






引言 🌟
在高并发的数据库应用场景中,如何高效处理并发事务一直是一个挑战。想象一下,当成千上万的用户同时访问一个电商网站,大量的读写操作同时发生,如果没有良好的并发控制机制,数据的一致性和系统性能将面临严峻考验。🤔
MySQL作为全球最流行的关系型数据库之一,其InnoDB存储引擎实现了一种精妙的并发控制机制——多版本并发控制(MVCC)。这种机制让数据库在保证数据一致性的同时,还能提供极高的并发性能。
本文将深入剖析MySQL MVCC的工作原理,并通过Java代码示例展示其在实际应用中的表现。无论你是数据库管理员、后端开发者,还是对数据库技术感兴趣的学习者,这篇文章都将帮助你理解这一强大而复杂的技术。
MVCC基础概念 📚
什么是MVCC?
MVCC(Multi-Version Concurrency Control),即多版本并发控制,是一种用于数据库管理系统中实现并发控制的技术。简单来说,MVCC通过维护数据的多个版本,使得读操作和写操作可以在不相互阻塞的情况下进行,从而提高数据库的并发性能。
💡 核心思想:MVCC的核心思想是"读不阻塞写,写不阻塞读",这在高并发系统中尤为重要。
为什么需要MVCC?
在传统的数据库并发控制中,常用的是基于锁的机制。但锁机制存在一些问题:
- 🔒 读写互斥:读操作需要获取共享锁,写操作需要获取排他锁,读写之间相互阻塞
- 🐢 性能瓶颈:在高并发场景下,大量的锁竞争会导致系统性能下降
- 🔄 死锁风险:复杂的锁操作容易导致死锁
而MVCC通过创建数据的快照(Snapshot)来解决这些问题:
- 📸 读操作不加锁:读取的是数据的历史版本(快照),不会阻塞写操作
- ⚡ 提高并发性能:读写操作可以并行执行,大幅提升系统吞吐量
- 🛡️ 避免脏读等问题:通过版本控制确保事务隔离性
MVCC与传统锁机制的对比
| 特性 | MVCC | 传统锁机制 |
|---|---|---|
| 读写并发 | 高(读不阻塞写) | 低(读写互斥) |
| 系统开销 | 低(无需等待锁释放) | 高(锁等待和竞争) |
| 实现复杂度 | 高(需要维护版本链) | 低(锁机制相对简单) |
| 存储开销 | 高(需要存储多版本数据) | 低(无需额外存储) |
| 死锁风险 | 低(读操作不加锁) | 高(复杂锁操作易死锁) |
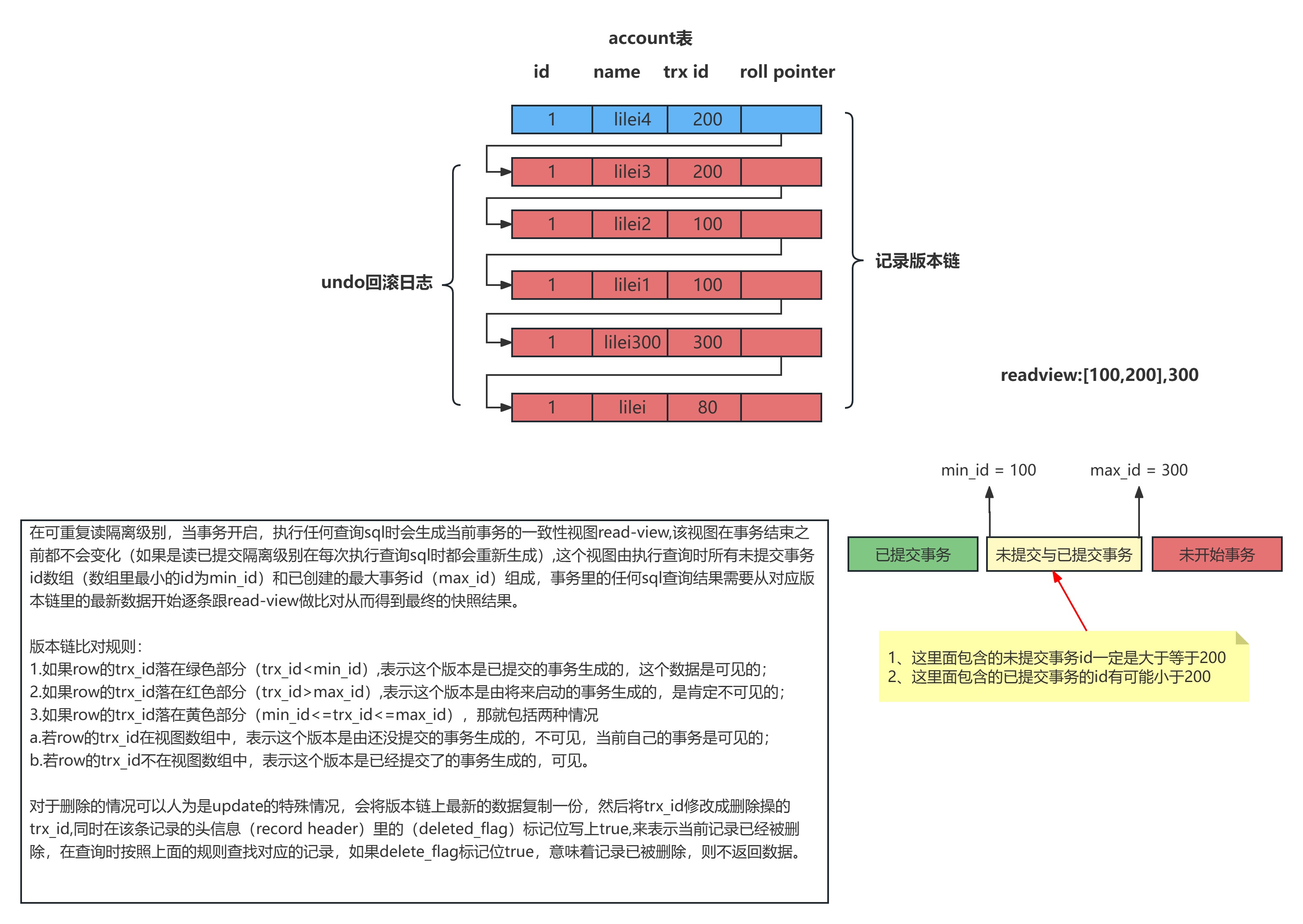
MySQL中的MVCC实现原理 🔍
MySQL的InnoDB存储引擎通过巧妙的设计实现了MVCC。要理解其工作原理,我们需要了解几个关键概念:
事务ID和隐藏字段
InnoDB为每个事务分配一个唯一的事务ID(递增的整数),并在每行记录中添加了两个隐藏字段:
- DB_TRX_ID:6字节,记录最后一次修改该行的事务ID
- DB_ROLL_PTR:7字节,回滚指针,指向该行的上一个版本(undo日志)
- DB_ROW_ID:6字节,隐含的自增ID(如果表没有主键,InnoDB会自动创建)
undo日志与版本链
当事务对数据进行修改时,InnoDB会将修改前的数据保存到undo日志中,并通过回滚指针(DB_ROLL_PTR)将这些版本连接成一个链表,形成版本链。
undo日志主要分为两种:
- 📝 insert undo log:记录插入操作,事务提交后可立即丢弃
- 📝 update undo log:记录更新和删除操作,用于MVCC和事务回滚
ReadView机制
ReadView是事务进行快照读操作时生成的读视图,用于决定当前事务能够看到哪个版本的数据。ReadView包含以下重要信息:
- trx_ids:生成ReadView时系统中活跃的事务ID列表
- up_limit_id:活跃事务列表中最小的事务ID
- low_limit_id:系统中下一个将被分配的事务ID
当事务需要读取一行记录时,会将该行的DB_TRX_ID与ReadView中的信息进行比较,以决定是否可见:
- 如果 DB_TRX_ID < up_limit_id,说明该版本是在ReadView创建前已经提交的事务生成的,可见
- 如果 DB_TRX_ID >= low_limit_id,说明该版本是在ReadView创建后才开始的事务生成的,不可见
- 如果 up_limit_id <= DB_TRX_ID < low_limit_id,需要判断DB_TRX_ID是否在trx_ids列表中:
- 如果在列表中,说明该版本是由尚未提交的事务生成的,不可见
- 如果不在列表中,说明该版本是由已经提交的事务生成的,可见
如果当前版本不可见,则沿着版本链找到下一个版本,继续进行可见性判断,直到找到可见的版本或者到达版本链的末尾。
快照读与当前读
在MySQL中,MVCC主要作用于快照读(Snapshot Read)操作:
-
快照读:普通的SELECT操作,读取的是记录的快照版本,不加锁
SELECT * FROM table WHERE id = 1; -
当前读:特殊的SELECT操作(如加锁读)以及所有的UPDATE、DELETE、INSERT操作,读取的是记录的最新版本,需要加锁
SELECT * FROM table WHERE id = 1 LOCK IN SHARE MODE; SELECT * FROM table WHERE id = 1 FOR UPDATE; UPDATE table SET column = value WHERE id = 1; DELETE FROM table WHERE id = 1;
MVCC在不同事务隔离级别下的表现 🔄
MySQL支持四种事务隔离级别,MVCC在不同隔离级别下的行为有所不同:
READ UNCOMMITTED(读未提交)
在这个级别下,事务可以读取到其他事务未提交的数据(脏读)。MVCC在此级别下基本不起作用,因为读操作会直接读取最新的数据版本,不管它是否已经提交。
READ COMMITTED(读已提交)
在这个级别下,事务只能读取到其他事务已经提交的数据,避免了脏读。MVCC的实现方式是:
- 🔄 每次读操作都创建新的ReadView
- 👀 只能看到在ReadView创建前已提交的事务所做的修改
这种实现方式可能导致不可重复读问题,因为同一事务中的多次读取可能会创建不同的ReadView,从而看到不同的数据。
REPEATABLE READ(可重复读,MySQL默认)
在这个级别下,事务在整个过程中读取到的数据是一致的,避免了不可重复读问题。MVCC的实现方式是:
- 🔒 在事务开始时创建ReadView,并在整个事务过程中使用该ReadView
- 👀 只能看到在事务开始前已提交的事务所做的修改
MySQL的InnoDB通过特殊的间隙锁(Gap Lock)机制,在REPEATABLE READ级别下也能避免大部分幻读问题。
SERIALIZABLE(串行化)
在这个级别下,所有的读操作都会被转换为锁定读(加共享锁),MVCC不再起作用。这提供了最高级别的隔离性,但并发性能最差。
Java代码实战演示 💻
下面通过Java代码示例来演示MySQL MVCC的工作原理和实际效果。
环境准备
首先,我们需要创建一个测试数据库和表结构:
CREATE DATABASE mvcc_demo;
USE mvcc_demo;
CREATE TABLE product (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
price DECIMAL(10,2) NOT NULL,
stock INT NOT NULL,
version INT DEFAULT 1,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- 插入一些测试数据
INSERT INTO product (name, price, stock) VALUES
('iPhone 14', 6999.00, 100),
('MacBook Pro', 12999.00, 50),
('iPad Air', 4999.00, 200);
然后,创建一个Java数据库连接工具类:
package com.example.mvcc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DatabaseConnection {
// 数据库连接信息
private static final String URL = "jdbc:mysql://localhost:3306/mvcc_demo";
private static final String USER = "root";
private static final String PASSWORD = "password";
// 获取数据库连接
public static Connection getConnection() throws SQLException {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
return conn;
} catch (ClassNotFoundException e) {
throw new SQLException("MySQL JDBC Driver not found", e);
}
}
// 关闭连接
public static void closeConnection(Connection conn) {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
读一致性演示
下面的代码演示了MVCC如何在REPEATABLE READ隔离级别下保证读一致性:
package com.example.mvcc;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.concurrent.CountDownLatch;
/**
* 演示MySQL MVCC的读一致性特性
*/
public class MVCCReadConsistencyDemo {
public static void main(String[] args) throws Exception {
// 准备测试数据
resetTestData();
// 创建两个线程的同步点
final CountDownLatch readyLatch = new CountDownLatch(2);
final CountDownLatch startLatch = new CountDownLatch(1);
final CountDownLatch finishLatch = new CountDownLatch(2);
// 事务1:读取数据
Thread transaction1 = new Thread(() -> {
Connection conn = null;
try {
conn = DatabaseConnection.getConnection();
// 设置隔离级别为REPEATABLE_READ(MySQL默认)
conn.setTransactionIsolation(Connection.TRANSACTION_REPEATABLE_READ);
conn.setAutoCommit(false);
System.out.println("事务1: 开始,设置隔离级别为REPEATABLE_READ");
// 第一次读取
System.out.println("事务1: 第一次读取产品数据");
readProduct(conn, 1);
// 通知主线程已准备好
readyLatch.countDown();
// 等待主线程通知开始
startLatch.await();
// 等待事务2修改数据
Thread.sleep(1000);
// 第二次读取(在事务2修改后)
System.out.println("事务1: 第二次读取产品数据(事务2已修改但未提交)");
readProduct(conn, 1);
// 等待事务2提交
Thread.sleep(1000);
// 第三次读取(在事务2提交后)
System.out.println("事务1: 第三次读取产品数据(事务2已提交)");
readProduct(conn, 1);
// 提交事务1
conn.commit();
System.out.println("事务1: 已提交");
// 第四次读取(在事务1提交后,开启新事务)
conn.setAutoCommit(false);
System.out.println("事务1: 开启新事务,第四次读取产品数据");
readProduct(conn, 1);
conn.commit();
finishLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
try {
if (conn != null) conn.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
} finally {
DatabaseConnection.closeConnection(conn);
}
});
// 事务2:修改数据
Thread transaction2 = new Thread(() -> {
Connection conn = null;
try {
conn = DatabaseConnection.getConnection();
conn.setAutoCommit(false);
System.out.println("事务2: 开始");
// 通知主线程已准备好
readyLatch.countDown();
// 等待主线程通知开始
startLatch.await();
// 修改产品价格
System.out.println("事务2: 修改产品价格");
updateProductPrice(conn, 1, 7999.00);
// 等待一段时间再提交
Thread.sleep(2000);
// 提交事务2
conn.commit();
System.out.println("事务2: 已提交");
finishLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
try {
if (conn != null) conn.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
} finally {
DatabaseConnection.closeConnection(conn);
}
});
// 启动两个事务线程
transaction1.start();
transaction2.start();
// 等待两个线程都准备好
readyLatch.await();
// 通知两个线程开始执行
startLatch.countDown();
// 等待两个线程执行完成
finishLatch.await();
System.out.println("演示完成!");
}
// 读取产品信息
private static void readProduct(Connection conn, int productId) throws SQLException {
String sql = "SELECT id, name, price, stock, version FROM product WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, productId);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
System.out.printf(" 产品ID: %d, 名称: %s, 价格: %.2f, 库存: %d, 版本: %d%n",
rs.getInt("id"),
rs.getString("name"),
rs.getDouble("price"),
rs.getInt("stock"),
rs.getInt("version"));
}
}
}
}
// 更新产品价格
private static void updateProductPrice(Connection conn, int productId, double newPrice) throws SQLException {
String sql = "UPDATE product SET price = ?, version = version + 1 WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setDouble(1, newPrice);
pstmt.setInt(2, productId);
int rowsAffected = pstmt.executeUpdate();
System.out.println(" 更新了 " + rowsAffected + " 行数据");
}
}
// 重置测试数据
private static void resetTestData() throws SQLException {
Connection conn = null;
try {
conn = DatabaseConnection.getConnection();
conn.setAutoCommit(true);
// 重置产品数据
String sql = "UPDATE product SET price = 6999.00, stock = 100, version = 1 WHERE id = 1";
try (Statement stmt = conn.createStatement()) {
stmt.executeUpdate(sql);
}
System.out.println("测试数据已重置");
} finally {
DatabaseConnection.closeConnection(conn);
}
}
}
运行上述代码,你会看到以下输出(简化版):
测试数据已重置
事务1: 开始,设置隔离级别为REPEATABLE_READ
事务1: 第一次读取产品数据
产品ID: 1, 名称: iPhone 14, 价格: 6999.00, 库存: 100, 版本: 1
事务2: 开始
事务2: 修改产品价格
更新了 1 行数据
事务1: 第二次读取产品数据(事务2已修改但未提交)
产品ID: 1, 名称: iPhone 14, 价格: 6999.00, 库存: 100, 版本: 1
事务2: 已提交
事务1: 第三次读取产品数据(事务2已提交)
产品ID: 1, 名称: iPhone 14, 价格: 6999.00, 库存: 100, 版本: 1
事务1: 已提交
事务1: 开启新事务,第四次读取产品数据
产品ID: 1, 名称: iPhone 14, 价格: 7999.00, 库存: 100, 版本: 2
演示完成!
从输出结果可以看出:
- 🔍 在REPEATABLE READ隔离级别下,事务1在整个事务过程中看到的数据是一致的,即使事务2修改并提交了数据
- 🔄 只有当事务1提交并开启新事务后,才能看到事务2提交的修改
这正是MVCC的读一致性保证!通过维护数据的多个版本,使得事务能够在一个一致的快照上进行操作,不受其他并发事务的影响。
幻读问题演示
下面的代码演示了幻读问题以及MVCC如何在不同隔离级别下处理:
package com.example.mvcc;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.concurrent.CountDownLatch;
/**
* 演示幻读问题与MVCC解决方案
*/
public class MVCCPhantomReadDemo {
public static void main(String[] args) throws Exception {
// 测试REPEATABLE_READ隔离级别(MySQL默认,使用MVCC防止幻读)
testPhantomRead(Connection.TRANSACTION_REPEATABLE_READ, "REPEATABLE_READ");
Thread.sleep(1000);
System.out.println("\n--------------------------------------\n");
// 测试READ_COMMITTED隔离级别(可能出现幻读)
testPhantomRead(Connection.TRANSACTION_READ_COMMITTED, "READ_COMMITTED");
}
private static void testPhantomRead(int isolationLevel, String levelName) throws Exception {
System.out.println("测试隔离级别: " + levelName + " 下的幻读问题");
// 重置测试数据
resetTestData();
// 创建同步点
final CountDownLatch readyLatch = new CountDownLatch(2);
final CountDownLatch startLatch = new CountDownLatch(1);
final CountDownLatch midLatch = new CountDownLatch(1);
final CountDownLatch finishLatch = new CountDownLatch(2);
// 事务1:读取并更新数据
Thread transaction1 = new Thread(() -> {
Connection conn = null;
try {
conn = DatabaseConnection.getConnection();
// 设置指定的隔离级别
conn.setTransactionIsolation(isolationLevel);
conn.setAutoCommit(false);
System.out.println("事务1: 开始,设置隔离级别为" + levelName);
// 第一次查询价格大于5000的产品
System.out.println("事务1: 第一次查询价格 > 5000 的产品");
queryExpensiveProducts(conn);
// 通知主线程已准备好
readyLatch.countDown();
// 等待主线程通知开始
startLatch.await();
// 等待事务2插入新数据
midLatch.await();
// 第二次查询价格大于5000的产品(事务2已插入新数据)
System.out.println("事务1: 第二次查询价格 > 5000 的产品(事务2已插入新数据)");
queryExpensiveProducts(conn);
// 尝试更新所有价格大于5000的产品
System.out.println("事务1: 尝试更新所有价格 > 5000 的产品的价格上调10%");
updateExpensiveProducts(conn);
// 提交事务1
conn.commit();
System.out.println("事务1: 已提交");
finishLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
try {
if (conn != null) conn.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
} finally {
DatabaseConnection.closeConnection(conn);
}
});
// 事务2:插入新数据
Thread transaction2 = new Thread(() -> {
Connection conn = null;
try {
conn = DatabaseConnection.getConnection();
conn.setAutoCommit(false);
System.out.println("事务2: 开始");
// 通知主线程已准备好
readyLatch.countDown();
// 等待主线程通知开始
startLatch.await();
// 插入新的高价产品
System.out.println("事务2: 插入新的高价产品");
insertExpensiveProduct(conn, "Mac Studio", 19999.00, 30);
// 提交事务2
conn.commit();
System.out.println("事务2: 已提交");
// 通知事务1继续执行
midLatch.countDown();
finishLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
try {
if (conn != null) conn.rollback();
} catch (SQLException ex) {
ex.printStackTrace();
}
} finally {
DatabaseConnection.closeConnection(conn);
}
});
// 启动两个事务线程
transaction1.start();
transaction2.start();
// 等待两个线程都准备好
readyLatch.await();
// 通知两个线程开始执行
startLatch.countDown();
// 等待两个线程执行完成
finishLatch.await();
// 查看最终结果
checkFinalResults();
System.out.println(levelName + " 隔离级别下的幻读测试完成!");
}
// 查询价格大于5000的产品
private static void queryExpensiveProducts(Connection conn) throws SQLException {
String sql = "SELECT id, name, price, stock FROM product WHERE price > 5000 ORDER BY id";
try (Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql)) {
System.out.println(" 价格 > 5000 的产品:");
int count = 0;
while (rs.next()) {
count++;
System.out.printf(" ID: %d, 名称: %s, 价格: %.2f, 库存: %d%n",
rs.getInt("id"),
rs.getString("name"),
rs.getDouble("price"),
rs.getInt("stock"));
}
System.out.println(" 共找到 " + count + " 条记录");
}
}
// 更新所有价格大于5000的产品
private static void updateExpensiveProducts(Connection conn) throws SQLException {
String sql = "UPDATE product SET price = price * 1.1 WHERE price > 5000";
try (Statement stmt = conn.createStatement()) {
int rowsAffected = stmt.executeUpdate(sql);
System.out.println(" 更新了 " + rowsAffected + " 条记录");
}
}
// 插入新的高价产品
private static void insertExpensiveProduct(Connection conn, String name, double price, int stock) throws SQLException {
String sql = "INSERT INTO product (name, price, stock) VALUES (?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, name);
pstmt.setDouble(2, price);
pstmt.setInt(3, stock);
int rowsAffected = pstmt.executeUpdate();
System.out.println(" 插入了 " + rowsAffected + " 条记录");
}
}
// 重置测试数据
private static void resetTestData() throws SQLException {
// 重置代码省略...
}
// 检查最终结果
private static void checkFinalResults() throws SQLException {
// 检查代码省略...
}
}
运行结果会显示:
- 在REPEATABLE READ隔离级别下,事务1的两次查询结果一致,且更新操作只影响了事务1看到的记录
- 在READ COMMITTED隔离级别下,事务1的第二次查询会看到事务2插入的新记录,导致幻读问题
MVCC原理图示
MVCC的优缺点分析 ⚖️
优点
- 🚀 提高并发性能:读操作不加锁,写操作只锁定必要的行,大幅提升系统吞吐量
- 🛡️ 避免脏读和不可重复读:通过版本链和ReadView机制,确保事务只能看到符合隔离级别要求的数据版本
- 🔄 支持事务回滚:undo日志不仅用于MVCC,还用于事务回滚,提供了完整的事务支持
- 📊 适合读多写少的场景:对于读操作占主导的应用(如报表系统),MVCC能显著提升性能
缺点
- 💾 存储开销增加:需要存储数据的多个版本,增加了存储空间需求
- 🧠 实现复杂:相比传统锁机制,MVCC的实现更为复杂,维护成本更高
- 🐢 写入性能可能受影响:在写入密集型场景,维护版本链可能导致性能下降
- 🔍 可见性判断开销:每次读取数据都需要进行可见性判断,增加了CPU开销
实际应用场景与最佳实践 🌐
高并发读写场景
在电商、社交媒体等高并发应用中,MVCC能够有效处理大量并发读写操作:
- 📱 商品详情页:大量用户同时浏览商品,少量用户进行购买操作
- 📊 社交媒体信息流:用户浏览信息流的同时,系统需要更新点赞、评论等数据
报表查询场景
在需要生成复杂报表的系统中,MVCC能够确保报表数据的一致性:
- 📈 财务报表:在生成报表的同时,不影响正常的业务操作
- 📊 数据分析:长时间运行的分析查询可以在一个一致的数据快照上进行
开发注意事项
在使用MySQL MVCC时,需要注意以下几点:
- ⚠️ 选择合适的隔离级别:根据业务需求选择合适的事务隔离级别,避免过度隔离导致性能下降
- 🔄 控制事务大小和持续时间:长时间运行的事务会导致undo日志膨胀,影响性能
- 🔍 了解当前读和快照读的区别:在需要读取最新数据时,使用当前读操作
- 🛠️ 合理使用乐观锁:在高并发更新场景,结合MVCC和乐观锁(如版本号)提高并发性能
// 使用乐观锁更新示例
String updateSql = "UPDATE product SET stock = stock - ?, version = version + 1 " +
"WHERE id = ? AND version = ?";
try (PreparedStatement pstmt = conn.prepareStatement(updateSql)) {
pstmt.setInt(1, quantity);
pstmt.setInt(2, productId);
pstmt.setInt(3, currentVersion);
int rowsAffected = pstmt.executeUpdate();
success = (rowsAffected > 0);
}
总结与展望 🔮
MySQL的MVCC机制是一个精妙的设计,通过维护数据的多个版本,实现了高并发下的数据一致性和隔离性。它使得数据库能够在不牺牲一致性的前提下,提供极高的并发性能。
随着分布式数据库和NewSQL的发展,MVCC的思想也被广泛应用于新一代数据库系统中。了解MVCC的工作原理,不仅有助于我们更好地使用MySQL,也能帮助我们理解现代数据库系统的设计思想。
在未来,随着硬件性能的提升和新型存储技术的发展,MVCC可能会有更高效的实现方式。但其核心思想——通过版本控制实现并发——将继续在数据库领域发挥重要作用。
希望本文能帮助你深入理解MySQL MVCC的工作原理,并在实际开发中更好地利用这一强大特性!🚀

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









