






注意:数据由实习单位老师提供(需要自行搜索下载),页面美化为下载模板。
项目介绍:前端页面输入影响成绩的属性,预测出成绩,并作可视化展示——属性对成绩的影响。使用python pyspark 进行数据预处理、探索性数据分析可视化、调用模型、对比模、型调、优评估等。
成果展示:
1.页面功能展示
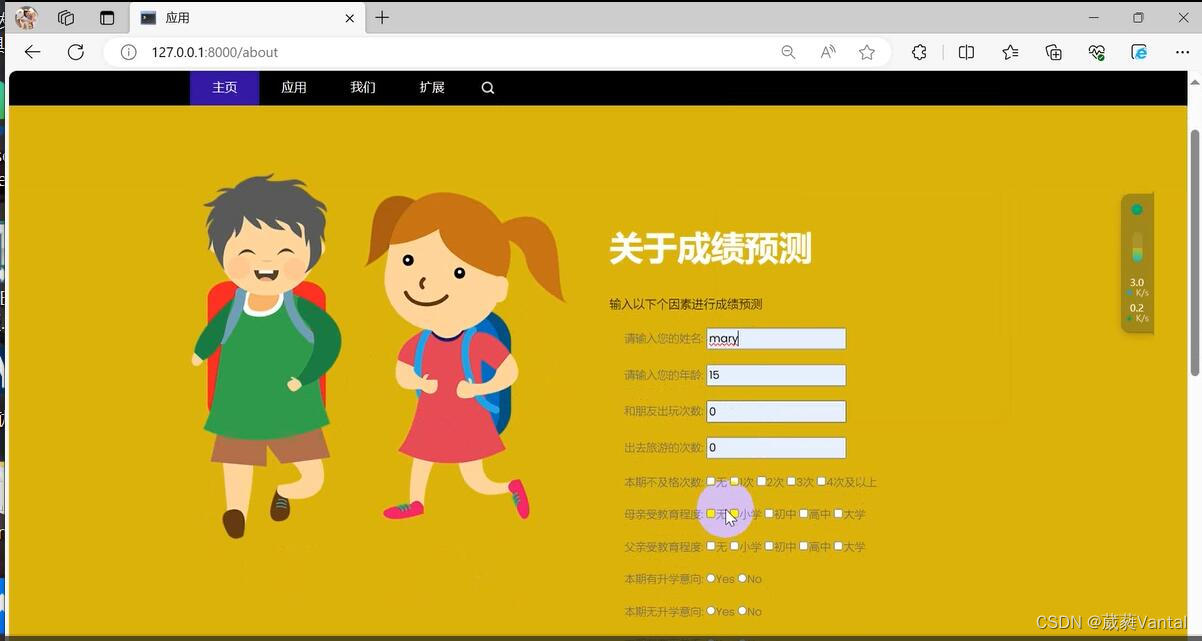
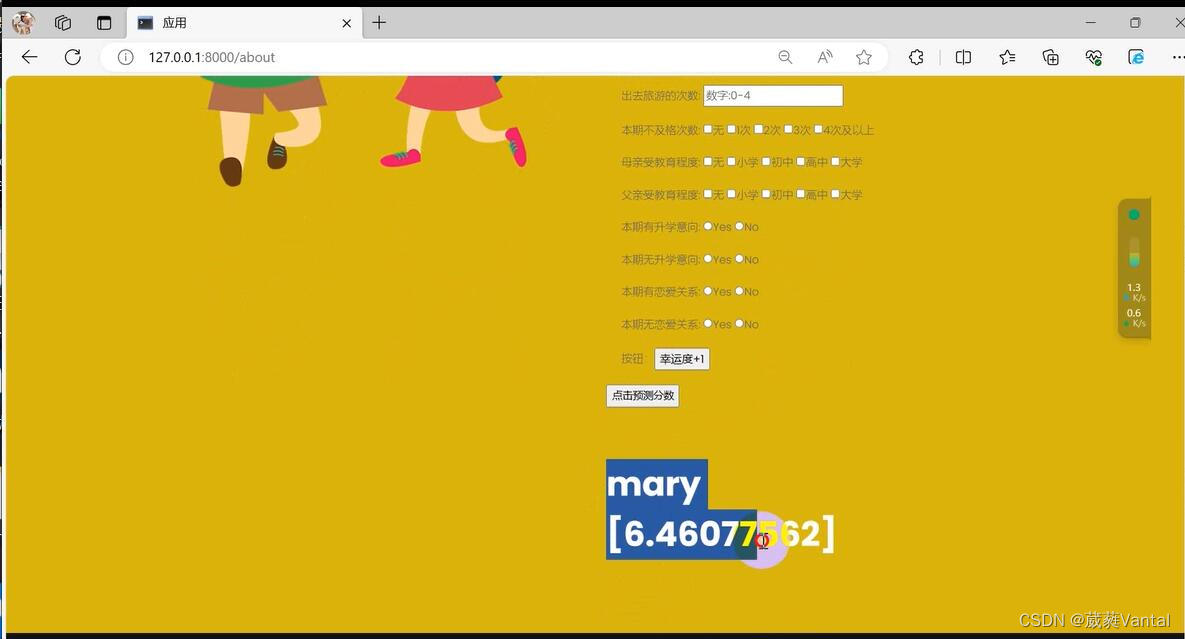
2.输入影响成绩因素值——预测成绩
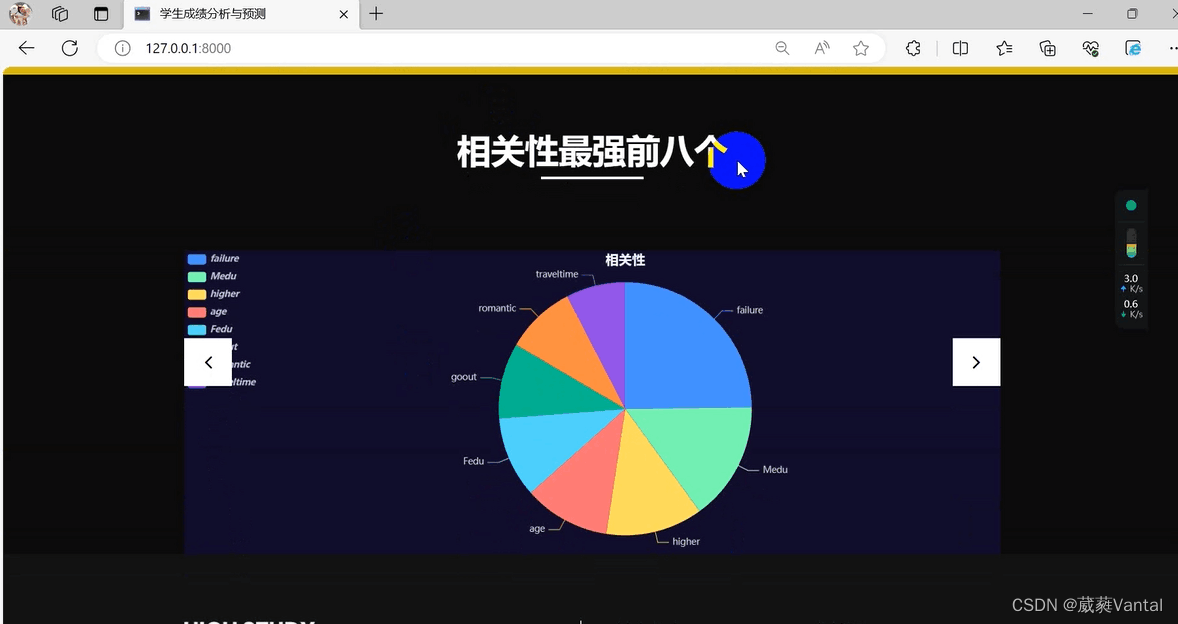
3.可视化部分
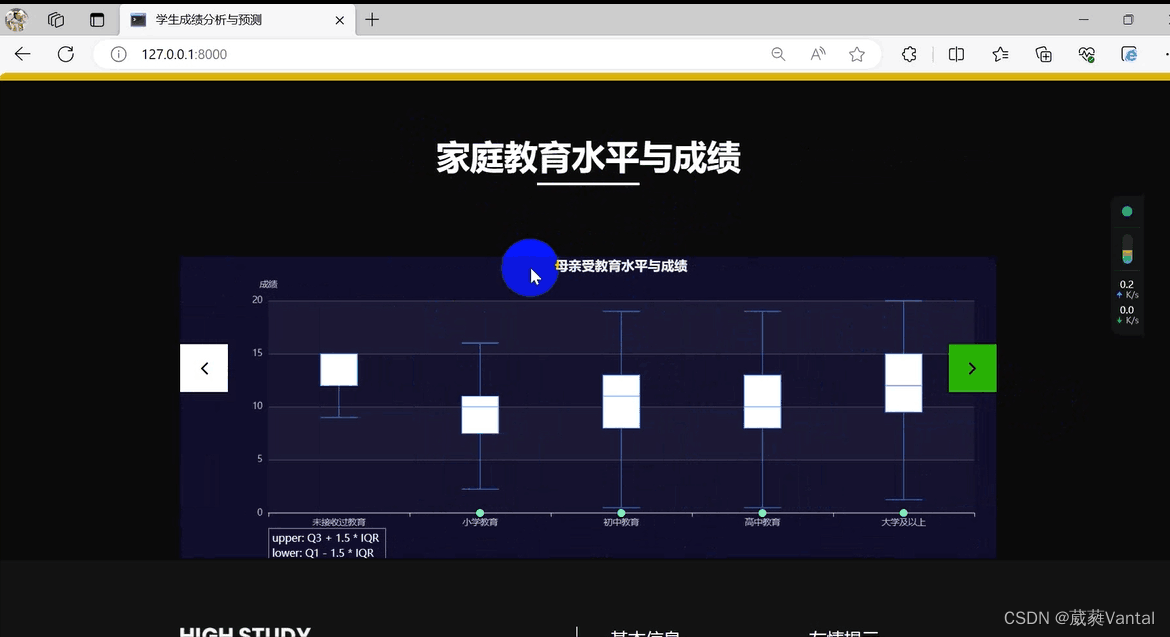
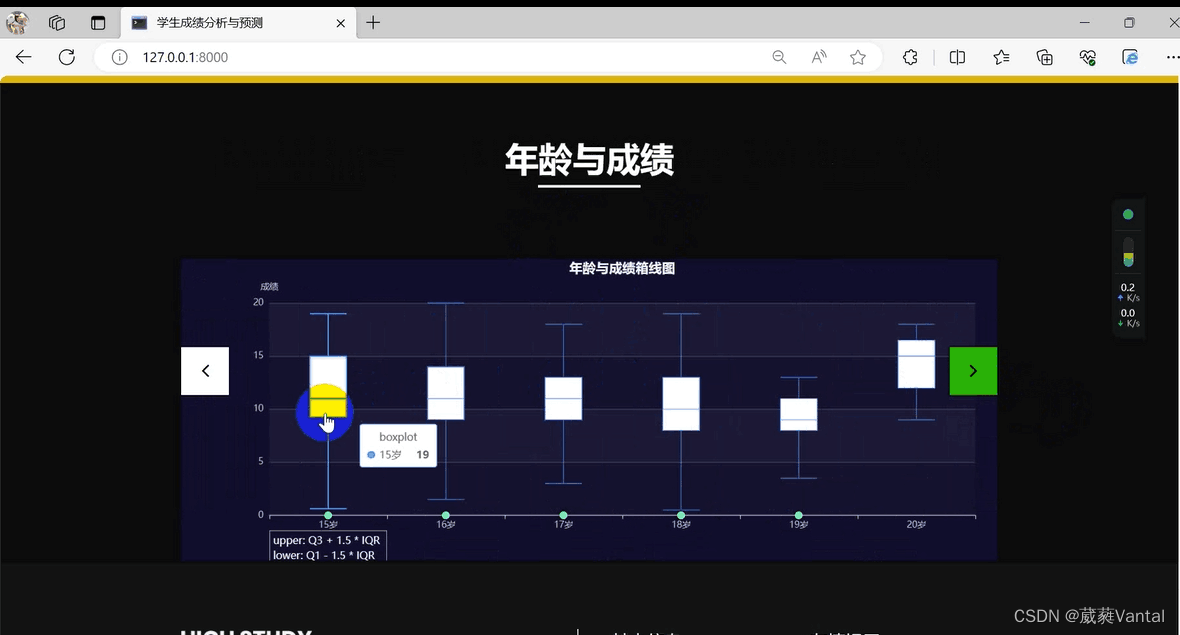
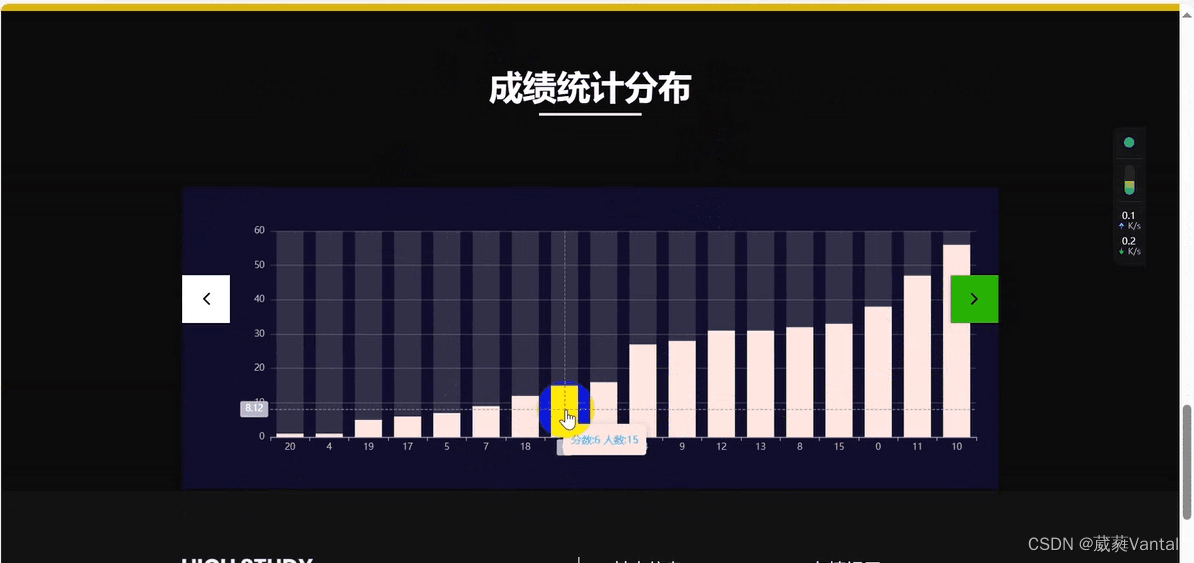
4.pyspark代码:
pandas编写:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from Cython import inline
from matplotlib.font_manager import FontProperties
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import ElasticNet
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn import preprocessing, metrics, svm
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn import preprocessing, metrics, svm
from sklearn.metrics import mean_squared_error, mean_absolute_error, median_absolute_error
import scipy
import pickle
import seaborn as sns
from sympy.physics.quantum.circuitplot import matplotlib
sns.set(font_scale=1.5)
import warnings
warnings.filterwarnings("ignore")
# 初始化数据
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
plt.rcParams['figure.dpi'] = 100
plt.rcParams['figure.figsize'] = (5,3)
plt.style.use('seaborn-darkgrid')
student = pd.read_csv('../data/student-mat.csv')
data = pd.read_csv('../data/student-mat.csv')
df=pd.read_csv('../data/student-mat.csv')
#print(df.columns)
#student["G3"].describe()
#print(student.isna().sum()) # 统计数据集各列缺失值个数
#student.info() #来查看一下变量的数据类型
most_correlated1 = student.corr().abs()['G3'].sort_values(ascending=False)
most_correlated1 = most_correlated1[:15]
print(most_correlated1)
student = pd.get_dummies(student)
#print(student.columns)
# 选取相关性最强的8个
most_correlated = student.corr().abs()['G3'].sort_values(ascending=False)
most_correlated = most_correlated[:15]
print(most_correlated)
y=data["G3"]
# 选取G3属性值
labels = data["G3"]
print(most_correlated.index)
# 删除school,G1和G2属性
data=data[['G3','failures', 'Medu', 'age','Fedu','goout','traveltime','romantic','higher']]
feature=data.columns
data = data.drop(labels=["G3"],axis="columns")
print(data)
# 对离散变量进行独热编码
data = pd.get_dummies(data)
print(data.columns)
#y = pd.get_dummies(y )
X_train,X_test,y_train,y_test=train_test_split(data,y,test_size=0.15,random_state=42)
model5=LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
model5=model5.fit(X_train,y_train)
y_pred5=model5.predict(X_test)
print('线性回归可解释方差值:{}'.format(round(metrics.explained_variance_score(y_test, y_pred5), 2)))
print('线性回归平均绝对误差:{}'.format(round(metrics.mean_absolute_error(y_test, y_pred5), 2)))
print('线性回归均方误差:{}'.format(round(np.sqrt(np.mean((y_pred5- y_test) ** 2)))))
print('线性回归 R方值:{}'.format(round(metrics.r2_score(y_test, y_pred5), 2)))
LR_model=LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
# 拟合
model=LR_model.fit(X_train, y_train)
filename = '../modelR/LR_Model' #保存为当前文件夹下model文件夹里面 命名XGB_Model
# 序列化 对象以二进制方式保存到硬盘 write, b=二进制
pickle.dump(model, open(filename, 'wb'))
# 加载模型
with open('../modelR/LR_Model', 'rb') as model:
# 反序列化对象模型 read b=二进制
loaded_model = pickle.load(model)
# print(X_test.head(1))
# 使用加载的模型进行预测
predictions = loaded_model.predict(X_test.head(5))
print(predictions)
ppyspark编写:
# -*- coding: utf-8 -*-
# 构建线性回归模型, labelCol,相对于featrues列,表示要进行预测的列
findspark.init()
spark = SparkSession.builder.master("local[*]").appName("student score") \
.enableHiveSupport().getOrCreate()
# 3.读取数据
dfStudentMat = spark.read \
.options(**options) \
.load('D:\python\spaak\data\student-mat.csv')
sc = spark.sparkContext
#实际数据集分割:
# 流水线,第一阶段为标签编码,第二阶段为独热编码
pipeline = Pipeline(stages=[stringIndexer, onehotenc])
# 添加数据
pipeline_fit = pipeline(dfStudentMat)
# 编码
enc_df = pipeline_fit.transform(dfStudentMat)
enc_df.show()
ind_val = ["school_ind", "sex_ind", "age_val"]
# 指定输入输出
v = VectorAssembler().setInputCols(ind_val).setOutputCol("features")
# 进行合并转换为一个特征字段:features
features_df = v.transform(enc_df)
print("------------ 2024.1.11 ----------")
features_df.show()
print("----------------------")
train, test = features_df.select(["features", "G3"]).randomSplit([0.85, 0.15])
train.describe('G3').show()
test.describe('G3').show()
train.show()
test.show()
lin_Reg = LinearRegression(labelCol='G3')
# 训练数据
lr_model = lin_Reg.fit(train)
# 使用预测数据,用已经到构建好的预测模型 lr_model
test_results = lr_model.evaluate(test)
# 查看预测的拟合程度
print('拟合度:{}'.format(test_results.r2))
# 查看均方误差
print('均方误差:{}'.format(test_results.meanSquaredError))
print('平均绝值误差:{}'.format(test_results.meanAbsoluteError))
#预测可视化:
# 构建线性回归模型, labelCol,相对于featrues列,表示要进行预测的列
lin_Reg = LinearRegression(labelCol='G3')
# 训练数据
lr_model = lin_Reg.fit(train)
# 使用预测数据,用已经到构建好的预测模型 lr_model
test_results = lr_model.evaluate(test)
# 查看预测的拟合程度
print('R方决定系数:{}'.format(test_results.r2))
# 查看均方误差
print('均方误差:{}'.format(test_results.meanSquaredError))
print('平均绝值误差:{}'.format(test_results.meanAbsoluteError))
print('均方根误差:{}'.format(test_results.rootMeanSquaredError))
predictions = lr_model.transform(test)
predictions.show()
print(predictions.toPandas())
data = predictions.toPandas()
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='whitegrid')
plt.figure(figsize=(12, 5))
plt.plot(data["prediction"])
plt.plot(data["G3"])
# plt.xlim(0, 2000)
plt.legend(['predict', 'actual'])
plt.show()
#保存模型与预测:
lr_model.save("./model/pyspark_LR_Model")
#预测:
# 1.导入训练好的Spark ML模型
model = LinearRegressionModel.load("./model/pyspark_LR_model")
# 将获取的第一条数据转换为DF
# row_df = spark.createDataFrame(features_df.head(1), schema=["features", "G3"])
# row_df.show()
train, test = features_df.select(["features", "G3"]).randomSplit([0.9, 0.1])
data = test.head(1)
# 将第一行格式化为DataFrame
row_df = spark.createDataFrame(data, schema=["features", "G3"])
row_df.show()
predictions = model.transform(row_df)
predictions["G3", "prediction"].show()














 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









