







4.1梯度下降Grading Descent
一、介绍
①梯度下降:不仅用于线性回归,还用于训练一些先进的神经网络模型,也被成为深度学习模型。
②梯度下降是一种可用于尝试最小化任何函数的算法,不仅仅是最小化。线性回归的成本函数。
③事实证明,梯度下降适用于更一般的函数,包括适用于具有两个以上参数的模型。
二、梯度下降算法
①使用梯度下降算法:每次都稍微改变w和b以尝试降低J(w,b),直到接近最小值。
②梯度下降算法形象化解释:你要360度环顾周围并问自己,如果我要向一个方向迈出一步,我想尽快找到一个山谷或是下坡,我该向哪个方向。最后重复这个步骤,找到最快的下降梯度。
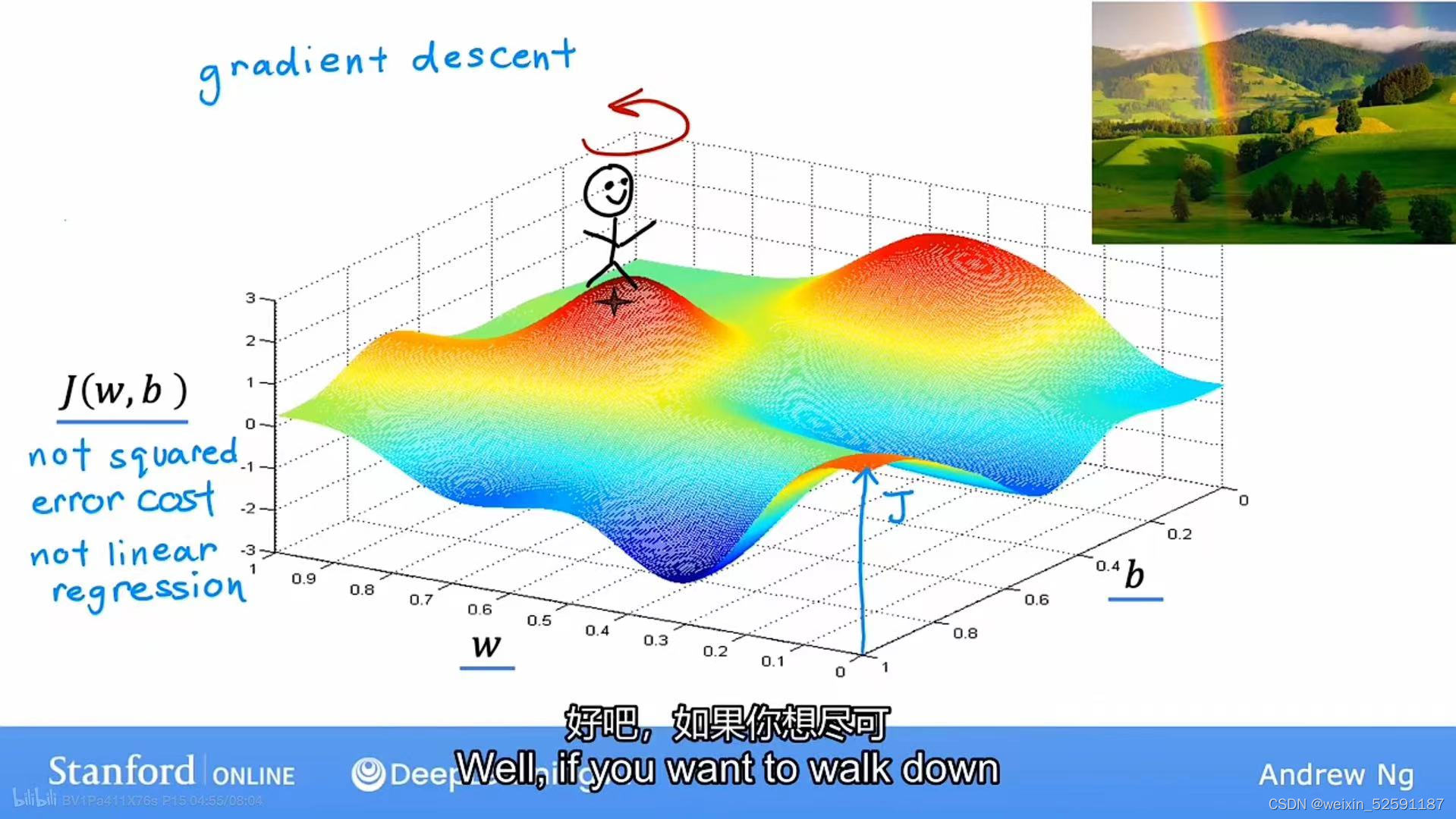
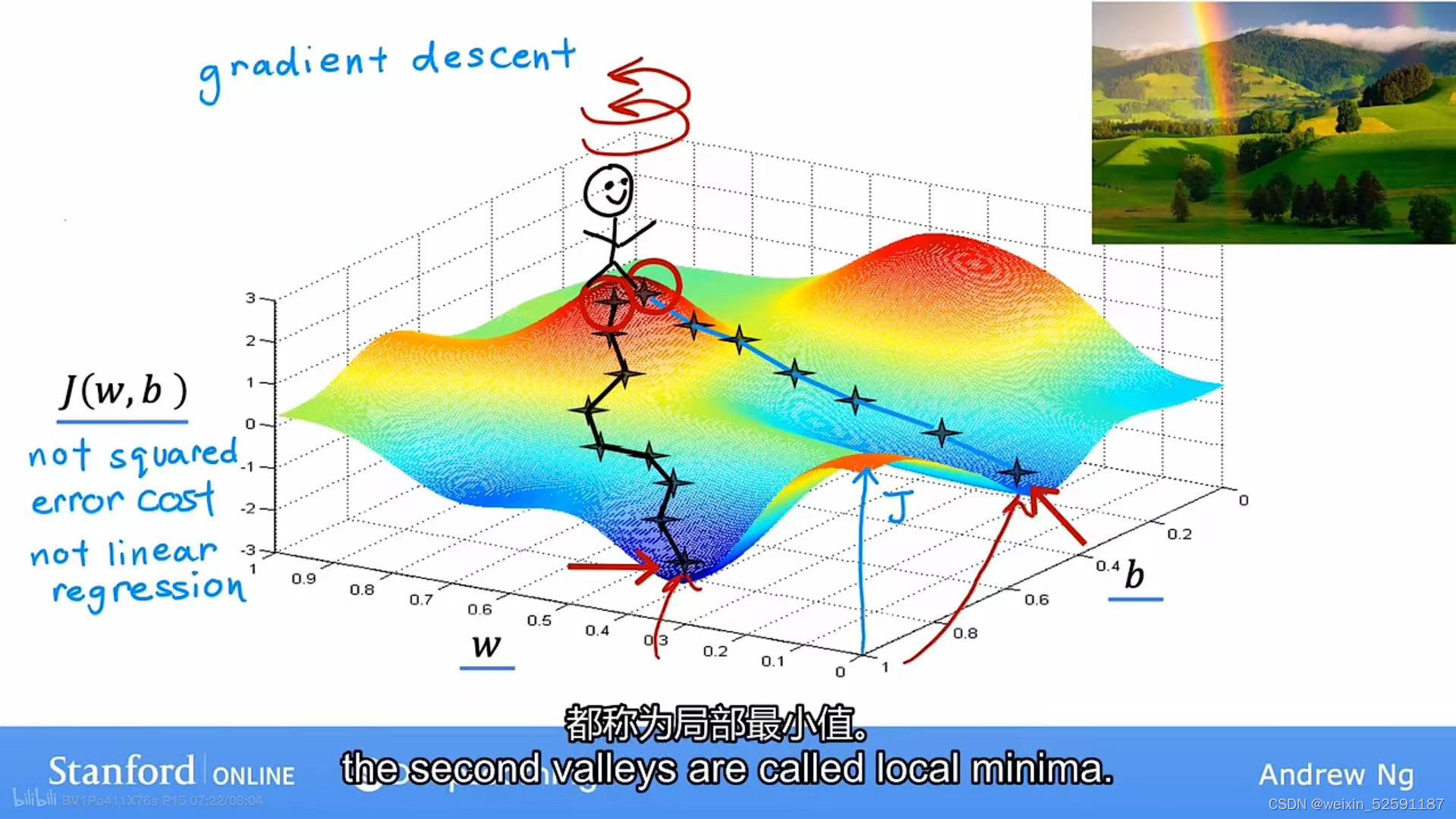
③但是梯度下降可能得到不同的最小值,这个最小值称为局部最小值(local minima):
4.2梯度下降的实现
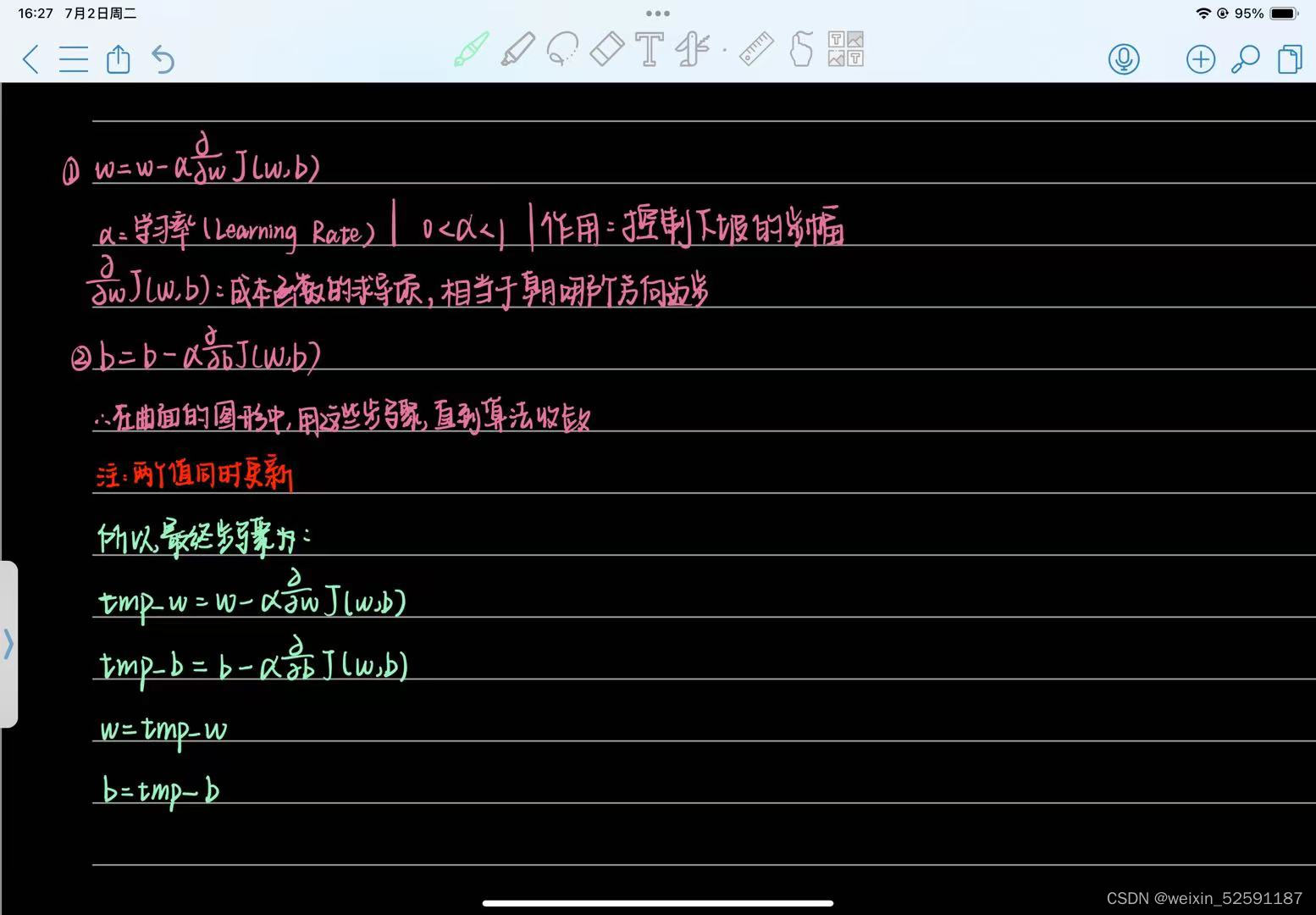
一、公式实现:
注意:w和b一定要同步更新

相关参数的解释:
二、公式理解:
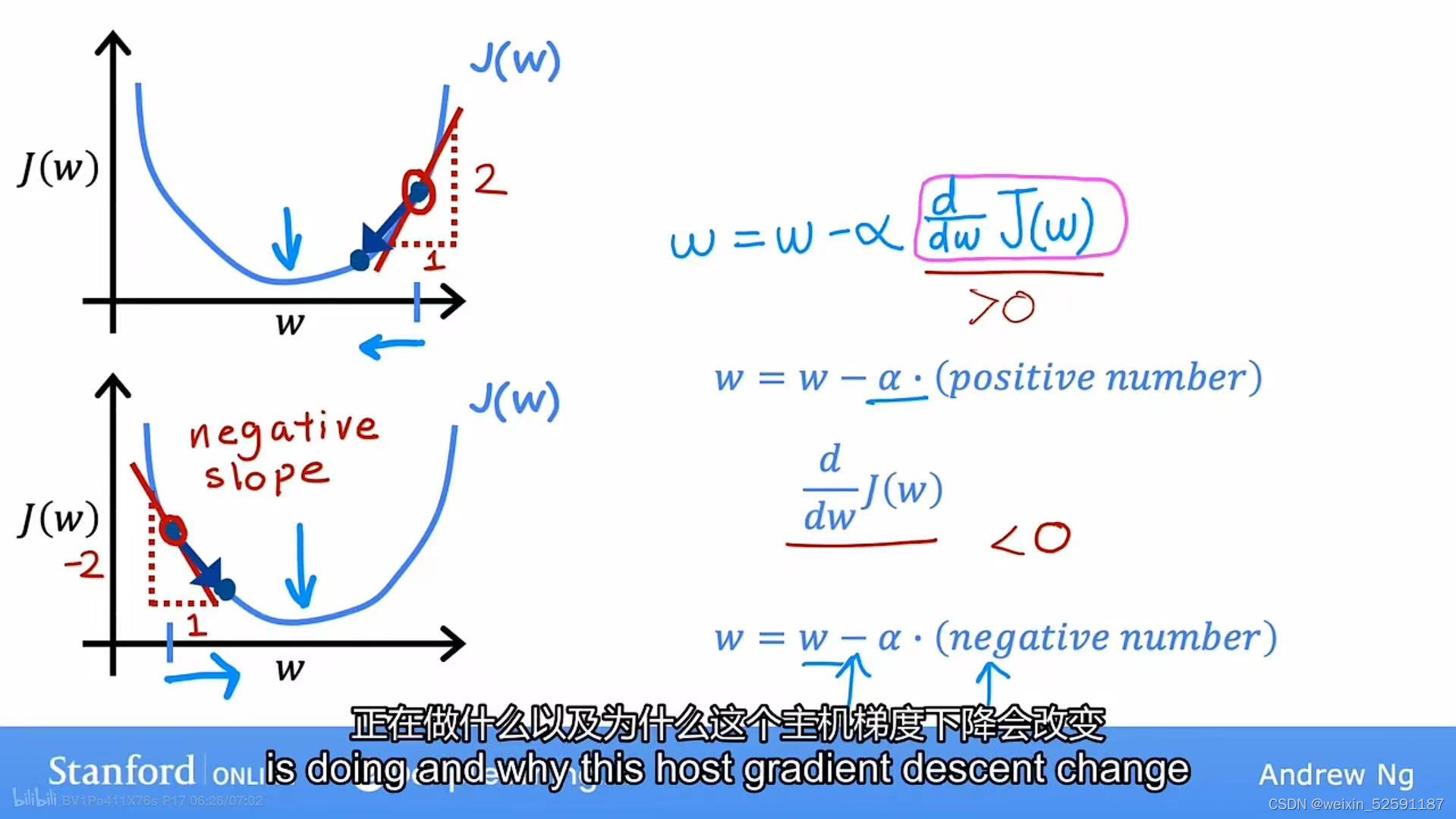
①先假设b为0,只看J(w)和 w 的关系:
②假设从J(w)的一点出发,梯度下降做的是将w更新为w减去学习率乘以导数
③更新后的w是w-学习率*正数
④在图中,正是向左移动,J(w)正在降低,越来越接近最小值
⑤第二个图是另一种情况,假设开始点为左边,道理同上1~4
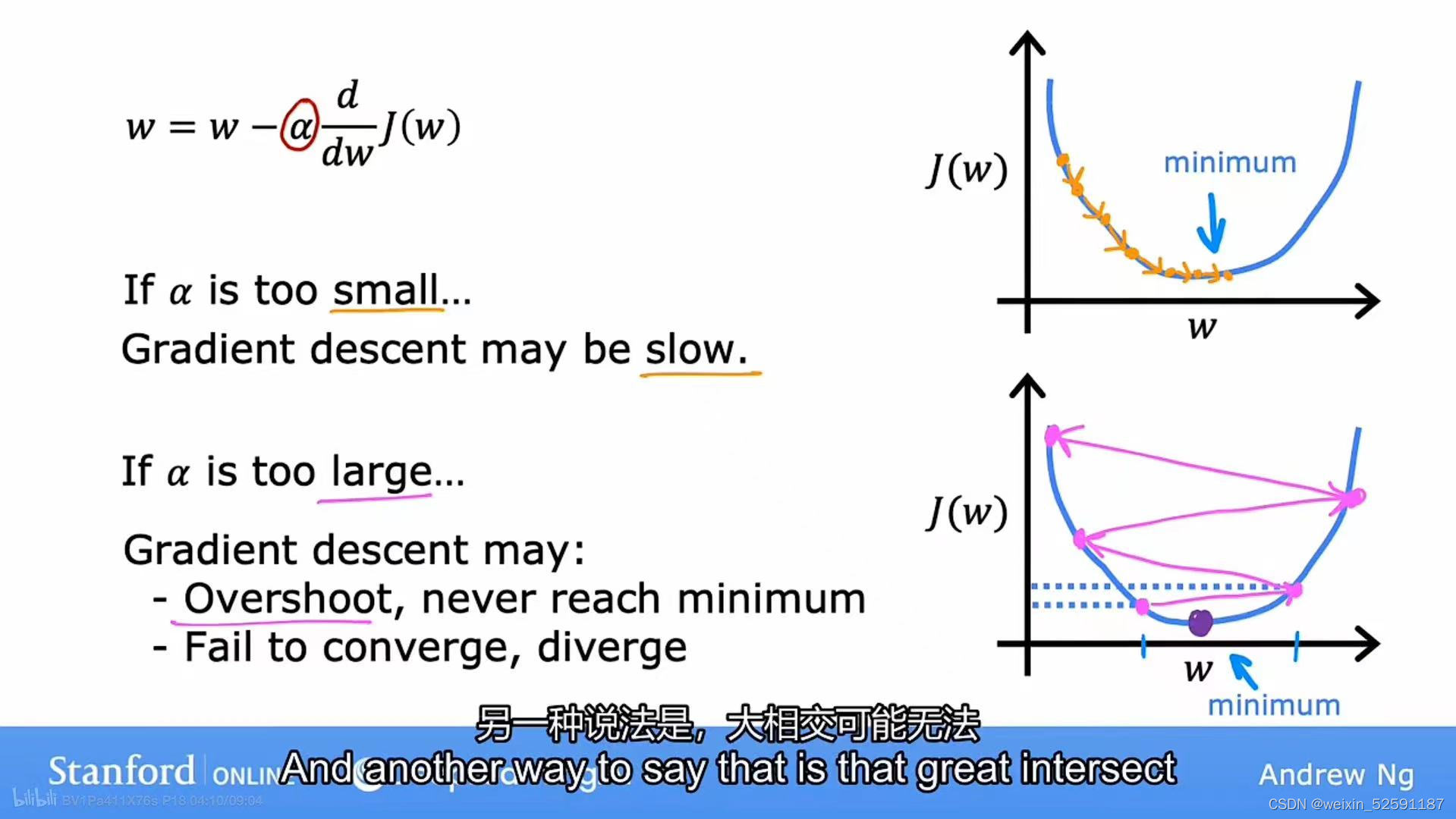
4.4学习率
一、认识学习率
学习率过大or过小都会影响到梯度下降:
①如果太小:导数项乘以了一个非常小的数字-->降低了J,但是速度非常慢
②如果太大:更新步数太大-->错过了J的最小值,并且可能永远不会到最小值
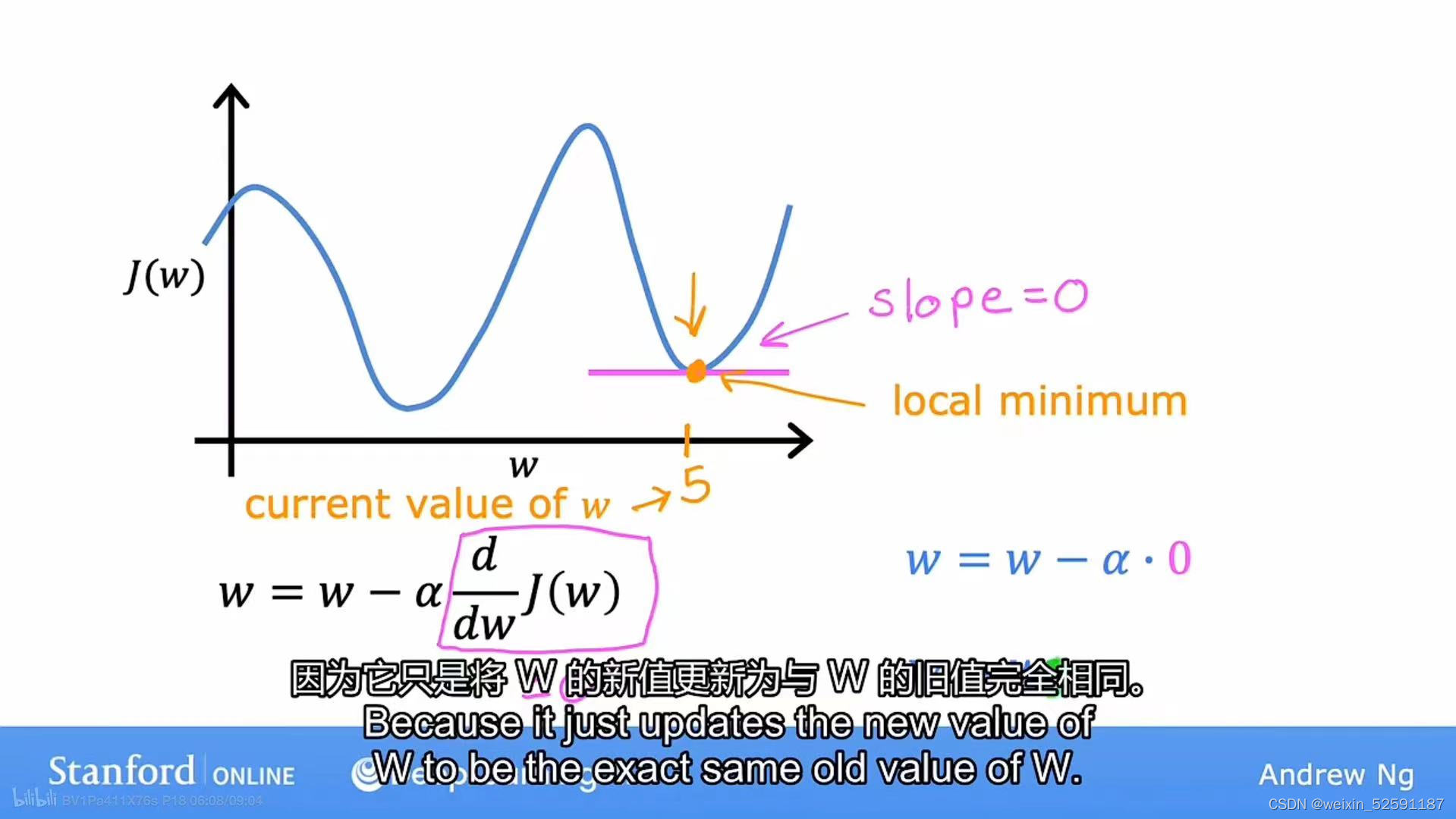
二、特殊情况:
假如成本函数J有两个局部最小值:当w位于局部最小值时,斜率=导数=0,w=w-0
结论:当处于局部最小值时,梯度下降会使w保持不变
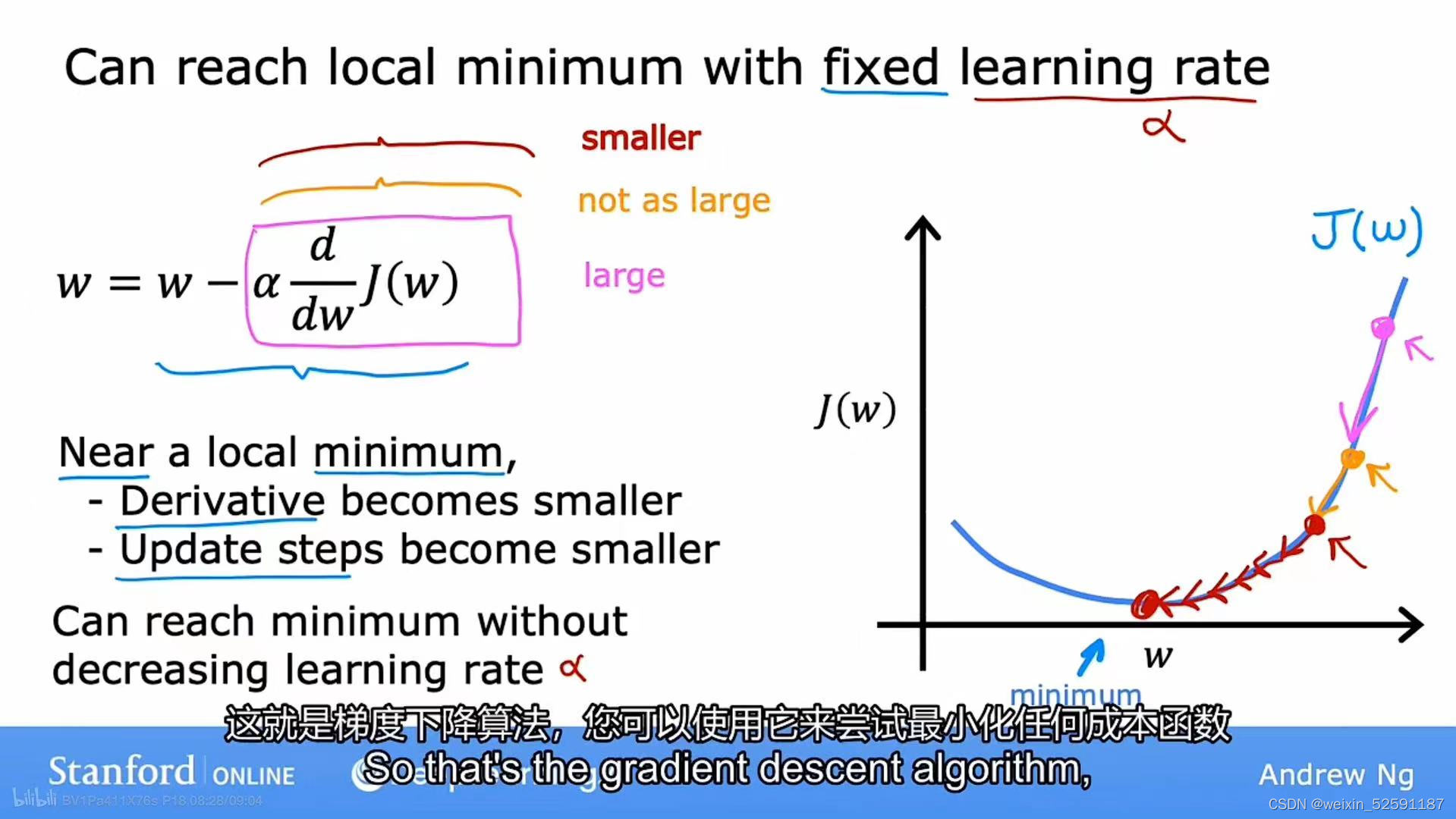
三、为什么梯度下降可以达到局部最小值&使用固定的:
下图中,由于斜率(导数)逐渐变小,所以移动的步伐逐渐变小,当接近最小值时,会采用非常小的步骤,直到到达最终的局部最小值。
4.5用于线性回归的梯度下降
使用微机分可以得到导数部分的式子:

推导过程:

一、线性回归中的梯度下降:
公式代入:

二、梯度下降的运行:
①左上表示随着梯度下降的运行,直线也更好的拟合数据分布;右上标识J(w,b)也越来越小
②这个过程称为批量梯度下降(Batch gradient descent):梯度下降的每一步,我们都在查看所有的训练示例,不仅仅是训练数据的一个子集

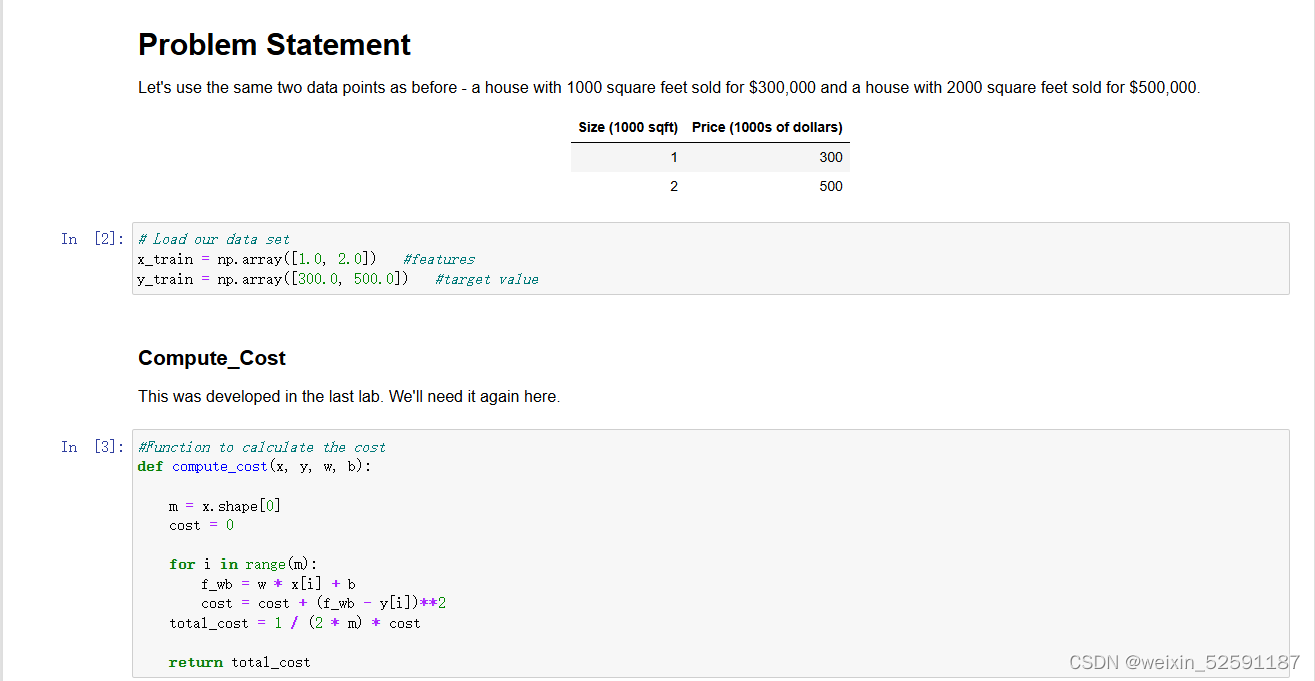
4.6代码
一、代价函数计算
二、下降函数计算:
def compute_gradient(x, y, w, b):
"""
Computes the gradient for linear regression
Args:
x (ndarray (m,)): Data, m examples
y (ndarray (m,)): target values
w,b (scalar) : model parameters
Returns
dj_dw (scalar): The gradient of the cost w.r.t. the parameters w
dj_db (scalar): The gradient of the cost w.r.t. the parameter b
"""
# Number of training examples
m = x.shape[0]
dj_dw = 0
dj_db = 0
for i in range(m):
f_wb = w * x[i] + b
dj_dw_i = (f_wb - y[i]) * x[i]
dj_db_i = f_wb - y[i]
dj_db += dj_db_i
dj_dw += dj_dw_i
dj_dw = dj_dw / m
dj_db = dj_db / m
return dj_dw, dj_db三、下降函数实现和记录:
每完成总迭代次数的10%,打印迭代次数、当前成本值、梯度 dj_dw 和 dj_db 的值,以及当前的 w 和 b 值。
w = copy.deepcopy(w_in) # avoid modifying global w_in
# An array to store cost J and w's at each iteration primarily for graphing later
J_history = []
p_history = []
b = b_in
w = w_in
for i in range(num_iters):
# Calculate the gradient and update the parameters using gradient_function
dj_dw, dj_db = gradient_function(x, y, w , b)
# Update Parameters using equation (3) above
b = b - alpha * dj_db
w = w - alpha * dj_dw
# Save cost J at each iteration
if i<100000: # prevent resource exhaustion
J_history.append( cost_function(x, y, w , b))
p_history.append([w,b])
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters/10) == 0:
print(f"Iteration {i:4}: Cost {J_history[-1]:0.2e} ",
f"dj_dw: {dj_dw: 0.3e}, dj_db: {dj_db: 0.3e} ",
f"w: {w: 0.3e}, b:{b: 0.5e}")
return w, b, J_history, p_history #return w and J,w history for graphing结果:
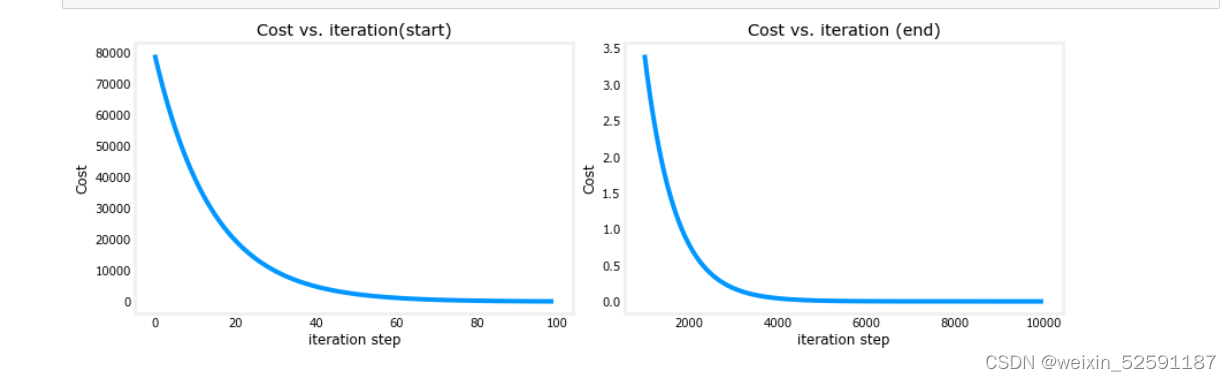
代价与迭代的关系图是衡量梯度下降过程的有用方法。在成功的运行中,成本应该总是降低的。最初成本的变化是如此之快,用不同的尺度来绘制最初的坡度和最终的下降是很有用的。在下面的图表中,请注意轴上的成本比例和迭代步骤。
















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









