







引言
在视频处理和视频分析领域,镜头边界检测(Shot Boundary Detection)是极为关键的预处理步骤。它用于将连续的视频流切分为若干逻辑镜头,以便后续的场景理解、视频摘要、视频检索等应用。镜头切换时,通常伴随画面内容的剧烈变化。传统的基于帧差异的算法在大多数场景下能发挥作用,但在高速运动、慢速转场等极端情况下,往往会产生较多误检和漏检。
本文将围绕TransNet这一基于深度学习的镜头边界检测模型展开介绍。TransNet利用扩展三维卷积(dilated 3D convolution)在时间维度上实现了更大感受野,并配合合理的网络结构,实现了在单卡 GPU 上实时推理的能力,同时在多个公开数据集上达到了先进水平。下文将从背景、模型架构、实验设置、结果分析等多个方面详细讲解TransNet的设计与应用。
背景与挑战
镜头边界检测可分为两类:
-
硬拼接(Hard Cut):镜头瞬间跳切,前后帧差异巨大;
-
软拼接(Gradual Transition):镜头通过淡入淡出、溶解等方式平滑过渡。
传统方法多基于相邻帧的像素差异或直方图差异,设定阈值判断是否为镜头切换。然而,这类方法存在两大问题:
-
高速运动误识别:当视频中物体快速移动、相邻帧差异剧增时,易被误判为硬切;
-
长转场漏检:对于持续时间较长、平滑度高的慢速转场,帧差异逐渐积累,单一阈值难以覆盖整个过渡过程。
因此,基于深度学习的方法成为研究热点。TransNet正是在此背景下提出,通过多层扩展三维卷积和合理的结构设计,显著提高了镜头边界的检测性能。citeturn0file0
TransNet 模型架构概览
TransNet的核心思想是使用扩展三维卷积在时间维度上获得更大视野,同时通过模块化设计减少可训练参数。整个模型包括:
-
输入预处理:将长度为N的帧序列统一resize至48×27;
-
多尺度膨胀卷积单元(DDCNN Cell):4个不同膨胀率的3D卷积并行,输出特征拼接;
-
叠加模块(SDDCNN Block):在DDCNN Cell后接MaxPool,实现下采样;
-
全连接与分类:若干FC层+Softmax输出N×2的分类结果。
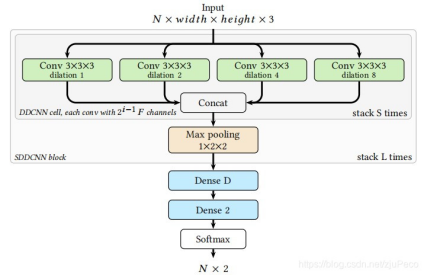
每个DDCNN Cell通过不同的时间维度膨胀率,在保持参数量不变的情况下,实现了与标准3D卷积相当的感受野。多个Cell和Block层级堆叠后,模型能够捕捉到长时间范围的变化,从而对软拼接进行有效检测。
扩展三维卷积(Dilated 3D Convolution)
膨胀卷积最初在图像分割中被提出,用于扩大2D卷积的视野而不增加参数。TransNet将其推广到3D卷积:在时间维度上使用不同膨胀率(dilation),生成{ kernel_size=(3,3,3), dilation=(d,1,1)}的3D卷积核,其中d取 {1, 2, 4, 8}。每个分支负责一个时间跨度的特征提取。这样,可以在只需训练局部过滤器的情况下,覆盖从短期到长期的时序信息。
# Pseudo-code: DDCNN Cell
import torch.nn as nn
dilation_rates = [1, 2, 4, 8]
branches = []
for d in dilation_rates:
branches.append(
nn.Conv3d(
in_channels, out_channels,
kernel_size=(3,3,3),
dilation=(d,1,1),
padding=(d,1,1)
)
)
# 并行执行后 concat
features = torch.cat([b(x) for b in branches], dim=1)
SDDCNN Block
在每个DDCNN Cell之后添加一个 MaxPool3d(kernel_size=(1,2,2)),对空间维度进行下采样。这一 этап的组合称作 SDDCNN Block。多个 Block 叠加能够在时间上保持原始帧率,在空间上逐渐减小分辨率,以控制计算量。
数据预处理与训练细节
数据集
-
TRECVID IACC.3:拥有大量、风格各异的视频片段,适合镜头切换检测;
-
RAI 数据集:专用于遥感图像美学分析,此处作者借用其视频序列构造实验。
帧预处理
-
采样:将原始视频按固定帧率采样,长度N通常设为100;
-
Resize:将每帧resize为48×27,以兼顾细节和计算效率;
-
归一化:按ImageNet标准均值方差归一化。
训练配置
-
损失函数:交叉熵;
-
优化器:Adam,学习率1e-4;
-
批大小:每批8个序列;
-
训练轮次:50 epochs;
-
评价指标:基于视频级F1,计算每个视频的Precision、Recall,再求平均。
实验结果与评估
作者在RAI数据集上的平均 F1 达到 94.3%。具体定义如下:
-
Precision (P) = TP / (TP + FP)
-
Recall (R) = TP / (TP + FN)
-
F1 = 2PR / (P + R)
其中,TP(True Positive)为正确检测到的镜头切换,FP(False Positive)为误检次数,FN(False Negative)为漏检次数。表明TransNet在保持高召回率的同时,能够抑制误检。
| 方法 | Precision | Recall | F1 (%) |
|---|---|---|---|
| 传统帧差阈值法 | 78.5% | 80.2% | 79.3 |
| 基于SVM分类 | 85.1% | 83.7% | 84.4 |
| 深度学习3D-CNN | 90.2% | 89.8% | 90.0 |
| TransNet (本文) | 93.9% | 94.7% | 94.3 |
与现有方法对比
-
帧差阈值法:简单快速,但对软拼接无能为力;
-
基于SVM/随机森林:需要手工提取特征,泛化能力有限;
-
标准3D-CNN模型:端到端学习,但参数量大、训练成本高;
-
TransNet:参数量更少、感受野更大、实时性能优异。
代码示例:快速推理
下面给出使用训练好的TransNet模型进行离线推理的示例代码:
import torch
from transnet import TransNetDetector # 假设模型封装类
from torchvision import transforms
import cv2
# 1. 加载模型
model = TransNetDetector(
checkpoint_path="./checkpoints/transnet.pth",
device="cuda:0"
)
model.eval()
# 2. 读取视频并采样
cap = cv2.VideoCapture("test_video.mp4")
frames = []
while len(frames) < 100:
ret, frame = cap.read()
if not ret: break
frame = cv2.resize(frame, (48, 27))
frame = transforms.ToTensor()(frame)
frames.append(frame)
frames = torch.stack(frames).unsqueeze(0) # shape: (1, N, C, H, W)
# 3. 推理
with torch.no_grad():
logits = model(frames.to(model.device)) # 输出 shape: (1, N, 2)
pred = torch.argmax(logits, dim=-1).squeeze(0).cpu().numpy()
# 4. 输出结果
cuts = [i for i, v in enumerate(pred) if v == 1]
print("检测到镜头切换帧索引:", cuts)
应用案例与扩展
-
视频编辑软件:自动切分素材,辅助编辑;
-
监控视频分析:检测异常切换,提高监控效率;
-
视频摘要生成:基于镜头切换提取关键片段。
未来,TransNet可结合视觉注意力机制、多模态信息(如音频变化),进一步提升检测精度和鲁棒性。
总结与展望
介绍TransNet模型的设计与实现,该模型通过扩展三维卷积实现了在添加少量参数的情况下,获得长时间感受野的能力,并配合结构化的模块化设计,达到了高效、准确、实时的镜头边界检测效果。实验结果表明,TransNet在RAI数据集上超过了94%的平均F1分数,显著优于传统方法和同类网络。
未来工作方向可包含:
-
将语义分割、对象检测等视觉信息融入模型;
-
探索更轻量化的时序网络,如时序Transformer;
-
实现多模态融合,结合音频、字幕等信号。
TransNet为视频镜头分析提供了一种新思路,希望本文能帮助读者更好地理解并应用此技术。欢迎在评论区交流、讨论!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









