







引言
Mask-RCNN是Faster-RCNN的扩展版本,它不仅能够完成对象检测任务,还能进行像素级的实例分割,是当前计算机视觉领域的热门模型之一。本文将带您从Mask-RCNN的基本原理入手,结合PyTorch实现对象检测和实例分割的完整流程。
一. Mask-RCNN模型结构与特点
1. Mask-RCNN模型结构与特点
Mask-RCNN 是一种用于对象检测和实例分割的深度学习模型。它在 Faster-RCNN 的基础上引入了一个新的分支,用于预测每个目标的像素级分割掩码。以下是它的核心特点和模型结构:
1.1 Mask-RCNN模型结构
Mask-RCNN 的主要结构包括以下几个部分:
-
Backbone(主干网络)
- 用于提取输入图像的特征。
- 常用的主干网络包括 ResNet(带或不带 FPN)等。
- 特点:可以捕获多尺度特征,提高对象检测性能。
-
FPN(Feature Pyramid Network,可选)
- 用于生成多尺度的特征图,提高小目标检测的效果。
- 如果使用 FPN,则特征图会从多层特征中整合。
-
RPN(Region Proposal Network)
- 提供候选区域建议(Region Proposals)。
- 输出候选框及其分类(是否为目标)。
-
ROI Align
- 解决 Faster-RCNN 中的 ROI Pooling 精度问题,通过双线性插值对特征进行对齐。
- 特点:在边界框上实现亚像素级的精确对齐,提高了实例分割任务的性能。
-
检测头(Classification & Box Regression)
- 两个分支:
- 分类分支:预测候选框中的目标类别。
- 边界框回归分支:精确调整候选框的位置。
- 两个分支:
-
Mask分割头(FCN)
- 使用一个全卷积网络(FCN)预测目标的分割掩码。
- 每个类别一个单独的二值掩码。
- 输出:分割掩码的像素级别预测,与输入候选框对齐。
1.2 Mask-RCNN的多任务损失
Mask-RCNN 使用多任务学习框架,损失函数包括以下三部分:
- 分类损失:用于预测类别。
- 边界框回归损失:用于精确调整候选框位置。
- 掩码损失:用于预测分割掩码,采用像素级的交叉熵损失。
公式:
L=Lcls+Lbbox+LmaskL = L_{cls} + L_{bbox} + L_{mask}
1.3 Mask-RCNN与Faster-RCNN的比较
| 特性 | Faster-RCNN | Mask-RCNN |
|---|---|---|
| 功能 | 对象检测 | 对象检测 + 实例分割 |
| 新增模块 | 无 | 增加了分割头(FCN) |
| ROI处理 | ROI Pooling | ROI Align(更精确) |
| 损失函数 | 分类损失 + 回归损失 | 分类损失 + 回归损失 + 掩码损失 |
| 性能 | 精度较高,缺少分割功能 | 精度更高,支持像素级分割 |
1.4 Mask-RCNN的主要优点
- 功能强大:支持对象检测和像素级实例分割,适合复杂场景。
- 灵活扩展:通过简单地增加分支模块,可以完成更多任务(如关键点检测、全景分割)。
- 高精度:ROI Align 改进了特征对齐精度,提高了整体性能。
1.5 Mask-RCNN模型的输出
boxes:目标的边界框坐标。labels:目标类别。scores:目标的置信度分数。masks:目标的分割掩码,形状与boxes一一对应。
Mask-RCNN 在对象检测领域是一种功能全面且表现优异的模型,特别适合需要像素级分割的任务,如医学图像分析、自动驾驶等应用场景。
二. Mask-RCNN的模型构建
我使用了Torchvision提供的预训练模型maskrcnn_resnet50_fpn,并根据需要进行调整,例如修改类别数量。
示例代码:构建Mask-RCNN模型
import torchvision
import torch
# 构建Mask-RCNN模型
def get_model_instance_segmentation(num_classes):
# 加载预训练的Mask-RCNN模型
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# 替换分类头
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
# 替换Mask头
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = torchvision.models.detection.mask_rcnn.MaskRCNNPredictor(in_features_mask,
hidden_layer,
num_classes)
return model
# 实例化模型,假设有2个类别(背景+行人)
model = get_model_instance_segmentation(num_classes=2)
三. 数据集准备与训练
训练Mask-RCNN需要一个格式化的数据集,例如COCO格式或自定义格式。以下代码展示如何定义一个自定义数据集类,并进行模型训练。
示例代码:自定义数据集类
from PIL import Image
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms as T
import os
class PennFudanDataset(Dataset):
def __init__(self, root_dir):
self.root_dir = root_dir
self.transforms = T.Compose([T.ToTensor()])
self.imgs = sorted(os.listdir(os.path.join(root_dir, '')))
self.masks = sorted(os.listdir(os.path.join(root_dir, '')))
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, '', self.imgs[idx])
mask_path = os.path.join(self.root_dir, '', self.masks[idx])
img = Image.open(img_path).convert("RGB")
mask = Image.open(mask_path)
mask = np.array(mask)
obj_ids = np.unique(mask)[1:] # Skip the background id (0)
masks = (mask == obj_ids[:, None, None]).astype(np.uint8)
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.ones((num_objs,), dtype=torch.int64)
masks = torch.as_tensor(masks, dtype=torch.uint8)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {
"boxes": boxes,
"labels": labels,
"masks": masks,
"image_id": image_id,
"area": area,
"iscrowd": iscrowd
}
img = self.transforms(img) # Apply transform to image
return img, target
示例代码:模型训练
import torch
from torch.utils.data import DataLoader
# 训练相关参数
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
dataset = CustomDataset(root="path/to/dataset", transforms=None)
data_loader = DataLoader(dataset, batch_size=2, shuffle=True, num_workers=4)
# 实例化模型并移动到设备
model = get_model_instance_segmentation(num_classes=2)
model.to(device)
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.005, momentum=0.9, weight_decay=0.0005)
# 训练模型
for epoch in range(10): # 训练10个周期
model.train()
for images, targets in data_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
# 计算损失并反向传播
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/10], Loss: {losses.item()}")
四. 预测与可视化
训练完成后,可以使用训练好的模型对新图像进行预测,并将结果进行可视化。
示例代码:预测
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def visualize_predictions(image, predictions):
fig, ax = plt.subplots(1, figsize=(12, 9))
ax.imshow(image)
for box, mask in zip(predictions[0]['boxes'], predictions[0]['masks']):
x_min, y_min, x_max, y_max = box.int()
rect = patches.Rectangle((x_min, y_min), x_max - x_min, y_max - y_min, linewidth=2, edgecolor='r', facecolor='none')
ax.add_patch(rect)
# 绘制掩码
mask = mask[0].cpu().numpy()
ax.imshow(mask, alpha=0.5)
plt.show()
# 加载测试图像
test_image = Image.open("path/to/test/image.jpg").convert("RGB")
test_image_tensor = transform(test_image).unsqueeze(0).to(device)
# 推理
model.eval()
with torch.no_grad():
predictions = model(test_image_tensor)
visualize_predictions(test_image, predictions)
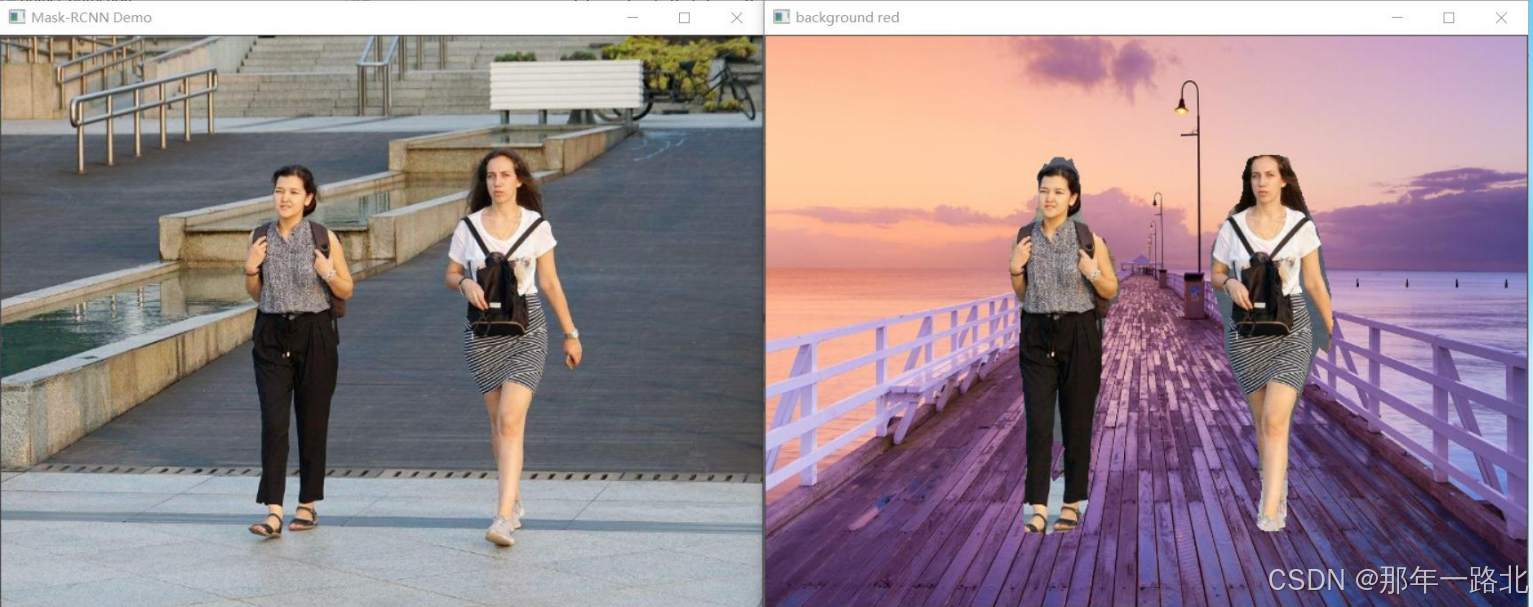
实验结果可视化:
总结
我分析了Mask-RCNN模型的架构,从Mask-RCNN模型的原理出发,结合PyTorch实现了对象检测与实例分割的完整流程,包括模型构建、自定义数据集、模型训练及预测可视化。


















 6869
6869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









