







1. 引言
目标检测技术在计算机视觉领域占据重要地位,而YOLO(You Only Look Once)系列模型因其速度快、精度高而备受关注。YOLOv8作为最新版本,不仅在精度和推理速度方面有所提升,还对模型架构进行了优化。本文将深入解析YOLOv8的核心结构,包括Backbone(主干网络)、Neck(颈部网络)和Head(检测头),并通过代码示例帮助理解其工作原理。
2. YOLOv8架构概述
YOLOv8的模型架构主要由以下三个部分组成:
- Backbone(主干网络): 负责特征提取。
- Neck(颈部网络): 进行特征融合,提高检测能力。
- Head(检测头): 负责最终的目标分类和回归。
YOLOv8相较于前几代YOLO模型,主要引入了如下改进:
- 改进的Backbone: 采用更高效的特征提取模块C2f(CSP2X)。
- 优化的Neck结构: 采用BiFPN(双向特征金字塔网络)增强不同尺度的特征融合。
- Anchor-free检测头: 采用FCOS风格的检测方法,提高了小目标检测性能。
下图展示了YOLOv8的整体架构(示意图):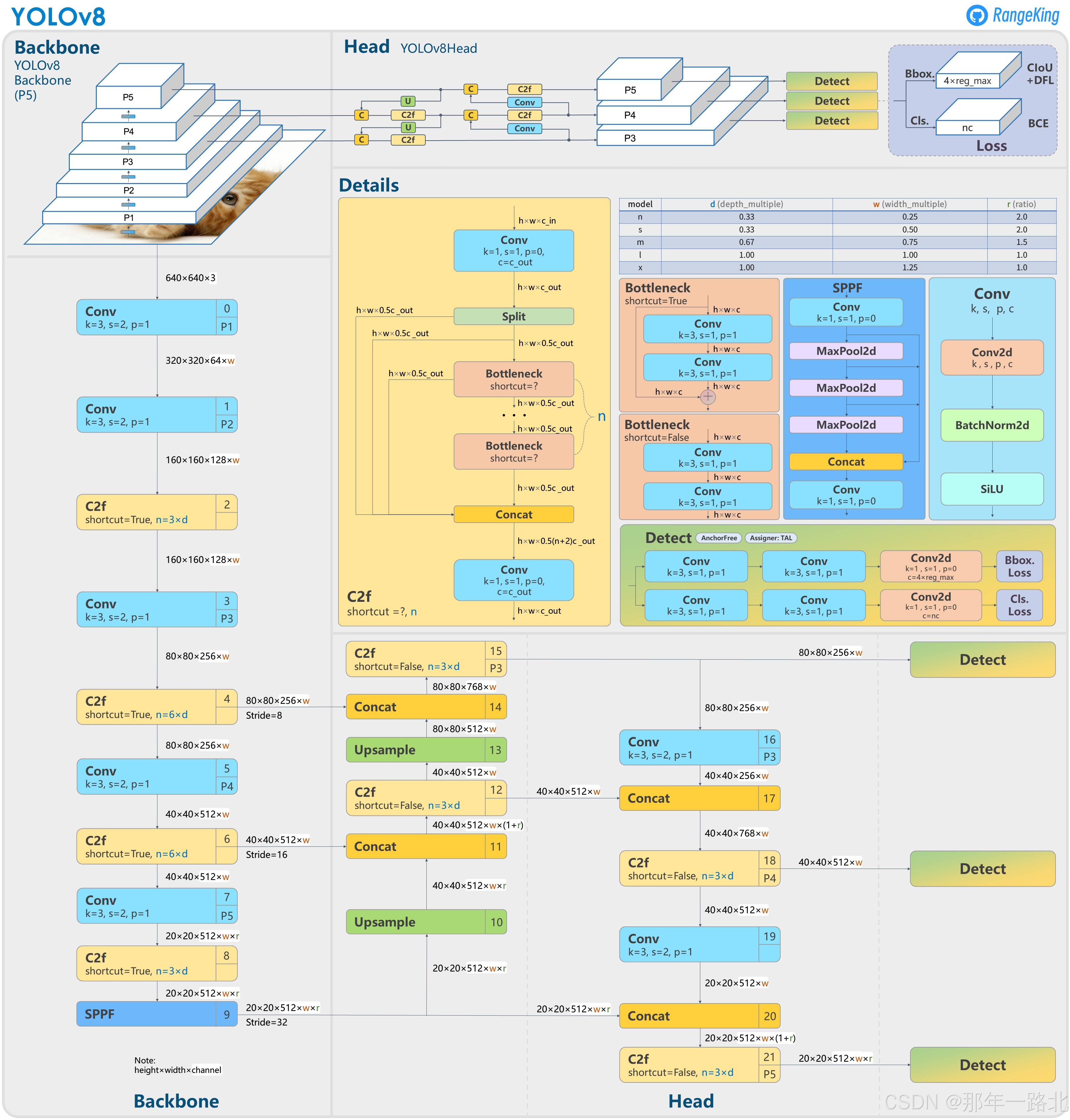
3. Backbone(主干网络)
Backbone的主要作用是从输入图像中提取特征。YOLOv8采用了CSPDarknet风格的Backbone,并对其进行优化,核心组件包括:
- C2f(CSP2X)模块: 用于高效特征提取。
- Focus层: 通过切片操作减少计算量(已被C2f替代)。
- SILU(Swish)激活函数: 提高梯度流动,提高模型的表达能力。
3.1 C2f模块详解
C2f(Cross Stage Partial v2)是YOLOv8中的核心改进模块,相较于CSP(Cross Stage Partial)结构,C2f减少了计算开销,同时保持了良好的特征表达能力。
C2f代码实现:
import torch
import torch.nn as nn
class C2f(nn.Module):
def __init__(self, in_channels, out_channels, num_blocks=1):
super(C2f, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels // 2, kernel_size=1)
self.conv2 = nn.Conv2d(out_channels // 2, out_channels, kernel_size=3, padding=1, stride=1)
self.blocks = nn.Sequential(
*[nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1) for _ in range(num_blocks)]
)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x1)
return self.blocks(x2)
4. Neck(颈部网络)
Neck的主要作用是融合来自Backbone的不同层特征,以提高检测效果。YOLOv8的Neck采用了BiFPN(双向特征金字塔网络),主要特性包括:
- 多尺度特征融合: 结合来自不同层的特征,提高对小目标的检测能力。
- 轻量化设计: 采用深度可分离卷积减少计算量。
4.1 BiFPN结构
BiFPN(Bidirectional Feature Pyramid Network)是一种增强版FPN,能够有效融合不同尺度的特征。
BiFPN代码实现:
class BiFPN(nn.Module):
def __init__(self, in_channels, out_channels):
super(BiFPN, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return self.conv3(x)
5. Head(检测头)
YOLOv8的检测头(Head)负责生成最终的目标检测结果,主要特点包括:
- Anchor-Free设计: 采用类似FCOS的目标检测方法,避免了传统的Anchor机制,提高了泛化能力。
- 解耦Head(Decoupled Head): 采用独立的分类分支和回归分支,提高检测精度。
5.1 解耦Head的实现
YOLOv8的Head采用了两条独立的路径进行目标分类和回归,提高了检测精度。
Decoupled Head代码示例:
class YOLOv8Head(nn.Module):
def __init__(self, num_classes, in_channels):
super(YOLOv8Head, self).__init__()
self.cls_layer = nn.Conv2d(in_channels, num_classes, kernel_size=1)
self.reg_layer = nn.Conv2d(in_channels, 4, kernel_size=1)
def forward(self, x):
cls_preds = self.cls_layer(x)
reg_preds = self.reg_layer(x)
return cls_preds, reg_preds
6. 代码示例:YOLOv8完整架构
class YOLOv8(nn.Module):
def __init__(self, num_classes=80):
super(YOLOv8, self).__init__()
self.backbone = C2f(in_channels=3, out_channels=512)
self.neck = BiFPN(in_channels=512, out_channels=256)
self.head = YOLOv8Head(num_classes, in_channels=256)
def forward(self, x):
x = self.backbone(x)
x = self.neck(x)
cls_preds, reg_preds = self.head(x)
return cls_preds, reg_preds
7. 总结
本文详细解析了YOLOv8的模型结构,包括Backbone(特征提取)、Neck(特征融合)和Head(最终检测)部分。YOLOv8的优化点包括C2f模块、BiFPN特征融合以及Anchor-Free检测头,使其在精度和速度上相较于前代模型有了显著提升。
欢迎关注、点赞和评论,更多深度学习相关内容请持续关注!


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









