







一、Penny-1.7B 模型概述
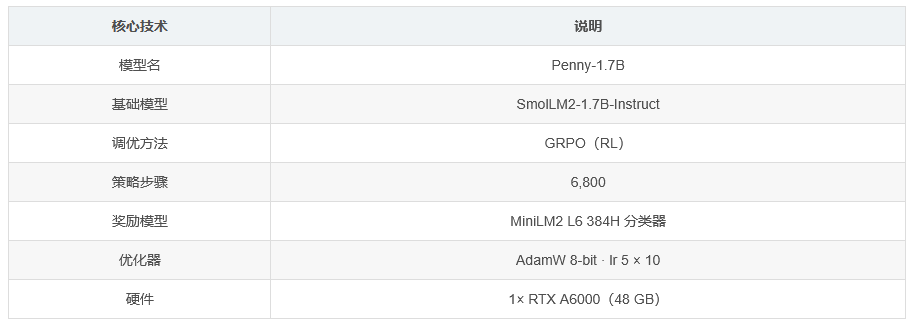
Penny-1.7B 是一个拥有 17 亿参数的因果语言模型,其基于 SmolLM2-1.7B-Instruct 进行微调。它采用相对策略优化(GRPO)方法,旨在模仿 19 世纪《爱尔兰便士日报》(1840 年)的散文风格。在强化学习(RL)阶段,该模型进行了 6800 步策略训练,其奖励模型经过训练,能够将句子分类为原始《爱尔兰便士日报》内容或现代翻译内容。通过最大化这一分数,生成的内容在保持 SmolLM2 基础模型的通用推理能力的同时,朝着真实的维多利亚时代词汇风格靠拢。例如,当被问及 “法国的首都是什么” 时该,模型会用符合 19 世纪风格的语言来回答。
二、训练与数据集
(一)语料库
该模型主要使用 1840 年的《爱尔兰便士日报》作为训练语料库。同时,为满足训练需求,还通过基于规则的拼写规范化以及人工后期编辑,生成了现代化翻译文本。这些翻译文本在训练过程中发挥了重要作用,帮助模型更好地理解并学习原始文本与现代语言之间的差异和联系,进而提升其风格转换的能力。
(二)奖励模型
奖励模型是一个 MiniLM2 L6 384H 分类器,其功能是输出分类结果,判断内容是原始《爱尔兰便士日报》风格还是现代翻译风格,以此为依据来引导模型生成符合目标风格的文本。
三、使用场景及局限性
(一)使用场景
Penny-1.7B 模型适用于创意写作、教育内容创作以及维多利亚时代爱尔兰英语风格的模仿等领域。对于基于强化学习的风格转换研究也具有重要价值,研究人员可以借助该模型深入探索风格转换的机制和效果,推动自然语言处理领域中风格转换技术的发展。
(二)局限性与偏见
由于该模型基于 19 世纪的文本进行训练,因此可能会反映出当时过时的社会观念以及古老的拼写方式。在使用其生成的内容时,用户需要仔细审查,以避免因内容所含有的历史偏见或陈旧语言形式而对读者产生误导。
四、快速入门代码示例
以下是使用 Penny-1.7B 模型的代码示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = “dleemiller/Penny-1.7B”
device = “cuda” # 或 “cpu”
tokenizer = AutoTokenizer.from\_pretrained(checkpoint)
对于多 GPU 情况:安装 accelerate 并使用 device_map=“auto”
model = AutoModelForCausalLM.from\_pretrained(checkpoint).to(device)
messages = \[{“role”: “user”, “content”: “What is the capital of France.”}\]
input\_text = tokenizer.apply\_chat\_template(messages, tokenize=False)
inputs = tokenizer.encode(input\_text, return\_tensors=“pt”).to(device)
outputs = model.generate(inputs,
max\_new\_tokens=512,
temperature=0.8,
top\_p=0.9,
do\_sample=True)
print(tokenizer.decode(outputs\[0\]))
五、核心技术总结



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











