







Python爬虫系列
本节重点讲对Python爬虫的了解和爬虫前奏需要准备什么。
爬虫实现资源自由
前言
本文主要讲解一下关于爬虫的相关前置知识和一些理论性的知识,通过本问能够知道什么是爬虫,都有那些分类,爬虫能干什么等,同时还会站在爬虫的角度讲解一下http协议。相对来说对小白比较友好。
爬虫前奏
1. 爬虫是什么
本质是模拟浏览器,向网页发出请求,并获取响应。
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端(主要指浏览器)发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
- 原则上,只要是客户端(浏览器)能做的事情,爬虫都能够做
- 爬虫也只能获取客户端(浏览器)所展示出来的数据
2. 学习爬虫需要什么
使用chrome浏览器
一门高级语言基础,如python,c,c++,java等。
每一门高级语言都是可以写爬虫的,由于Python语言的优点,写爬虫是最好的选择,推荐使用Python。本文以使用Python来讲解。
2.1 首先需要一定的Python编程基础
- 面向对象编程
- 文件操作
- 异常处理
- 模块和包
2.2 具有一定的网页知识
- html,css,js(能够看懂就行)
- 了解http协议
爬虫简介
1. 爬虫的作用
爬虫在互联网世界中有很多的作用,比如:
-
- 抓取微博评论(机器学习舆情监控)
- 抓取招聘网站的招聘信息(数据分析、挖掘)
- 新浪滚动新闻
- 百度新闻网站
-
网站上的投票
-
网络安全
2. 爬虫的分类
2.1 根据被爬取网站的数量不同,可以分为:
- 通用爬虫,如 搜索引擎
- 聚焦爬虫,如12306抢票,或专门抓取某一个(某一类)网站数据
2.2 根据是否以获取数据为目的,可以分为:
- 功能性爬虫,给你喜欢的明星投票、点赞
- 数据增量爬虫,比如招聘信息
2.3 根据url地址和对应的页面内容是否改变,数据增量爬虫可以分为:
-
基于url地址变化、内容也随之变化的数据增量爬虫
-
url地址不变、内容变化的数据增量爬虫
爬虫流程
以下是爬虫的基本流程
- 获取一个url
- 向url发送请求,并获取响应(需要http协议)
- 如果从响应中提取url,则继续发送请求获取响应
- 如果从响应中提取数据,则将数据进行保存
从爬虫角度分析了解HTTP协议
http和爬虫的关系:
由此图可看出发送请求获取响应要依赖于http/https协议。
http协议和https协议的区别
- HTTP:超文本传输协议,默认端口号是80端口
- 超文本:是指超过文本,不仅限于文本;它还包括图片、音频、视频等等各种文件
- 传输协议:是指用户和浏览器使用共用约定的一种固定格式来传递转换成字符串的超文本内容
- HTTPS:HTTP + SSL(安全套接字层),即带有安全套接字层的超本文传输协,默认端口号:443
- SSL对传输的内容(超文本,也就是请求体或响应体)进行加密
- 可以打开浏览器访问一个url,右键检查,点击net work,点选一个url,查看http协议的形式
爬虫重点关注的内容
1. 请求头
特别关注的请求头字段,http请求的形式如图所示
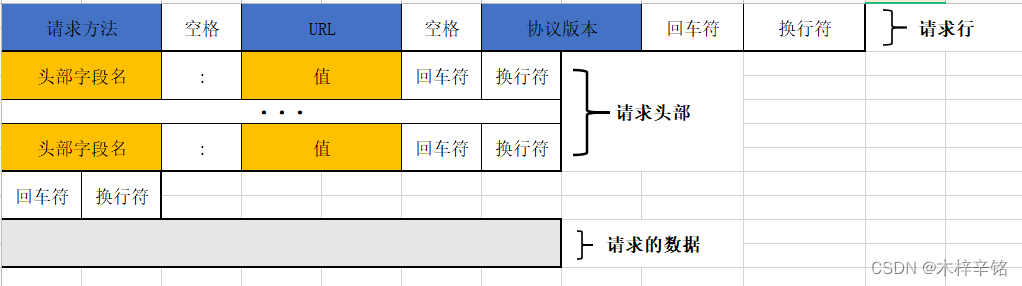
2.爬虫特别关注的请求头字段(重点)
- Content-Type
- Host (主机和端口号)
- Connection (链接类型)
- Upgrade-Insecure-Requests (升级为HTTPS请求)
- User-Agent (浏览器名称)
- Referer (页面跳转处)
- Cookie (Cookie)
- Authorization(用于表示HTTP协议中需要认证资源的认证信息)
重点关注标黄字段
标黄的请求头为常用请求头,在服务器被用来进行爬虫识别的频率最高,相较于其余的请求头相对来说更为重要,但是这里需要注意的是并不意味这其余的不重要,因为有的网站的运维或者开发人员可能比较特别,会使用一些比较不常见的请求头,判断到底是不是爬虫。
3.响应头
这里以百度为例
如图右键–>点击检查
点击network
点击刷新就出现如下图信息–>点击www.baidu.com
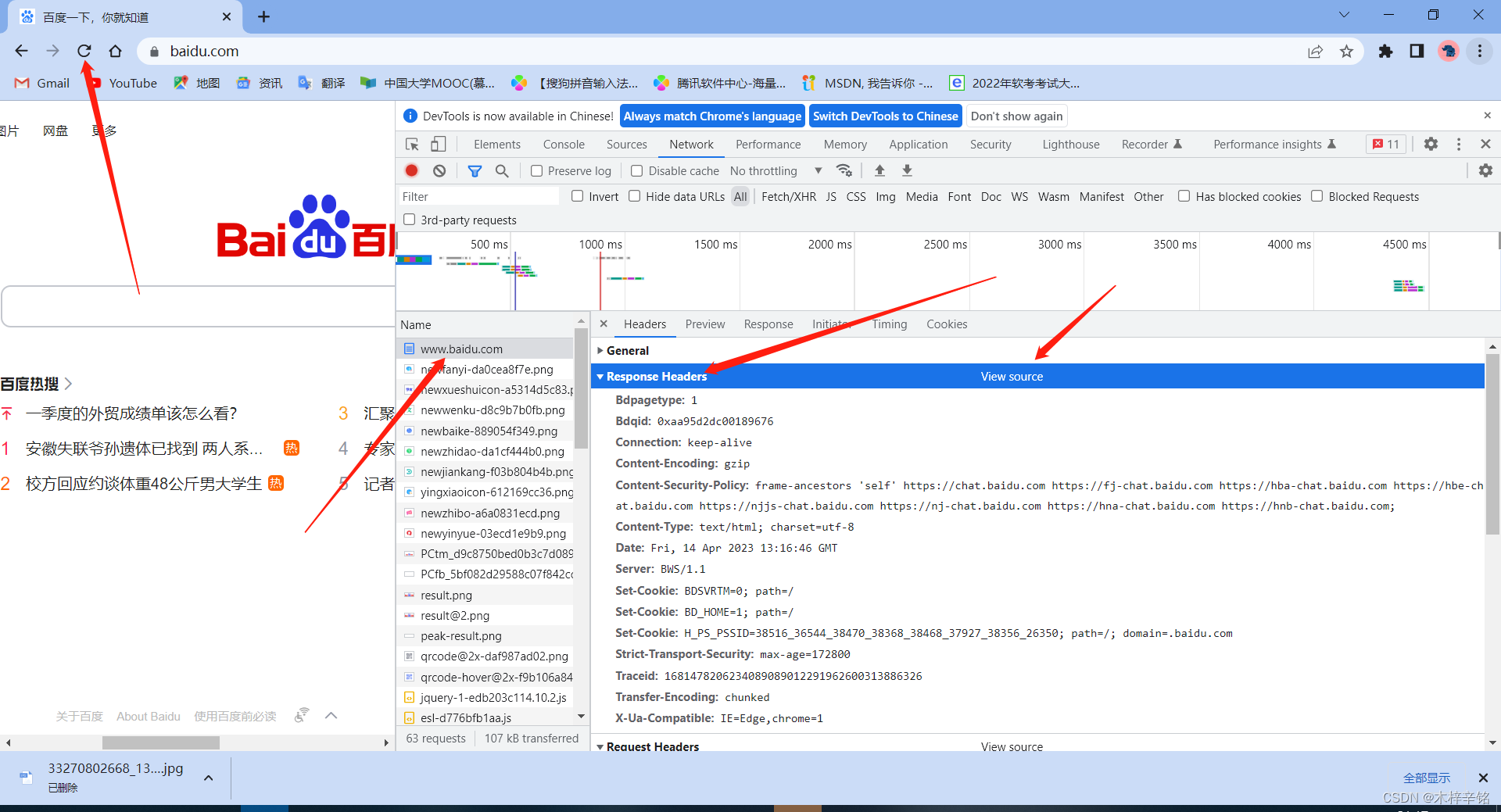
点击右边上方的Requests Header右边的View Source后出现如下信息
以下就是http响应头字段,爬虫只关注一个响应头字段
- Set-Cookie (对方服务器设置cookie到用户浏览器的缓存)
HTTP/1.1 200 OK
Bdpagetype: 1
Bdqid: 0xaa95d2dc00189676
Connection: keep-alive
Content-Encoding: gzip
Content-Security-Policy: frame-ancestors ‘self’ https://chat.baidu.com https://fj-chat.baidu.com https://hba-chat.baidu.com https://hbe-chat.baidu.com https://njjs-chat.baidu.com https://nj-chat.baidu.com https://hna-chat.baidu.com https://hnb-chat.baidu.com;
Content-Type: text/html; charset=utf-8
Date: Fri, 14 Apr 2023 13:16:46 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=38516_36544_38470_38368_38468_37927_38356_26350; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Traceid: 1681478206234089089012291962600313886326
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
- 上方讲到标黄重点和下方数据中的标黄字段相对应
右边下方Requests Headers的数据如下:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cache-Control: max-age=0
Connection: keep-alive
Cookie: BIDUPSID=B77DBC89F3ECAAA32C981142D6DA7EAF; PSTM=1661167409; BAIDUID=B77DBC89F3ECAAA31EBFBDFF91ED5E2C:FG=1; BAIDUID_BFESS=B77DBC89F3ECAAA31EBFBDFF91ED5E2C:FG=1; BD_UPN=12314753; ZFY=JfHvDmZwcK6ZoiHz5romhdFgye:AxMXJqX7EEdu9JRPM:C; B64_BOT=1; channel=baidusearch; baikeVisitId=516d9b95-aaab-458b-a86c-28dd1ebcf05a; COOKIE_SESSION=2_4_6_6_2_8_1_0_6_6_1_1_54436_1_4_0_1661316438_1661224190_1661316434%7C6%230_4_1661224160%7C1; BD_HOME=1; H_PS_PSSID=38516_36544_38470_38368_38468_37927_38356_26350; BA_HECTOR=2g252gakag8g0g2g8h21841i1i3ik3u1m
Host: www.baidu.com
sec-ch-ua: “Chromium”;v=“112”, “Google Chrome”;v=“112”, “Not:A-Brand”;v=“99”
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: “Windows”
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
4.关键的响应状态码
| 状态码 | 含义 |
|---|---|
| 200 | 成功 |
| 302 | 跳转,新的url在响应的Location头中给出 |
| 303 | 浏览器对于POST的响应进行重定向至新的url |
| 307 | 浏览器对于GET的响应重定向至新的url |
| 403 | 资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限) |
| 404 | 找不到该页面 |
| 500 | 服务器内部错误 |
| 503 | 服务器由于维护或者负载过重未能应答,在响应中可能可能会携带Retry-After响应头;有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码 |
重点:爬虫和web的区别
学过web的就学过一定的状态码相关知识,那么问题来了我们知道这是服务器给我的相关反馈,在学习web的时候就应该将真实情况反馈给客户端,但是在爬虫中,可能该站点的开发人员或者运维人员为了阻止数据被爬虫轻易获取,可能在状态码上做手脚(即反爬手段),也就是说返回的状态码并不一定就是真实情况,比如:服务器已经识别出你是爬虫,但是为了让你疏忽大意,所以照样返回状态码200,但是响应体重并没有数据。
切记:
所有的状态码都不可信,一切以是否从抓包得到的响应中获取到数据为准
浏览器的运行过程
http在浏览器的详细请求过程
http请求过程:
- 浏览器在拿到域名对应的ip后,先向地址栏中的url发起请求,并获取响应
- 在返回的响应内容(html)中,会带有css、js、图片等url地址,以及ajax代码,浏览器按照响应内容中的顺序依次发送其他的请求,并获取相应的响应
- 浏览器每获取一个响应就对展示出的结果进行添加(加载),js,css等内容会修改页面的内容,js也可以重新发送请求,获取响应
- 从获取第一个响应并在浏览器中展示,直到最终获取全部响应,并在展示的结果中添加内容或修改————这个过程叫做浏览器的渲染
注意:
在爬虫中,爬虫只会请求url地址,对应的拿到url地址对应的响应(该响应的内容可以是html,css,js,图片等)
浏览器渲染出来的页面和爬虫请求的页面很多时候并不一样,是因为爬虫不具备渲染的能力(当然后续课程中我们会借助其它工具或包来帮助爬虫对响应内容进行渲染)
- 浏览器最终展示的结果是由多个url地址分别发送的多次请求对应的多次响应共同渲染的结果
- 所以在爬虫中,需要以发送请求的一个url地址对应的响应为准来进行数据的提取
下节讲述:
- requests模块的使用
结束语:
希望本文能够帮到那些刚入门或者想要学习的同学,文章持续更新中…
有帮助的话给个支持吧!你们的实力就是我更新的动力!感谢大家。
















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











