







目录
一、意向用户主题看板
1、需求分析
首先将每一个需求所涉及的维度、指标、表、字段分析出来,然后在此基础之上,找到那些数据需要清洗,那些数据需要转换,如果有多个表,表与表之间的关联条件是什么。此外要知道那些表是事实表,那些表是维度表。
需求一:统计指定时间段内,新增意向客户(包含自己录入的意向客户)总数
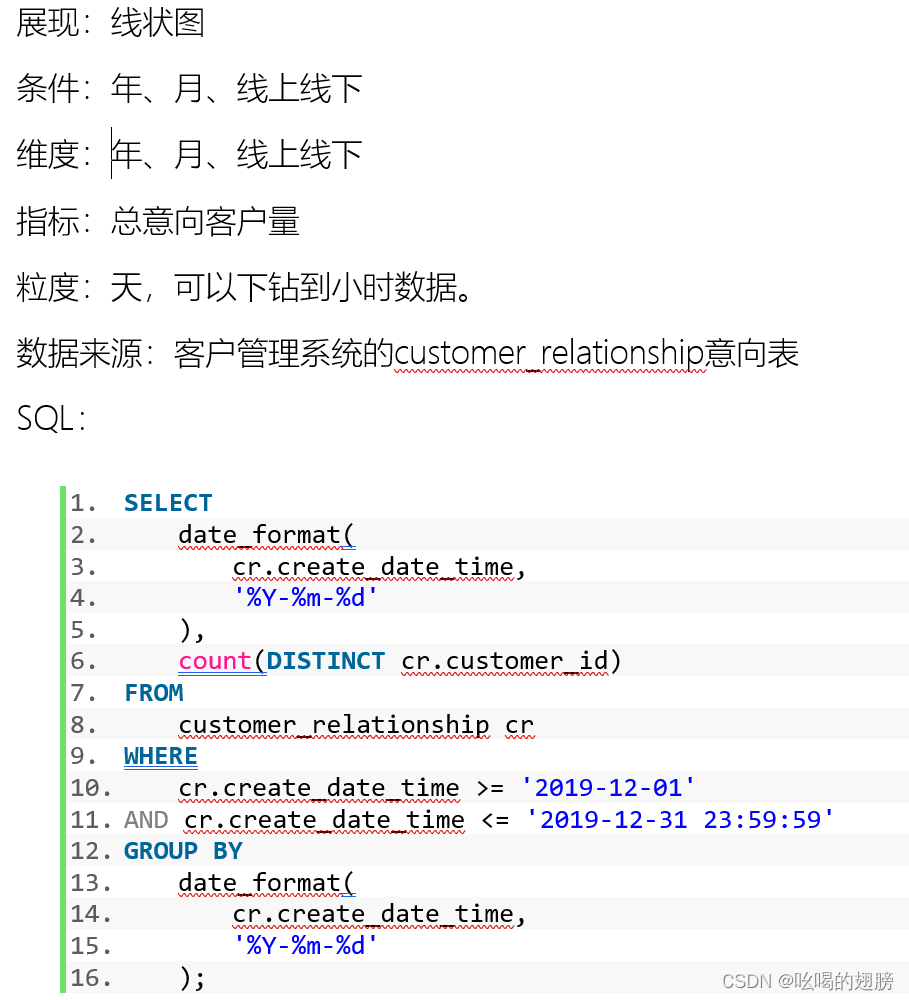
维度:时间维度:年、月、天、小时
新老维度(新增意向客户即只统计指定时间段内新意向用户,老意向用户不算)
线上线下维度
指标:总意向客户量(意向量)
表:customer_relationship客户意向表(事实表)
字段:时间维度:create_date_time,需要进行转换工作,转换为yearinfo,monthinfo,dayinfo,
hourinfo四个字段
新老维度:?
线上线下维度:?
指标字段:customer_id,需要先去重在统计,由于该字段有重复值,因此无法在DWM层进行提前聚合
需求二:
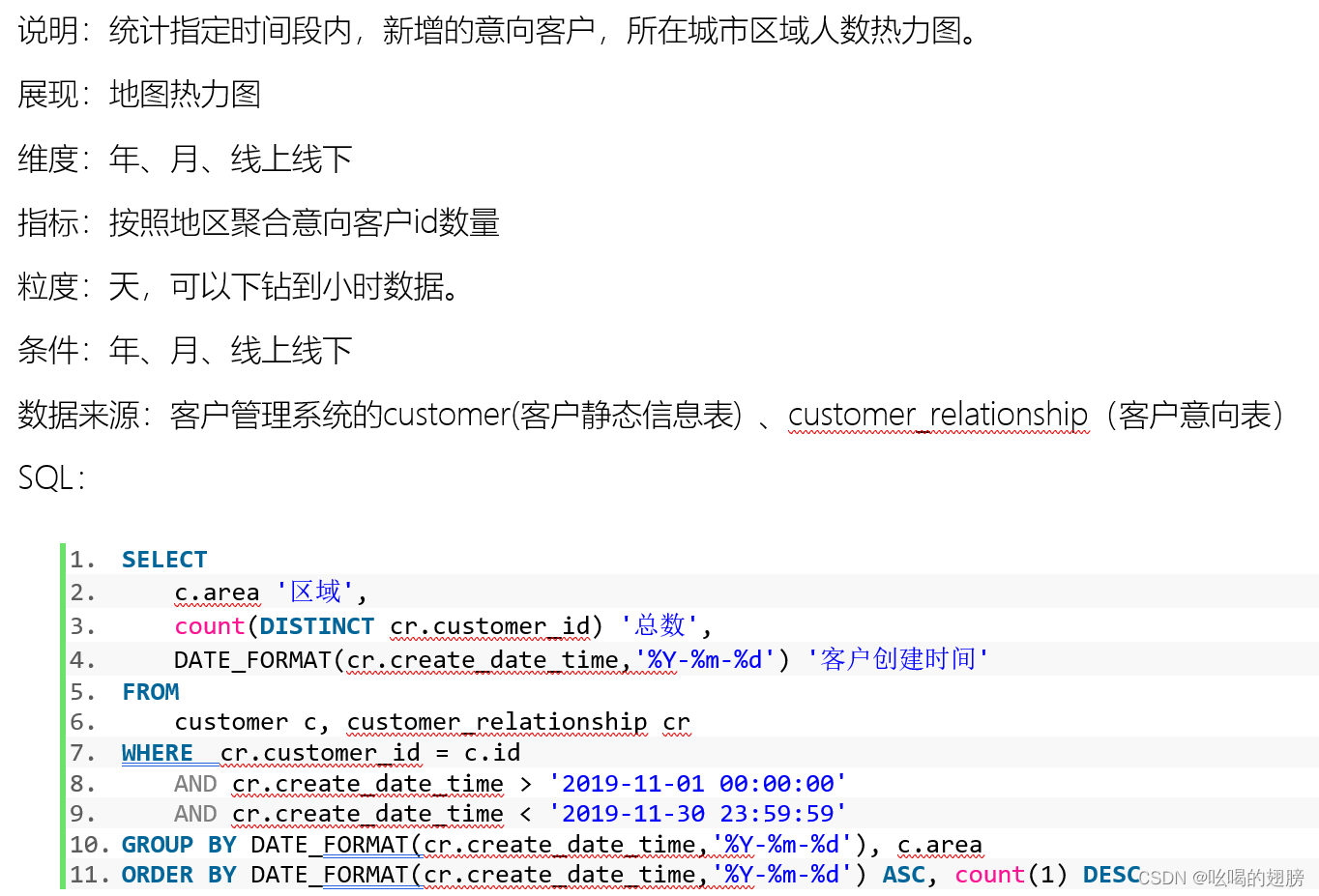
维度:时间维度:年、月、天、小时
新老维度
区域维度
线上线下维度
指标:意向量
表:customer客户表(用户维度表)、customer_relationship(事实表)
关联条件:customer.id = customer_relationship.customer_id
字段:时间维度:customer_relationship.create_date_time,需转换
新老维度:?
区域维度:customer.area
线上线下维度:?
指标字段:customer_relationship.customer_id,需去重在统计
需求三:

维度:时间维度:年、月、天、小时
新老维度:
学科维度:
线上线下维度:
指标:意向量
表:customer_clue客户线索表(新老,线上线下维度表)、customer_relationship(事实表)、itcast_subject学科表(学科维度表)
关联条件:customer_relationship.itcast_subject_id = itcast_subject.id
customer_relationship.id = customer_clue.customer_relationship_id
字段:时间维度:customer_relationship.create_date_time (要以事实表字段为主)需要转换
新老维度:customer_clue.clue_state
说明:当字段的值为'VALID_NEW_CLUES'时,该客户为新用户。暂定其他的值都是老用户(即使其他值还有不同的用户类型但是本需求只考虑新用户,其他的值不考虑)。因此该字段的取值只有新老,需要将clue_state转化为clue_state_stat,此新字段的值只有0(老)和1(新)。
学科维度:customer_relationship.itcast_subject_id、itcast_subject.name
线上线下维度:customer_relationship.origin_type,同clue_state需要转换
说明:当字段的值为'NETSERVICE'或'PRESIGNUP'时表示线上。暂定其他的值都是线下(如果不转换可能按照该字段分组会产生很多很多组,但我们只关心是线上还是线下)。因此需要将origin_type字段转换为origin_type_stat,此新字段的值只有0(线下)和1(线上)。
指标字段:customer_relationship.customer_id
清洗操作:将customer_clue.deleted = false数据保留下,为true的数据清洗掉
转换操作(由需求四启发而来):将customer_relationship.itcast_subject_id字段为0或null的值统一转换为-1
注意:事实表存在的字段,要优先使用,如果没有从维度表中查询
当字段只有两元操作时即该字段的值要么取“新”要么取“老”(男女...),需要对该字段转换为数值0,1。目的是方便后续sql编写以及防止后续可能对该字段分组分出多个无关的组,以及后续未来可能会用。
需求四:
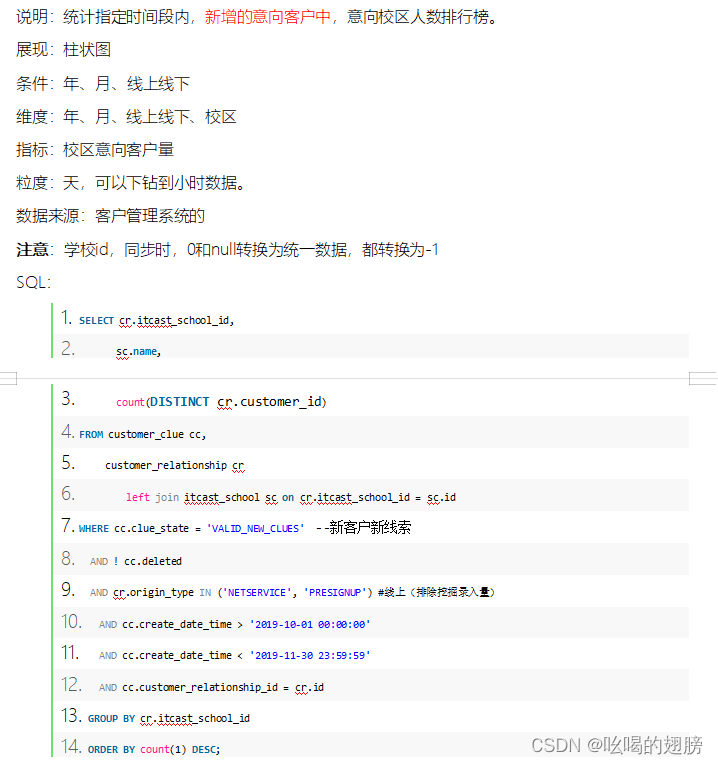
维度:时间维度:年,月,天,小时
新老维度
校区维度
线上线下维度
指标:意向量
表:customer_clue(维度表)、customer_relationship(事实表)、itcast_school校区表(校区维度表)
关联条件:customer_relationship.itcast_school_id = itcast_school.id
customer_relationship.id = customer_clue.customer_relationship_id
字段:时间维度:customer_relationship.create_date_time,需要转换
新老维度:customer_clue.clue_state,需要转换
校区维度:customer_relationship.itcast_school_id,itcast_school.name
线上线下维度:customer_relationship.origin_type,同clue_state需要转换
指标字段:customer_relationship.customer_id
清洗操作:将customer_clue.deleted = false数据保留下,为true的数据清洗掉
转换操作:将customer_relationship.itcast_school_id字段为0或null的值统一转换为-1
需求五:
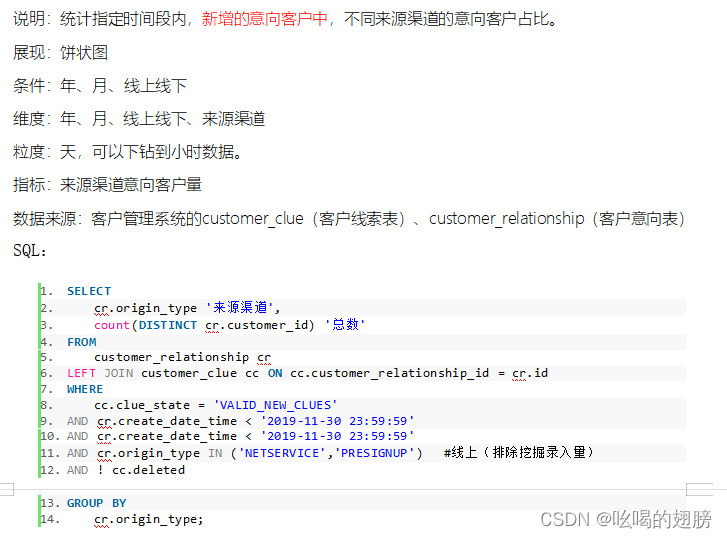
维度:时间维度:年,月,天,小时
新老维度
来源渠道维度
线上线下
指标:不同来源渠道意向量
总意向量(需求一已统计)
表:customer_relationship,customer_clue
关联条件:customer_relationship.id = customer_clue.customer_relationship_id
字段:时间维度:customer_relationship.create_date_time
新老维度:customer_clue.clue_state
来源渠道维度:customer_relationship.origin_type
线上线下维度:customer_relationship.origin_type,需要转换origin_type_stat
指标字段:customer_relationship.customer_id
清洗操作:将customer_clue.deleted = false数据保留下,为true的数据清洗掉
说明:线上线下维度是来源渠道维度的上卷操作
需求六:

维度:时间维度:年,月,天,小时
新老维度
咨询中心维度
线上线下维度
指标:各咨询中心意向量
总意向量(需求一)
表:customer_relationship,employee员工表(员工维度表),scrm_department部门表(部门维度表),customer_clue
关联条件:customer_relationship.creator = employee.id
employee.tdepart_id = scrm_department.id (雪花模型)
customer_relationship.id = customer_clue.customer_relationship_id
字段:时间维度:customer_relationship.create_date_time
新老维度:customer_clue.clue_state
咨询中心维度:employee.tdepart_id,scrm_department.name
线上线下维度:customer_relationship.origin_type
指标维度:customer_relationship.customer_id
清洗操作:将customer_clue.deleted = false数据保留下,为true的数据清洗掉
需求汇总:(共24个需求)
涉及维度:
固有维度:
时间维度:年,月,天,小时
新老维度
线上线下维度
产品属性维度:
区域维度
学科维度
校区维度
来源渠道维度
咨询中心维度
涉及指标:意向量
涉及表:
事实表:customer_relationship
维度表:customer、customer_clue、itcast_subject、itcast_school、employee、scrm_department
表与表关联条件:
customer_relationship.customer_id = customer.id
customer_relationship.itcast_subject_id = itcast_subject.id
customer_relationship.id = customer_clue.customer_relationship_id
customer_relationship.itcast_school_id = itcast_school.id
customer_relationship.creator = employee.id
employee.tdepart_id = scrm_department.id
涉及字段:
时间维度:customer_relationship:create_date_time
新老维度:customer_clue:clue_state
线上线下维度:customer_relationship:origin_type-->origin_type_stat
区域维度:customer:area
学科维度:customer_relationship:itcast_subject_id、itcast_subject:name
校区维度:customer_relationship:itcast_school_id,itcast_school:name
来源渠道维度:customer_relationship:origin_type
咨询中心维度:employee:tdepart_id,scrm_department:name
指标字段:customer_relationship:customer_id
清洗字段:customer_relationship:deleted
需要清洗的数据:将customer_relationship.deleted = false数据保留下,为true的数据清洗掉
注意:通过查看表的结构发现customer_relationship表中同样有deleted字段,因此优先使用事实表的字段。
需要转换的字段:
时间字段:将customer_relationship.create_date_time转换为yearinfo,monthinfo,dayinfo,hourinfo
新老字段:将customer_clue.clue_state转化为clue_state_stat,此新字段的值只有0(老)和1(新)。
线上线下字段:将customer_relationship.origin_type字段转换为origin_type_stat,此新字段的值只有0(线下)和1(线上)。
学科字段:将customer_relationship.itcast_subject_id字段为0或null的值统一转换为-1
校区字段:将customer_relationship.itcast_school_id字段为0或null的值统一转换为-1
2、业务数据准备
create database scrm default character set utf8mb4 collate utf8mb4_unicode_ci;
将上述7个sql导入进scrm库运行即可。
3、建模分析
ODS层:存储事实表和少量维度表(存储在当前主题不是事实表但在其他主题是事实表的表)
本看板维度表较多就不存储在ODS层了,因此该层有一张表,表结构与customer_relationship表一致,此外,在建表时需要构建为分区表,分区字段为starts_time(表示抽取数据时间)
注意为了长远考虑,customer_clue是当前主题的维度表,但同时该表是下一个主题“有效线索主题”的事实表,因此将customer_clue也放在ODS层。
此外考虑到ODS层的数据存在变更行为,需要引入缓慢渐变维来处理,一般使用SCD2来解决(即不删除,不修改已有的数据,而是增加一行数据并新增两个字段:开始时间与截至时间),starts_time可以作为开始时间使用,因此需要在添加一个截至时间字段。
最终ODS层有两张表,customer_relationship、customer_clue,表结构与业务数据库一致,且需要添加分区(开始时间)starts_time字段和截至时间end_time字段
DIM层:存储维度表
共五张表:customer、itcast_subject、itcast_school、employee、scrm_department,表结构与原业务库一致,且需要添加分区starts_time字段,一般情况下维度表数据量较小,且不容易发生变化,不需要使用拉链表。
DWD层:对ODS层的数据进行ETL清洗和少量维度退化
思考1:是否需要清洗?需要,customer_relationship.deleted
思考2:是否需要转换?需要转换5个字段
思考3:是否需要进行少量维度退化?
方案一:可以不做维度退化,将整个维度退化工作放到DWM层(customer_clue表理应放在DIM层)(推荐)
方案二:需要对customer_clue进行维度退化工作,将该表的有用字段退化到事实表中
注意:customer_clue放在ODS层的目的是为了下一个主题分析方便,在当前主题下,customer_clue就是一个维度表将其视为DIM层的表即可。
DWD层有一张表,建表字段为:必须字段(需要用到的字段)+清洗字段+转换字段:id、create_date_time、customer_id、origin_type、itcast_school_id、itcast_subject_id、creator、deleted、yearinfo、monthinfo、dayinfo、hourinfo、origin_type_stat,其中yearinfo、monthinfo、dayinfo为分区
DWM层:对DIM层的维度表进行维度退化,对事实表进行提前聚合操作,形成周期快照事实表
思考1:是否需要维度退化?需要将所有维度表中用到的字段退化到事实表中
第一:将ODS层中的customer_clue的要用的字段退化到事实表,并且将customer_clue.clue_state转化为clue_state_stat。第二:将DIM层5张表的相应字段退化到事实表
思考2:是否需要提前聚合?customer_id字段重复不需要提前聚合
DWM层有一张表,建表字段为:DWD层表字段(不需要表连接字段id、creator,因为从DWD到DWM的过程中已经将表全部连接,后续没用了)+维度退化字段(clue_state不需要,因为用的是转换后的字段,转换前的字段不需要):create_date_time、customer_id、origin_type、itcast_school_id、itcast_subject_id、deleted、yearinfo、monthinfo、dayinfo、hourinfo、origin_type_stat、clue_state_stat、area、itcast_subject_name、itcast_school_name、tdepart_id、tdepart_name
注意:deleted字段在DWD层和DWM层加不加都无所谓,因为已经进行玩清洗工作了,deleted字段都是false。此过程需要进行七表关联操作。
扩展:如果要做提前聚合操作,只需要多建一张类似与DWS层的表,对上述表最细粒度的维度小时进行聚合(建表时可以省略一个经验字段:time_type,共6个需求)。
DWS层:统计分析
建表字段:指标字段+维度字段+经验字段
customer_total,yearinfo,monthinfo,dayinfo,hourinfo,clue_state_stat,origin_type_stat,area,itcast_subject_id,itcast_subject_name,itcast_school_id,itcast_school_name,origin_type,tdepart_id,tdepart_name,time_type,group_type,time_str
4、分桶表的相关优化
思考:什么是分桶表?
主要是将大文件划分为若干个小文件,在建表时,可以指定分桶字段以及分几个桶,当数据insert select加载时,执行MR程序会自动将数据分散至各个分桶中,默认划分规则是:hash取模
思考:分桶表的创建:
create table test_buck(id int, name string)
clustered by(id) sorted by (id asc) into 6 buckets
row format delimited fields terminated by '\t';
-- sorted by将各个分桶按id字段排序asc|desc思考:向分桶表添加数据:先创建一个与分桶表一样的临时表,使用load date方式向其添加数据,然后利用insert select方式向分桶表中导入数据,注意:sqoop不支持直接对分桶表导入数据。
思考:分桶表的作用:进行数据采样;提高查询效率(单表|多表)
4.1、进行数据采样
案例1:数据质量校验工作即在实际分析数据之前,一般会先判断所用表的各个字段数据的结构信息是否完整,但是表的数据十分庞大无法全部校验,此时通常会采样出一部分的数据来近似整体数据,如果这一小部分数据没问题,则我们认为整体数据没问题。
案例2:在进行数据分析时,可能一天需要编写N多条SQL,但是每编写一条SQL就需要对该SQL进行一次校验,如果直接面对完整的数据集做校验,会导致校验时间过长,影响开发进度,此时可以先采样出一部分校验数据,专门用于校验工作。这就是为什么在实际生产环境中会有测试环境与开发环境的原因,在测试环境下写好SQL,校验完毕之后,将其放到开发环境中运行。
案例3:在计算一些比例值或相对指标时,比如计算当前月的销售额相对于上个月的销售额的增长率,由于当前月与上个月的数据太过庞大直接计算需要很长时间,此时可以对当前月和上个月的数据进行采样,都采样30%的数据,然后在局部数据上计算增长率来近视整体。
如果是分桶表,直接拿出一个桶或若干桶的数据就是采样,十分方便。
思考:如何进行数据采样?(如何获取某些桶的数据呢?)
在hive中提供了专门的采样函数:tablesample(bucket x out of y on column),使用方法为:
select * from <table_name> tablesample(bucket x out of y on column) 或
select * from <table_name> tablesample(bucket x out of y on column) <表别名> # 如果表有别名,需要放到别名之前。
x:表示从第几个桶开始采样,从1开始(注意分桶表的命名是从0开始的,这里x是从1开始的,例如000000桶表示第1个桶)
y:采样桶的比例(总桶数 / y = 采样桶数量,例如总共10个桶,y=2,最终会采样5个桶)
column:按那个字段进行采样(一般为分桶字段,可以省略)
例如:table总bucket数为6,tablesample(bucket 1 out of 2),表示总共抽取(6/2=)3个bucket的数据,从第1个bucket开始,抽取第1(x)个和第3(x+y)个和第5(x+y)个bucket的数据。
注意:x必须小于等于y;y必须是总桶数的倍数或因子(比如总桶数10,因子:1,2,5,10;比如总桶数10,倍数:10,20,30,40)总之就是能让总桶数 / y = 采样桶数量除的尽。

4.2、提升查询效率--单表效率提升:


一般分桶表的建立对多表查询效率提升较大,单表查询时使用分区表就可以了,因为本身就一张表数据量本身不是特别大,使用了分桶表数据加载等等方面不方便,因此使用分区表就够了,当然如果分区后单个区的数据依旧很大,可以在使用分桶表。
4.3、提升查询效率--多表效率提升:
(1)补充:
通用的join优化策略--空key过滤与空key转换(针对表中存在null值时,通用的优化策略)
1)空key过滤
使用场景:外连接时使用(会出现null值,内连接本身已经过滤掉null了)
不需要null字段的情况下
假设当前有两张表,且都有大量空值,直接join操作会产生大量无用的连接,需要先过滤掉所有的null在join操作。又比如在增量操作时一定是先将增量的数据查询出来,然后join,否则,会出现大量无用连接。此外,有时join连接超时是因为某些key太多,而相同的key会发送到相同的reduce task上,导致某个reduce task负荷极大,内存不足,因此,需要先将异常值过滤掉之后join。
select n.* from (select * from nullidtable where id is not null) n
left join bigtable o on n.id = o.id;
select * from (select * from 订单表 where create_time between '2021-09-25 00:00:00' and '2021-09-25 23:59:59') a
join (select * from 订单附属表 where create_time between '2021-09-25 00:00:00' and '2021-09-25 23:59:59') b on a.id = b.id2)空key转换
有的时候null值在某些表中不是异常数据,不能事先过滤掉必须让其参加join操作,但null值又很多,相同的值会发送到同一个reduce task中,导致某个reduce task处理的数据极大,而其他的reduce task没多少数据,出现数据倾斜。此时可以将所有的null值转化为随机数,这样null值可以随机均匀的发送至不同的reduce task中,数据得到均匀分配。
select n.* from nullidtable n full join bigtable o on nvl ( n.id,rand() ) = o.id;
(2)MapReduce Join分类
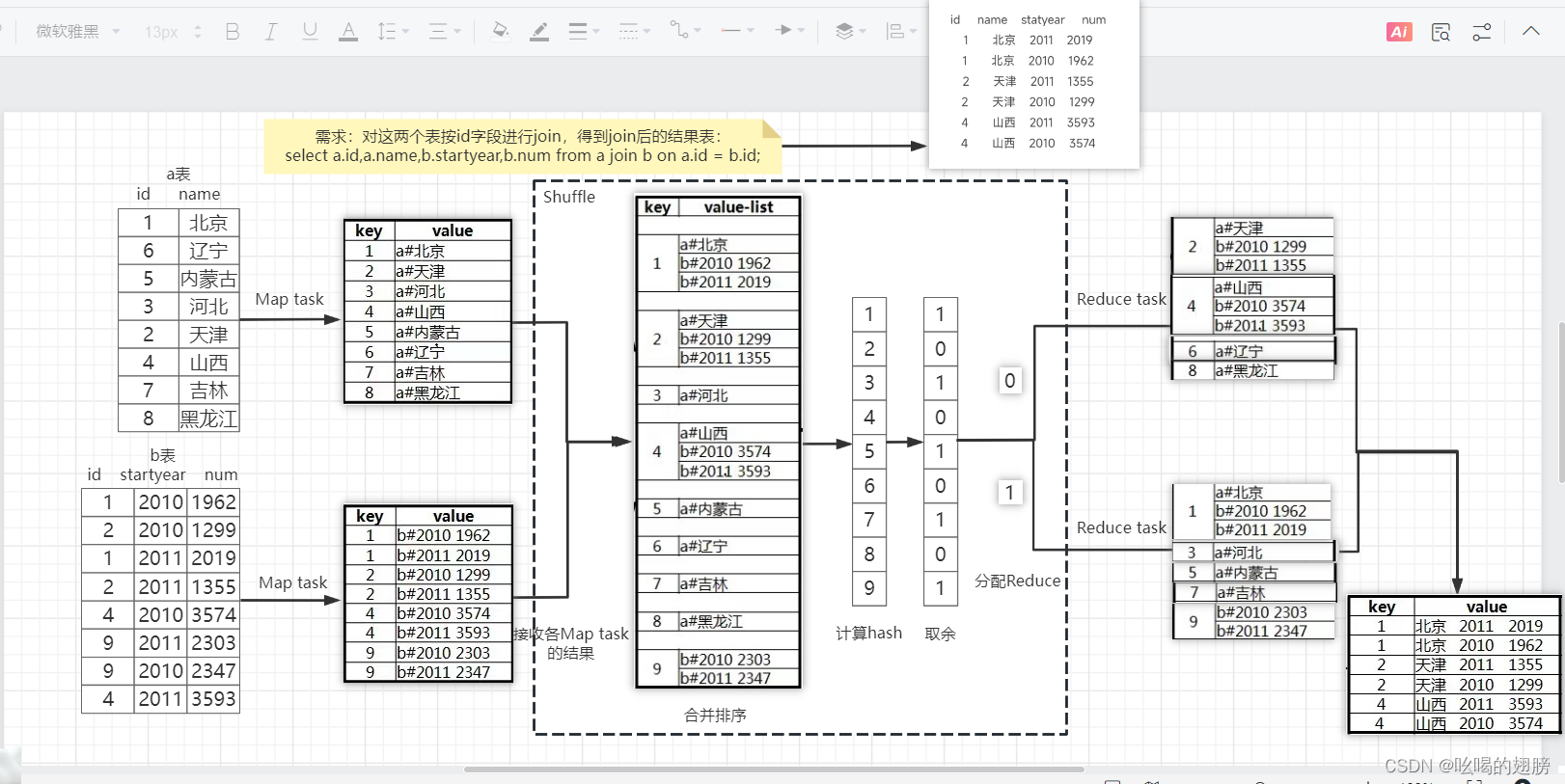
hive的整个过程分为Map,Shuffle,Reduce三大阶段。
Map阶段用于根据查询语句指定key和value,key是关联条件字段,value包含select|where所关心的字段以及这条数据来源于那个表的tag标识,表与表之间还没有做join操作,此外Map阶段的输出会按key进行排序。相当于Map阶段就是根据SQL语句对各个表做了一次标记。
Shuffle阶段用于首先获取每个Map task的结果,然后将各个Map task的结果进行合并排序(按照key值进行排序,key相同的value放到一起,也就是同一个分区之下),其次根据key值计算hash取余(hash值/Reduce个数取余),最后根据hash值将不同的key/value数据发送至不同的Reduce task中(适用于多个Reduce task)。相当于Shuffle阶段就是进行数据整理工作和Reduce的确定。
Reduce阶段用于根据key值完成join操作,固定key值对value中的tag标识进行扫描,如果tag不同说明来自于不同的表,直接将value值合并即可,结果同样会按照key排好序;如果tag相同说明只有一张表,不操作。上述过程就是默认的join操作,即Reduce join操作(又称Common join)
例子:假设Map task = 2, Reduce task = 2
注意:shuffle过程的性能对整个MapReduce作业的性能有着重要的影响。因为shuffle过程涉及网络传输和磁盘IO等开销较大的操作,所以在设计MapReduce作业时需要尽可能减少数据的传输和磁盘读写,以提高整个作业的效率。
在hive中join的实现方法有两种:Reduce join(默认) 和 Map join。显然使用Reduce方法会涉及Map,Shuffle,Reduce三个阶段,效率低。而Map join顾名思义就是在Map task过程中直接进行join操作,join操作已经提前进行。相当于不需要后面的shuffle与reduce了,这样大大提高了执行效率。Map join节省了Shuffle阶段大量的数据传输,从而起到了优化作业的作用。
Reduce join的缺点:
1)shuffle阶段涉及大量网络传输与磁盘IO,效率低。
2)由于key本身可能存在数据分配不均匀问题,有大量相同的值存在,相同的key会发送给同一个Reduce task,导致某个Reduce task分配的数据过多,而其它Reduce task几乎没什么数据,从而出现数据倾斜现象。
3)Map task工作量小,Shuffle和Reduce task工作量大,不均衡。
思考:Reduce join就一定不如Map join吗?需要在任何情况下都用Map join吗?
Reduce join不一定就不如Map join,比如小表与小表的join|小表与中表的join,本身数据量都不大,使用默认的Reduce join方式本身就挺快的,此时就不需要Map join,反而使用了Map join由于其特殊的处理流程可能会使join变慢,或提升效率不明显。大多数情况Reduce join使用更为普遍,只有遇到大表时,数据量特别特别大,此时才需要优化。注意Map join适用于小表与大表的join优化,因为Map join的机制是将小表放到内存中,表太大就无法放入内存了。
Map join的使用场景:
1)小表与大表的join。小表可以放到内存中而不影响性能,具体来讲是1张大表与多张小表的情况。大表的数据倾斜特别严重,有一个key占比很大,在Reduce的过程中遇到执行时间过长或内存不够的问题。
2)不等值的链接操作,两表同样一大一小。
select a.id, a.score from a join b on a.score > b.score # hive中join on后面不支持不等连接操作,会报错
select a.id, a.score from a, b where a.score > b.score # 使用where比然会造成笛卡尔积,假设目前没有用Map join优化,笛卡尔积的计算会在Reduce task中进行,即在Shuffle阶段存在大量的数据传输,速度会很慢,甚至任务会无法完成(该过程会涉及shuffle + reduce + 笛卡尔积计算)。如果使用Map join优化,笛卡尔积的计算会在Map task中完成,没有shuffle与reduce(该过程只涉及笛卡尔积计算),效率会高很多。
(3)多表join效率提升
一共分3种情况(必须存在大表,如果连大表都没有说明数据不多没必要优化)
小表和大表:采用Map join方案,即在进行join的时候,将小表的数据放置到每一个读取大表的Map task的内存中(具体来讲是内存中的一个特定的缓存空间-blockcache),让Map task每读取一次大表的数据都和内存中小表的数据进行join操作,这样使得join操作提前完成,节省了shuffle阶段大量的数据传输,然后将Map task的结果输出到reduce汇总整理即可(注意当前的reduce task的作用仅仅是汇总一下Map join的结果或将结果直接输出)。当然可以直接将Map task的结果直接输出。
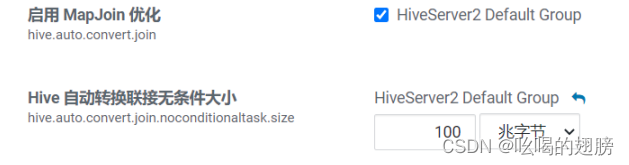
Map join的开启:
set hive.auto.convert.join=true; # 是否开启Map join
set hive.auto.convert.join.noconditionaltask.size=512000000; # 设置小表最大阈值(设置blockcache缓存大小),默认值为20M。注意:如果所有小表的总大小小于512M系统会自动走Map join优化,将小表存放到内存中,此时如果实际内存不足或允许使用的内存大小不足,会报code 1/137错误,解决方案是:1)直接关闭Map join。2)降低小表最大阈值。3)扩大内存。
中型表和大表:中型表大约是小表的3-10倍
解决方案:
1)能提前过滤就提前过滤,提前过滤会导致中型表的数据量下降,有可能达到小表阈值,此时使用Map join优化即可。
2)如果join的字段值有大量的null,可以尝试添加随机数,保证reduce接收的数据量均衡,减少数据倾斜问题。
3)基于分桶表的bucket map join优化
bucket map join的生效条件:
A:set hive.enforce.bucketing=true; # 强制分桶
set hive.auto.convert.join=true; # 是否开启Map join
set hive.auto.convert.join.noconditionaltask.size=512000000; # 设置小表最大阈值
set hive.optimize.bucketmapjoin = true; # 开启bucket map join支持
B:一个表的bucket数是另一个表bucket数的整数倍。比如A表桶数为2,B表的桶数为2,4,6,8....不能是3,5。
C:分桶列等于join列
D:必须是应用在map join的场景中
E:各个表必须是分桶表,如果不是分桶表,只能做reduce join
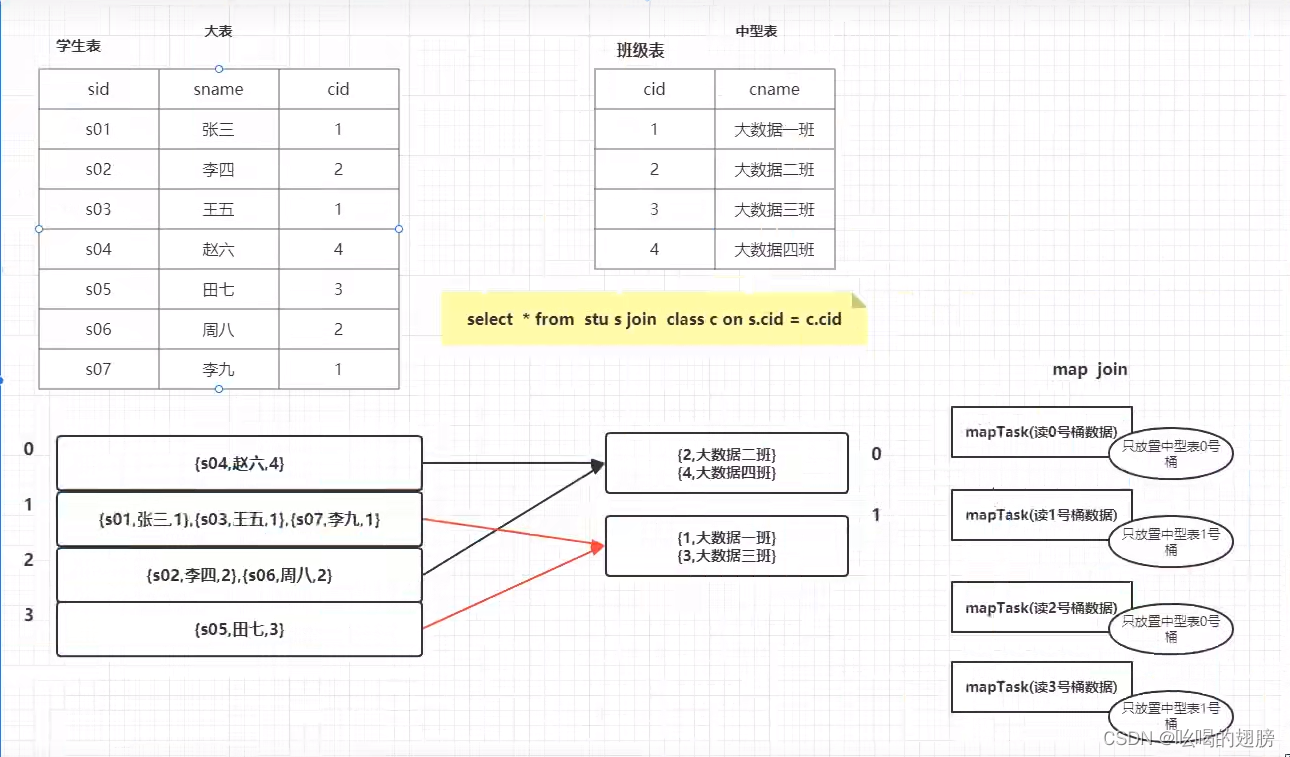
说明:中型表是无法直接放到内存中的,这样做会极大影响内存效率,需要将中型表进行分桶,使得分好的各个桶都满足小表的阈值条件,比如分2个bucket但这两个桶还不满足小表的阈值条件,则分更多的桶直到满足即可。然后将大表的bucket数设为中型表的整数倍。分好桶之后会有一种规律:设x=中型表的bucket数,中型表的0号桶只需要与大型表的0,0+x,0+2x...进行join,中型表的1号桶只需要与大型表的1,1+x,1+2x....进行join。
以上图为例:大表有4个桶,需要使用4个map task分别存放各个桶的数据,各个map task的blockcache只需要存放中型表中用到的桶即可,不需要将整个中型表全部放入blockcache,而中型表的各个桶都满足小表阈值,可以放入内存。原来map join优化方法需要在内存中存放4份中型表数据,而bluck map join只需要存放2份中型表即可。可以总结出规律:如果使用map join方法,内存需要存放map task份中型表;如果使用bucket map task方法,内存只需要存放a份中型表(a=大表bucket数/中型表bucket数),每个map task只存放中型表数据的“1/中型表bucket数”。
大表和大表:大表是小表的10倍以上
解放方案:
1)能提前过滤就提前过滤,减少join数据量,提升reduce效率。
2)如果join的字段值有大量的null,可以尝试添加随机数,保证reduce接收的数据量均衡,减少数据倾斜问题。
3)SMB Map join(sort merge bucket map join)
SMB Map join的生效条件:
A:set hive.enforce.bucketing=true; # 强制分桶
set hive.enforce.sorting=true; # 开启数据强制排序
set hive.auto.convert.join=true; # 开启Map join支持
set hive.auto.convert.join.noconditionaltask.size=512000000; # 设置小表最大阈值
set hive.optimize.bucketmapjoin = true; # 开启bucket map join支持
--开启SMB map join支持
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
set hive.optimize.bucketmapjoin.sortedmerge = true; # 开启自动尝试SMB连接
B:一个表的bucket数等于另一个表的bucket数
C:分桶列==join列==sort排序列(需要对各个桶进行内部排序)
D:必须是应用在bucket map join的场景中
E:各个表必须是分桶表,并排序
注意:如果设置了强制分桶,强制排序,则创表示必须写分桶和排序:CLUSTERED BY(mid) SORTED BY(mid) INTO 500 BUCKETS;
说明:SMB map join首先会筛选出较小的大表,将其分桶,使得分好的各个桶满足小表阈值,然后将另一个大表进行分桶,分桶数一样。其余过程与bucket map join一样。分好桶之后,两张大表的分桶会形成一一对应的关系,即A表的0号桶只有B表的0号桶相关,...。如果使用map join方法,内存需要存放map task份大表,如果使用SMB map task方法,内存只需要存放1份大表即可,每个map task只存放较小大表数据的“1/大表bucket数”。















 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









