







F Lite 技术报告解析
一、研究背景与目标
F Lite 是一个开源的 100 亿参数文本到图像的扩散变换器(DiT)模型。该研究的目标是探索在中等数据规模和计算资源条件下,大规模扩散模型的性能边界。F Lite 基于 Freepik 内部数据集训练,包含约 8000 万张版权安全的图像,是首个完全基于合法合规且适合工作场所内容训练的公开模型。
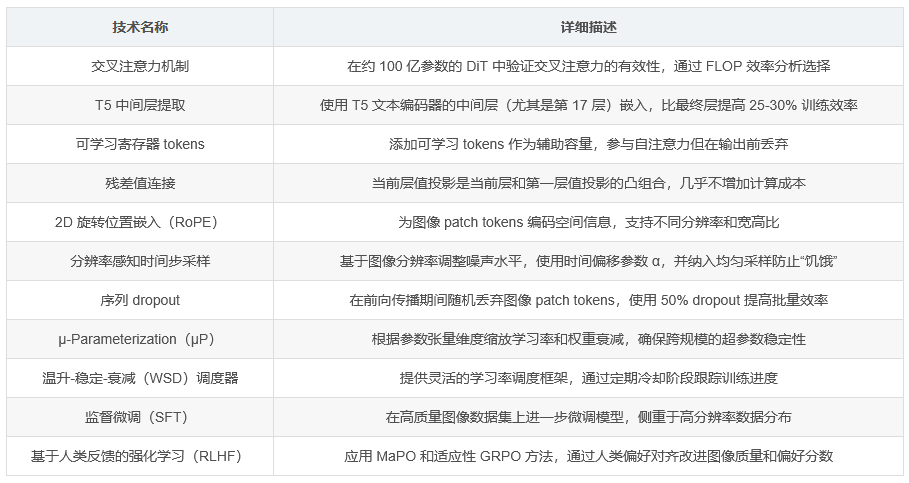
研究团队通过 FLOP(浮点运算效率)分析,选择了交叉注意力机制作为文本条件控制方式。该模型在 64 个 H100 GPU 上训练约两个月,证明了在中等数据和计算资源条件下仍能实现高性能的文本到图像生成。
二、模型架构设计
(一)整体结构
F Lite 采用潜在扩散范式,基于预训练的 VAE(变分自编码器)进行操作。模型核心是具有特定修改的变换器架构,以适应条件控制和性能需求:
-
输入潜在图像被划分为 tokens 序列
-
预先添加 Nreg 个可学习的寄存器 tokens
-
序列通过 L 个变换器块,每个块都基于时间步 t 和文本嵌入 c 进行条件控制
-
最终线性层将输出 tokens(不包括寄存器 tokens)投影回 VAE 潜在维度,预测去噪后的潜在图像
(二)交叉注意力扩展
与多模态扩散变换器(MMDiT)方法不同,F Lite 在每个块内使用独立的自注意力(用于图像 tokens)和交叉注意力(图像 tokens 关注文本 tokens)层。这种设计选择基于效率特性分析:
-
文本条件 c 来自预训练的 T5-XXL 编码器
-
实验发现,使用 T5 编码器中间层(尤其是第 17 层)的嵌入比使用最终层能提高 25-30% 的训练效率
-
中间层的特征表示更具通用性,适合用于扩散模型的条件控制
(三)位置编码
模型采用 2D 旋转位置嵌入(RoPE)来稳健地编码空间信息,支持不同分辨率和宽高比。寄存器 tokens 接收身份 RoPE 嵌入,使用 (0, 1) 的正弦/余弦值以保留 Q/K 值的身份特征。
(四)架构改进
F Lite 集成了多种现代组件:
-
寄存器 tokens:Nreg(例如 16 个)可学习 tokens 添加到图像序列中,作为辅助容量参与自注意力,但在输出投影前被丢弃
-
残差值连接:遵循值残差学习方法,当前层的值投影是当前层投影和第一层值投影的已学习凸组合,几乎不增加计算成本就能提供一致的小幅增益
-
归一化选项:在注意力分数计算前,可选地对查询和键(QK 归一化)独立应用 RMSNorm,特别是在高分辨率下可能带来稳定性益处
三、训练策略
(一)多阶段训练方法
训练过程分为多个阶段,逐步增加分辨率和复杂度:
-
低分辨率阶段(256×256 像素,512×512 像素):专注于学习核心概念和文本对齐,使用中心裁剪图像,占预训练计算的大部分
-
高分辨率阶段(≥1024×1024 像素):在更高分辨率图像上进行微调,批量内包含动态宽高比和分辨率
(二)优化器与稳定性
-
优化器与 µP:使用 AdamW 优化器,超参数设置遵循 µ-Parameterization(µP)原则。这涉及基于参数张量维度(输入扇入/输出扇出)缩放学习率和权重衰减,并为权重、偏差和归一化参数使用不同设置,确保跨规模的超参数稳定性
-
学习率调度:采用温升-稳定-衰减(WSD)调度方法,提供灵活的调度框架,通过定期冷却阶段帮助跟踪训练进度
(三)预训练技术
为最大化训练效率和稳定性,采用了多种技术:
-
分辨率感知时间步采样:基于图像分辨率调整噪声水平,使用时间偏移参数 α。对于 512px 图像 α≈2,对于 1024px 图像 α≈4。同时纳入 10% 的均匀采样以防止低噪声水平下的时间步“饥饿”,确保模型获得足够的细节梯度
-
序列 dropout:在前向传播期间随机丢弃部分图像 patch tokens(不包括寄存器 tokens)。使用 50% 的 token dropout 可以在不增加步长时间的情况下有效将批量大小翻倍,同时改善收敛性。在高分辨率训练中广泛使用,并在最后阶段进行未掩蔽的微调以确保模型能正确处理完整序列
四、后训练对齐
为提升图像质量和与用户偏好的对齐,应用了两阶段的后训练过程:
-
监督微调(SFT):在约 10 万个高质量图像的精选数据集上对预训练模型进行微调,使用相同的优化策略但侧重于更高分辨率的高质量数据分布
-
基于人类反馈的强化学习(RLHF):
-
初始采用边缘感知偏好优化(MaPO),结合重建和偏好边缘项的损失公式
-
适应性 GRPO 改进稳定性:借鉴 DeepSeek 的组相对策略优化(GRPO)原则,应用于文本到图像的 RLHF 设置。计算 MaPO 风格的对数几率偏好信号,并使用批量统计进行归一化,提供更稳定的梯度,隐式调整批次难度,并在 MaPO 开始平稳后继续改善图像质量和偏好分数
-
五、实验结果与分析
(一)训练设置
F Lite(约 100 亿参数,40 层,隐藏尺寸 3072,16 个头)在 Freepik 目录中约 8000 万张过滤后的高质量图像上训练。计算资源涉及最多 64 个 H100 GPU,约 1.5-2 个月(约 10e22 BF16 FLOPs 有效计算,约为 SD3 的两倍)。使用 Flux Schnell VAE 和 T5-XXL(第 17 层输出)进行文本编码。
(二)定性分析
F Lite 生成的样本展示了产生多样化、高保真图像的能力,能很好地遵循复杂提示。在生成插图和矢量风格方面表现特别强,可能反映了训练数据分布。但也观察到某些局限性:
-
高频细节:一些图像(特别是写实图像)缺乏细粒度纹理(如皮肤毛孔、织物细节)。可能通过进一步的高分辨率训练改进
-
解剖和复杂性:复杂场景或复杂解剖结构有时会导致畸形,这是生成模型的常见挑战,但可能因特定训练动态而加剧
-
短提示性能:模型在长描述性提示(训练中使用)下表现更好,而面对非常短的提示时表现不佳。对较短标题的微调可以解决此问题
-
文本渲染:尽管能够生成类似文本的元素,但在图像内准确渲染特定文本方面仍有限制
尽管 F Lite 能够生成具有令人印象深刻的美学和构图的高质量图像,但经常出现解剖畸形和生成错误。研究人员认为架构选择和训练方法本质上是合理的,这些问题可以通过使用更多计算资源在更大数据集上扩展训练来大幅缓解。这一假设得到了扩散模型扩展规律的支持,表明模型和数据扩展对生成质量改进有显著贡献。
六、结论
F Lite 是一个开源的 100 亿参数文本到图像扩散变换器,采用交叉注意力条件控制。该工作提供了一个稳健的基线,整合了现代架构改进和可扩展、高效的训练策略。主要贡献包括:
-
验证了交叉注意力在大规模(通过 FLOPs 评估)的有效性
-
发现使用 T5 中间层可提高 25-20% 的训练效率
-
详细记录了实际技术,如具有均匀采样校正的分辨率感知时间步采样和 WSD 调度器的成功应用
通过开源 F Lite,研究人员希望能够加速大规模生成建模的研究,并为 AI 社区提供有价值的工具。鼓励基于这项工作的合作和进一步探索。
核心技术汇总


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









