 Amazon Aurora数据库特性与安全机制
Amazon Aurora数据库特性与安全机制





Amazon Aurora

Amazon Aurora 是一款完全托管式关系数据库引擎,专为云端打造,与 MySQL 和 PostgreSQL 兼容。Amazon Aurora 是 Amazon RDS 的一部分。
separation of storage and compute
- Aurora is a proprietary technology from AWS (not open sourced)
- Postgres and MySQL are both supported as Aurora DB (that means your drivers will work as if Aurora was a Postgres or MySQL database)
- Aurora被称为“AWS云优化”,声称相比RDS上的MySQL,性能提高了5倍,比RDS上的PostgreSQL性能提高了3倍。
- Aurora存储会自动以10GB为增量增长,最高可达128TB。
- Aurora最多可以有**15个raplica,而MySQL只能有5个,**并且复制过程更快(副本延迟低于10毫秒)。
- Aurora的故障切换是即时的。它具有本地高可用性(High Availability)。
- Aurora的成本比RDS更高(高出20%),但更高效。
Aurora High Availability and Read Scaling
- 数据在3个AZ中有6个copies:
- 对于写入,需要6个副本中的4个。
- 对于读取,需要6个副本中的3个。
- 使用点对点复制实现自动修复。
- 存储跨数百个卷进行条带化(striped)。
- 一个Aurora实例用于写入(master)。
- automated failover for instance for master in less then 30s
- 主实例和最多15 Aurora Read Replicas serve用于读取服务。
- 支持跨区域复制(Cross Region Replication)。
Aurora DB Cluster

Aurora replicas -auto scaling

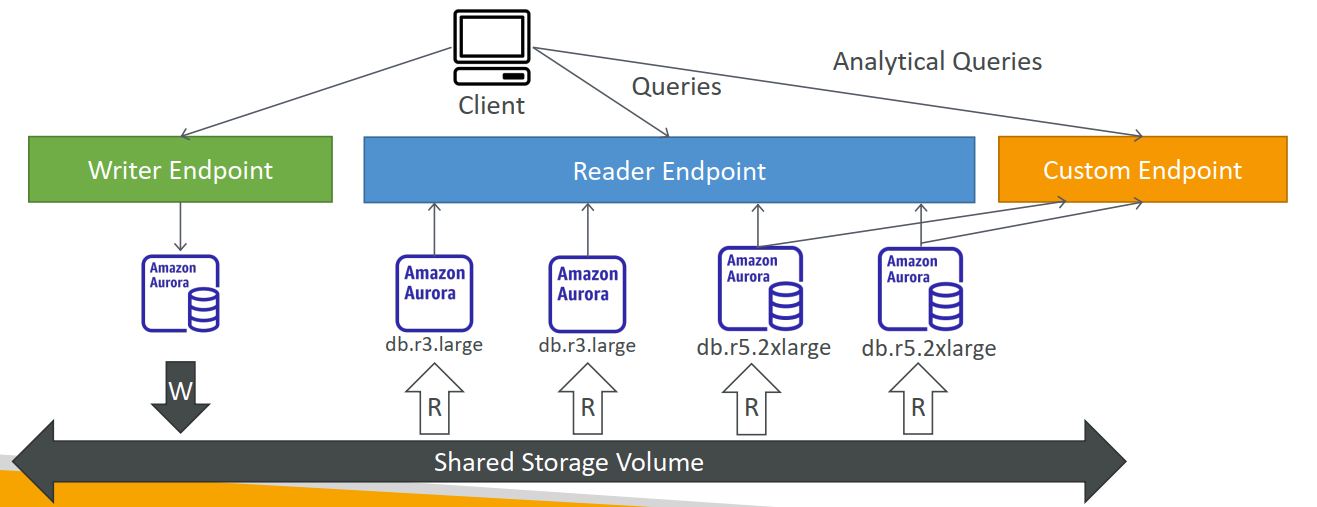
Aurora – Custom Endpoints
- 将一组Aurora实例定义为自定义终端节点。
- 示例:在特定副本上运行分析查询。
- 在定义自定义终端节点后,通常不再使用读取终端节点(Reader Endpoint)。
Aurora serverless
可以根据实际负载需求自动调整数据库的计算容量,从而实现按需自动缩放。
- 自动扩展和缩减:Aurora Serverless可以根据负载自动增加或减少计算容量,确保数据库能够高效地处理变化的工作负载,同时最大程度地降低成本。
- 无需管理实例大小:用户无需手动配置数据库实例的大小,Aurora Serverless会自动处理资源调整。
- 暂停和恢复功能:当数据库不活动时,Aurora Serverless可以自动暂停实例,从而节省资源并降低成本。一旦有查询请求或数据库活动,它会快速恢复并处理请求。
- 基于秒级的计费:Aurora Serverless按照数据库使用的秒数进行计费,这意味着您只需支付实际使用的资源量。
Aurora Multi-master
传统的数据库系统通常只有一个主节点,所有写入操作都要经过该主节点处理,这可能会成为瓶颈并限制数据库的写入吞吐量。而Aurora Multi-Master则允许多个主实例并行处理写入请求,从而显著提高了数据库的写入性能和容量。
主要特点如下:
- 多主节点:Aurora Multi-Master允许在Aurora集群中配置多个主节点,每个主节点都可以处理写入请求。
- 并行写入:由于有多个主节点,写入操作可以并行处理,这样大大提高了数据库的写入吞吐量。
- 高可用性:每个主节点都具有独立的网络和存储,因此即使某个主节点发生故障,其他主节点仍然可以继续处理写入请求,确保数据库的高可用性。
- 读取负载均衡:Aurora Multi-Master还支持读取负载均衡,多个主节点可以处理读取请求,从而进一步提高数据库的读取性能。
Aurora Multi-Master适用于高写入负载的场景,例如大规模的写入操作、高并发的写入请求或需要实时同步多个数据源的应用程序。通过允许多个主节点处理写入请求,Aurora Multi-Master提供了更高的可伸缩性和性能,使得数据库可以更好地适应大规模的写入操作。
Global Aurora
Aurora multi-AZ replicas:用于disaster recovery
这种设置适用于非常关键的应用程序,因为它提供了最小的故障恢复时间,但它并不提供在另一个区域中实时写入的能力。
-
- 每个辅助区域最多16个 read replica
- 有助于降低延迟
- 将另一个区域提升为主要区域(用于灾难恢复)的恢复时间目标(RTO)小于1分钟
- replicate data across-region takes less than 1s
Aurora Database Cloning
create a new aurora DB cluster from an existing one
faster than snapshot & restore
- 快速创建准确副本:Aurora数据库克隆使用现有数据库的快照创建副本,因此它是原始数据库的准确复制。这个过程是非常快速的,不需要从头开始复制和创建数据库。
- 节省时间和资源:通过克隆,您无需手动配置新的数据库实例,从头开始加载数据,或者执行其他复杂的操作。这节省了时间和资源,使得数据库克隆非常便捷。
- 测试和开发:Aurora数据库克隆非常适合用于测试和开发环境。您可以创建数据库的克隆副本,并在测试或开发环境中使用它,而不影响生产环境的数据库。
- 数据分析和报告:您可以使用克隆数据库来进行数据分析、生成报告以及运行复杂查询,而无需在生产数据库上执行这些操作,从而减少生产数据库的负担。
- 数据库快照:数据库克隆是基于现有数据库的快照创建的。因此,在克隆数据库上执行的任何更改不会影响原始数据库

RDS & Aurora Security
1 **-**静态加密(At rest encryption)
- 可以使用AWS KMS(Key Management Service)的AES-256加密,对主数据库和只读副本进行加密。
- 加密必须在启动时定义。
- 如果主数据库未加密,则无法对只读副本进行加密。
- 对已存在的未加密数据库进行加密,可以通过创建数据库快照,并在恢复时选择使用加密方式进行恢复,以实现加密功能
2-动态加密(In-flight encryption)
- 默认支持TLS,客户端使用AWS TLS根证书
3.安全组(Security Groups):
控制对RDS / Aurora数据库的网络访问
4-IAM Authentication(身份验证)
使用IAM角色连接数据库(而非用户名/密码)


















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









