







无知的我正在复习MySQL进阶知识。。。。
笔记特点是 我重新整理了涉及资料的一些语言描述、排版,而使用了自己比较容易理解的描述、同样是回答了一些常见关键问题
如果有遇到有任何无法进展问题或者疑惑的地方,应该在讨论区留言 或者 其他途径以寻求及时的帮助,以加快学习效率 或者 培养独立解决问题的能力、扫清盲点、补充细节
事务原理
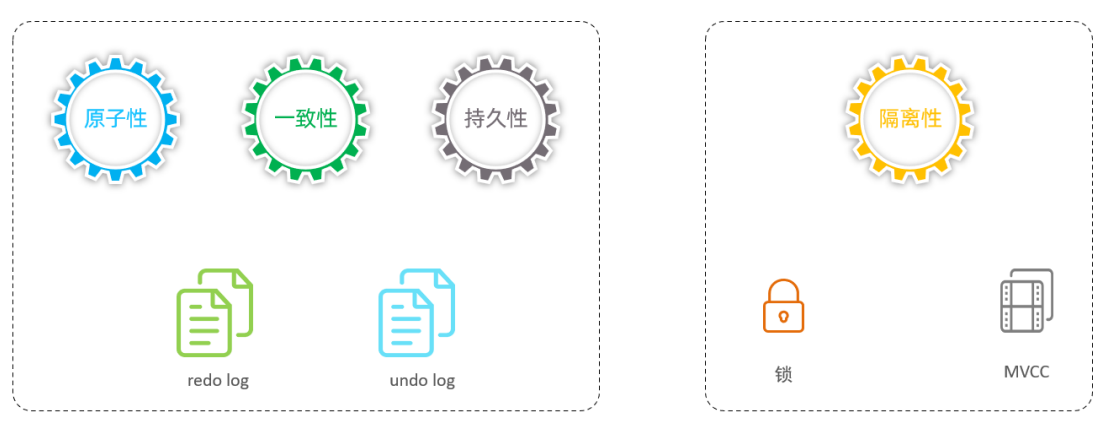
原子性、一致性、持久化实际上是由InnoDB中的两份日志来保证的,一份是redo log日志,一份是undo log日志。 而持久性是通过数据库的锁,加上MVCC来保证的。
事务类型及定义
原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
redo log
redo log 定义及作用
(重做日志)记录的是事务提交时数据页的物理修改,是用来实现事务的持久性。
redo log 内部结构
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo logfile),前者是在内存中,后者在磁盘中。
redo log 机制
当事务提交之后会把所有修改信息都存到该日志文件中, 用于在刷新脏页到磁盘,发生错误时, 进行数据恢复使用。
redo log 机制流程图
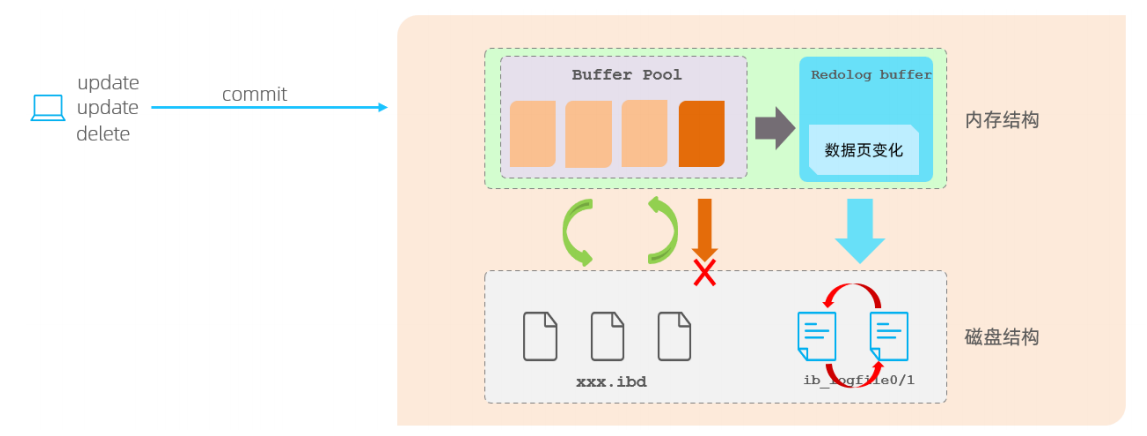
- 当对缓冲区的数据进行增删改之后,
- 会首先将操作的数据页的变化,记录在redolog buffer中。
- 在事务提交时,会将redolog buffer中的数据刷新到redolog磁盘文件中。
- 过一段时间之后,如果刷新缓冲区的脏页到磁盘时,发生错误,此时就可以借助于redolog进行数据恢复,这样就保证了事务的持久性。
- 而如果脏页成功刷新到磁盘 或 或者涉及到的数据已经落盘,此时redolog就没有作用了,就可以删除了,所以存在的两个redolog文件是循环写的。
引出问题 为什么每一次提交事务,要刷新redo log 到磁盘中呢,而不是直接将buffer pool中的脏页刷新到磁盘呢 ?
因为在业务操作中,我们操作数据一般都是随机读写磁盘的,而不是顺序读写磁盘。
而redo log在往磁盘文件中写入数据,由于是日志文件,所以都是顺序写的。
=>顺序写的效率,要远大于随机写。 这种先写日志的方式,称之为 WAL(Write-Ahead Logging)。
undo log
undo log 定义及作用
(回滚日志)用于记录数据被修改前的信息 , 作用包含两个 : 提供回滚(保证事务的原子性) 和 MVCC(多版本并发控制) 。
undo log 机制
undo log和redo log记录物理日志不一样,它是逻辑日志。
逻辑日志与物理日志的区别
- 逻辑日志是记录每一步执行的操作
- 物理日志是记录存放的数据
举例说明 undo log 机制
可以认为当delete一条记录时,undo log中会记录一条对应的insert记录
反之亦然,当update一条记录时,它记录一条对应相反的update记录。当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容并进行回滚。
undo log 操作
Undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC。
Undo log存储:undo log采用段的方式进行管理和记录,存放在前面介绍的 rollback segment(回滚段)中,内部包含1024个undo log segment














 1659
1659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









