameters_score = parameters_score.reset_index(drop=True)
parameters_score.to_excel('parameters_score.xlsx', index=False)
# grid_scores_ :给出不同参数情况下的评价结果
# best_params_ :描述了已取得最佳结果的参数的组合
# best_score_ :提供优化过程期间观察到的最好的评分
# 画图
plt.figure(figsize=(15, 12))
plt.subplot(2, 1, 1)
plt.plot(parameters_score.iloc[:, :-1], 'o-')
plt.legend(parameters_score.columns.to_list()[:-1], loc='upper left')
plt.title('Parameters_size', loc='center', fontsize='xx-large', fontweight='heavy')
plt.subplot(2, 1, 2)
plt.plot(parameters_score.iloc[:, -1], 'r+-')
plt.legend(parameters_score.columns.to_list()[-1:], loc='upper left')
plt.title('Score', loc='center', fontsize='xx-large', fontweight='heavy')
plt.savefig("迭代过程.png")
plt.show()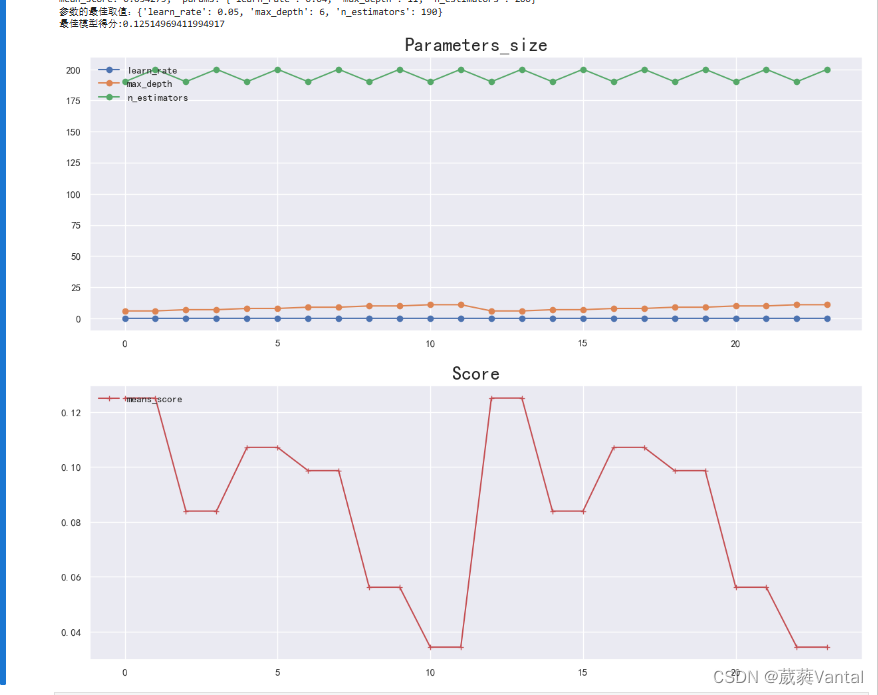
9.模型保存与调用
9.1 保存
XGB_model= xgb.XGBRegressor(max_depth=7, #树的深度
learning_rate=0.05, #步长
n_estimators=190, #迭代次数
objective='reg:squarederror',
booster='gbtree',
random_state=0)
# 拟合
XGB_model.fit(X_train, y_train)
filename = './model/XGB_Model' #保存为当前文件夹下model文件夹里面 命名XGB_Model
pickle.dump(model, open(filename, 'wb')) 9.2 调用
# 加载模型
with open('./model/XGB_Model', 'rb') as model:
# 反序列化对象模型 read b=二进制
loaded_model = pickle.load(model)















 4598
4598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









