









文章目录
树
基本术语

树的性质
-
非空树的节点总数等于书中所有节点的度之和加 1
-
度为k的非空树的第 i i i 层最多有 k i − 1 k^i-1 ki−1 个节点
-
深度为h的k叉树最多有 k h − 1 k − 1 \frac {k^h-1}{ k-1} k−1kh−1
-
具有n个节点的k叉树的最小深度为 ⌈ l o g k ( n ( k − 1 ) + 1 ) ⌉ \lceil log_k(n(k-1)+1) \rceil ⌈logk(n(k−1)+1)⌉
二叉树
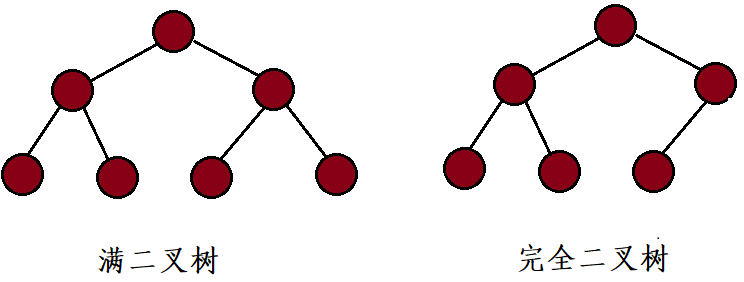
1.满二叉树
若一棵二叉树中的任意一个结点,或者是叶结点,或者具有两棵非空子树,并且叶结点都集中在二叉树的最下面一层,这样的二叉树为满二叉树。即一颗深度为h且有 2 h − 1 2^h-1 2h−1 个结点的二叉树。
2.完全二叉树
若一棵二叉树中只有最下面两层结点的度可以小于2,并且最下面一层的结点(叶结点)都依次排列在该层最左边的位置上.这样的二叉树为完全二叉树。
二叉树的性质
-
具有n个结点的非空二叉树共有n-1个分支。
-
非空二叉树的第 i i i 层最多有 2 i – 1 2^{i–1} 2i–1 个结点( i ≥ 1 i\geq1 i≥1)。
-
深度为h 的非空二叉树最多有 2 h – 1 2^h –1 2h–1个结点。
-
若非空二叉树有 n 0 n_0 n0 个叶结点,有 n 2 n_2 n2 个度为 2 的结点,则 n 0 = n 2 + 1 n_0=n_2+1 n0=n2+1
-
具有n个结点的非空完全二叉树的深度为 h = ⌊ l o g 2 n ⌋ + 1 h= \lfloor log_2n \rfloor+1 h=⌊log2n⌋+1
-
若对具有n个结点的完全二叉树按照层次从上到下,每层从左到右的顺序进行编号, 则编号为i的结点具有以下性质:
(1)当 i = 1 i=1 i=1,则编号为 i i i 的结点为二叉树的根结点;
若 i > 1 i>1 i>1 ,则编号为 i i i 的结点的双亲的编号为 ⌊ i / 2 ⌋ \lfloor i/2 \rfloor ⌊i/2⌋;
(2) 若 2 i > n 2i>n 2i>n ,则编号为 i i i 的结点无左子树;
若 2 i ≤ n 2i \leq n 2i≤n ,则编号为 i i i 的结点的左孩子的编号为 2 i 2i 2i ;
(3) 若 2 i + 1 > n 2i+1>n 2i+1>n ,则编号为 i i i 的结点无右子树;
若 2 i + 1 ≤ n 2i+1\leq n 2i+1≤n ,则编号为 i i i 的结点的右孩子的编号为 2 i + 1 2i+1 2i+1 。 -
若对具有n个结点的完全二叉树按照层次从上到下,每层从左到右的顺序进行编号, 则编号为i的结点具有以下性质:
(1) 当 i = 0 i=0 i=0,则编号为i的结点为二叉树的根结点;
若 i > 0 i>0 i>0,则编号为i 的结点的双亲的编号为 ⌊ ( i − 1 ) / 2 ⌋ \lfloor (i-1)/2 \rfloor ⌊(i−1)/2⌋;
(2) 若 2 i + 1 ≥ n 2i+1≥n 2i+1≥n,则编号为i 的结点无左子树;
若 2 i + 1 < n 2i+1<n 2i+1<n,则编号为i 的结点的左孩子的编号为 2 i + 1 2i+1 2i+1;
(3) 若 2 i + 2 ≥ n 2i+2≥n 2i+2≥n,则编号为i 的结点无右子树;
若 2 i + 2 < n 2i+2<n 2i+2<n,则编号为i 的结点的右孩子的编号为2i+2。
二叉链表定义
struct node {
Datatype data;
struct node *left, *right;
};
typedef struct node BTNode;
typedef struct node *BTNodeptr;
T = (BTNodeptr)malloc(sizeof(BTNode));
二叉树的遍历
L表示遍历左子树;R表示遍历右子树;D表示访问根结点;
1. 前序遍历 DLR
原则:若被遍历的二叉树非空, 则
- 访问根结点;
- 以前序遍历原则遍历根结点的左子树;
- 以前序遍历原则遍历根结点的右子树。
「代码」
void perorder(BTNodeptr t)
{
if(t!=NULL){
printf(t); /* 访问t指向结点 */
preorder(t->left);
preorder(t->right);
}
}
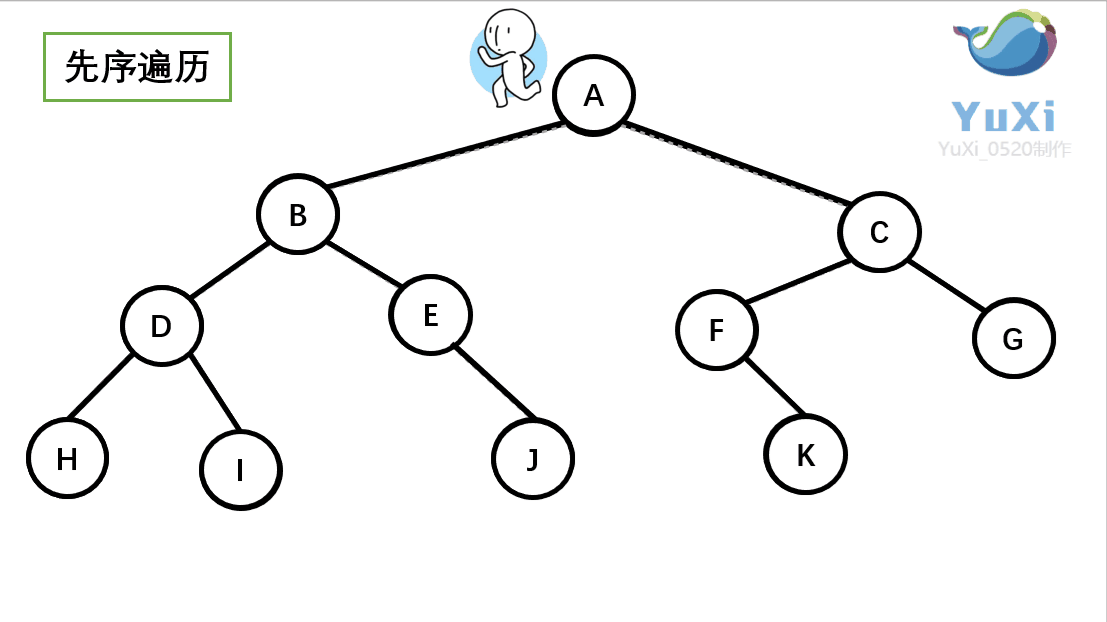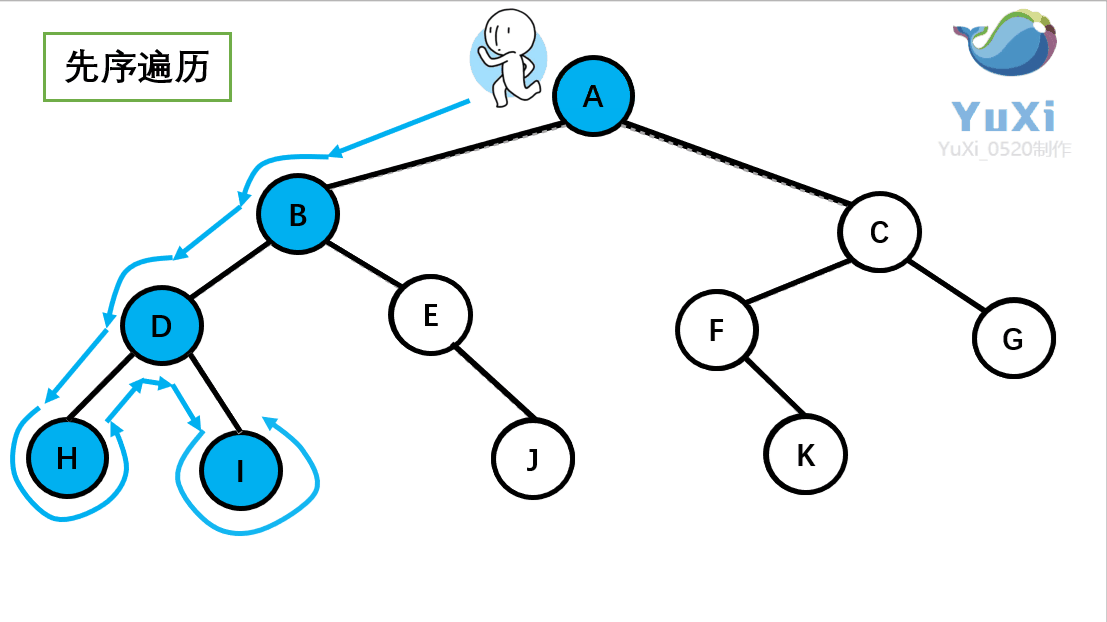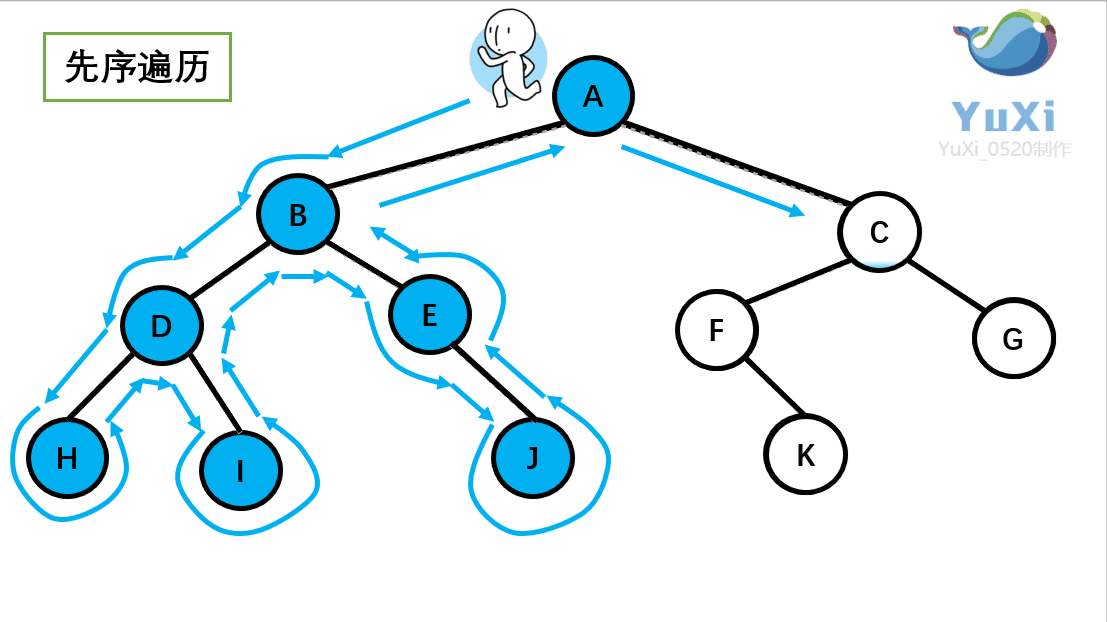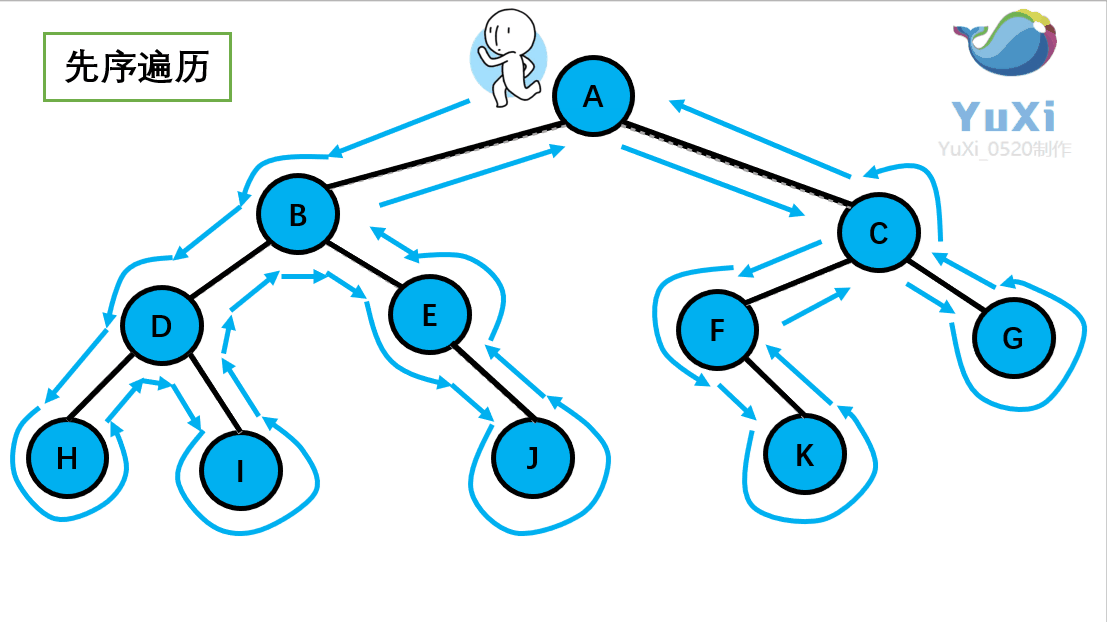
先序遍历可以想象为,一个小人从一棵二叉树根节点为起点,沿着二叉树外沿,逆时针走一圈回到根节点,路上遇到的元素顺序,就是先序遍历的结果。
记住小人沿着外围跑一圈(直到跑回根节点)
2. 中序遍历 LDR
原则:若被遍历的二叉树非空, 则
- 以中序遍历原则遍历根结点的左子树;
- 访问根结点;
- 以中序遍历原则遍历根结点的右子树。
「代码」
void inorder(BTNodeptr t)
{
if(t!=NULL){
inorder(t->left);
ptintf(t); /* 访问T指向结点 */
inorder(t->right);
}
}
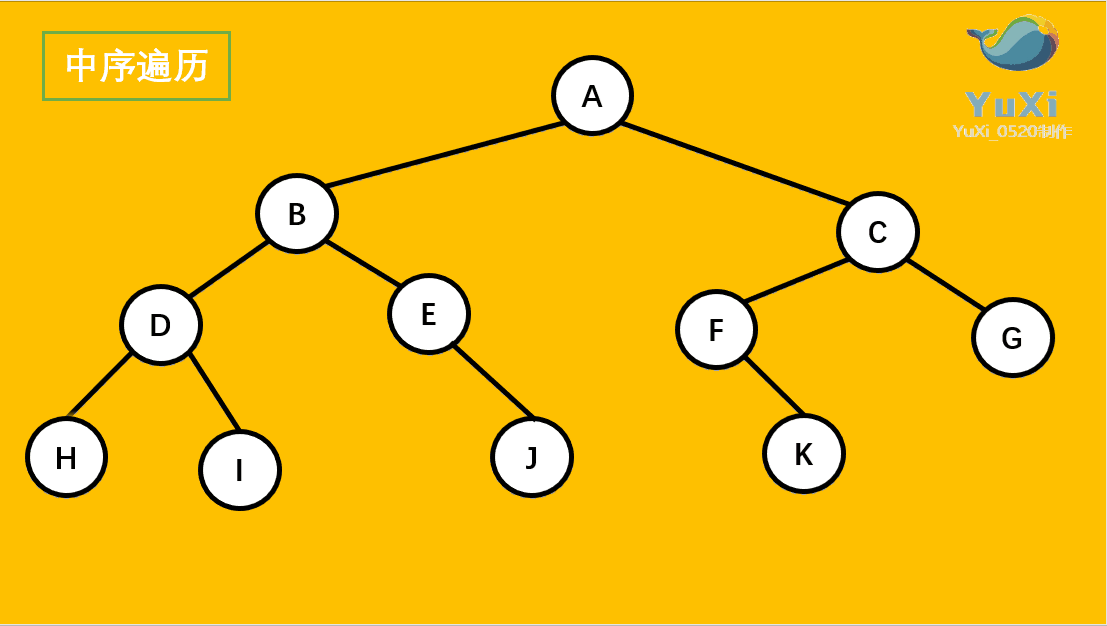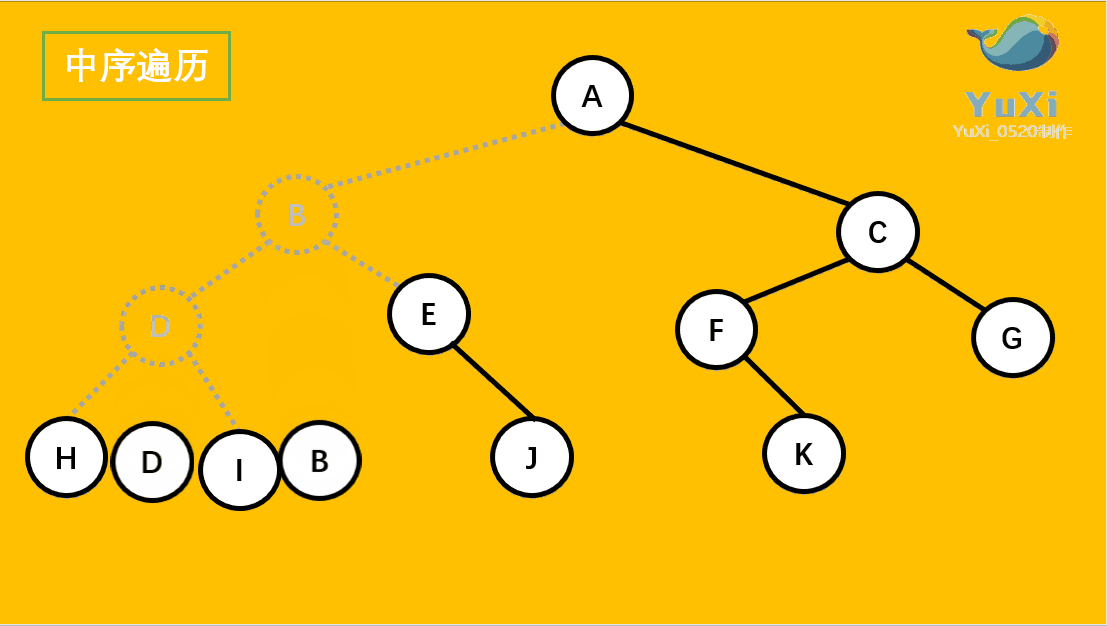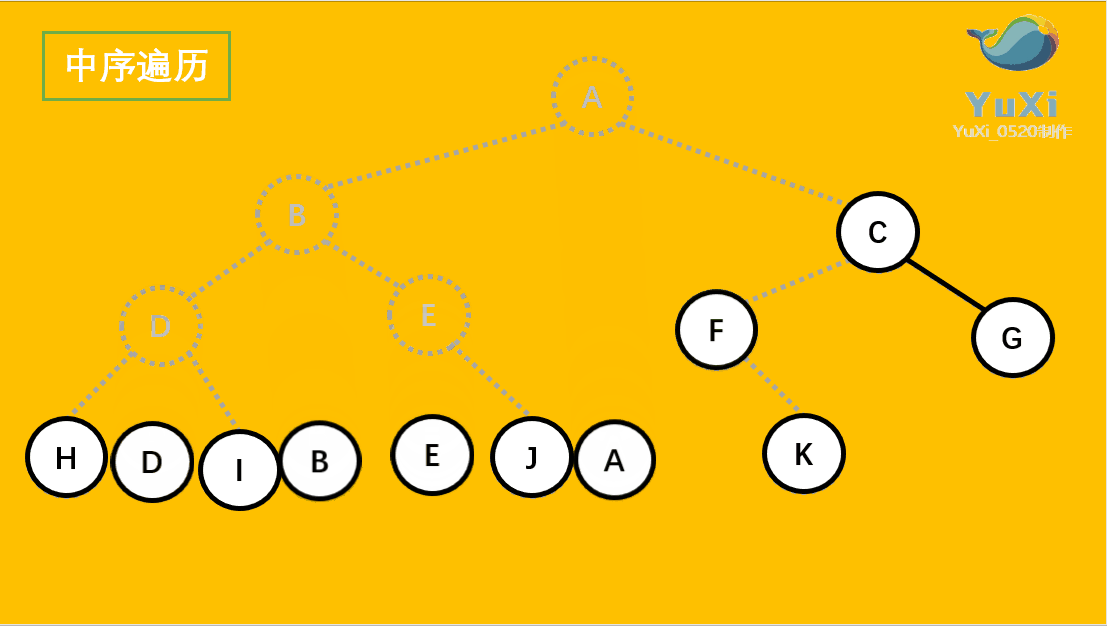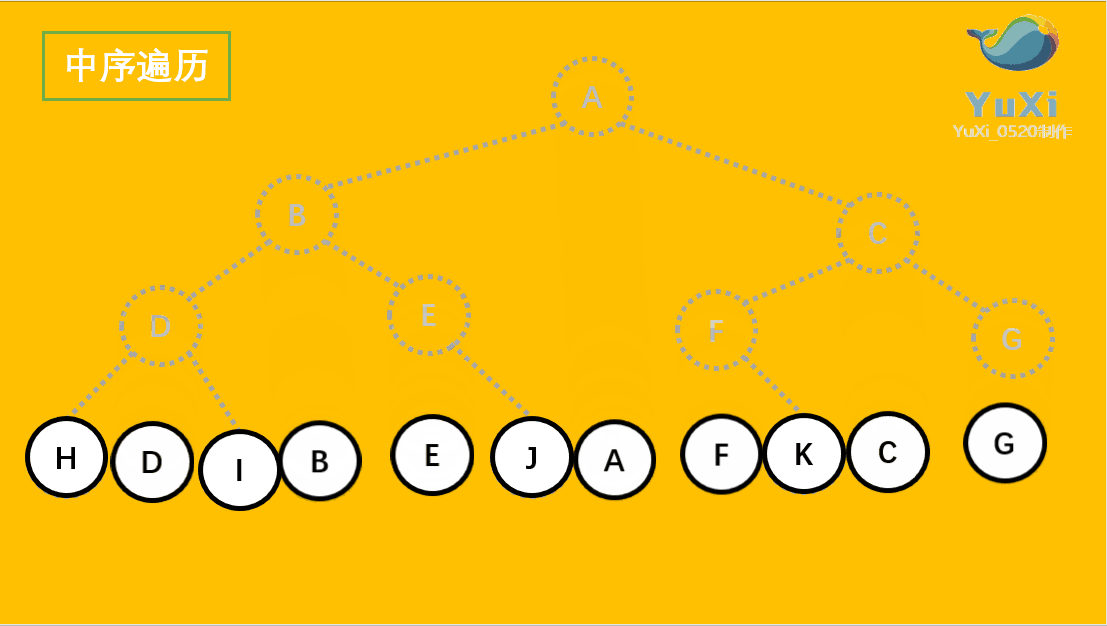
中序遍历可以看成,二叉树每个节点,垂直方向投影下来(可以理解为每个节点从最左边开始垂直掉到地上),然后从左往右数,得出的结果便是中序遍历的结果
从最左边开始,把每个节点垂直投影到同一直线上,从左往右读值
3. 后序遍历 LRD
原则:若被遍历的二叉树非空, 则
- 以后序遍历原则遍历根结点的左子树;
- 以后序遍历原则遍历根结点的右子树;
- 访问根结点。
「代码」
void postorder(BTNodeptr t)
{
if(t!=NULL){
postorder(t->left);
postorder(t->right);
printf(t); /* 访问T指向结点 */
}
}
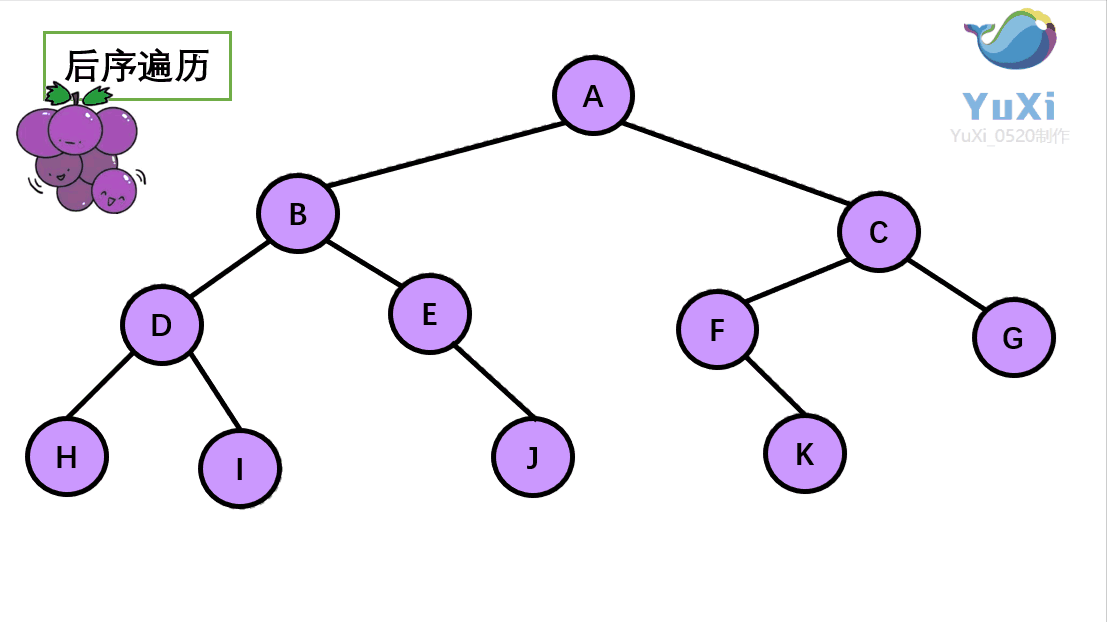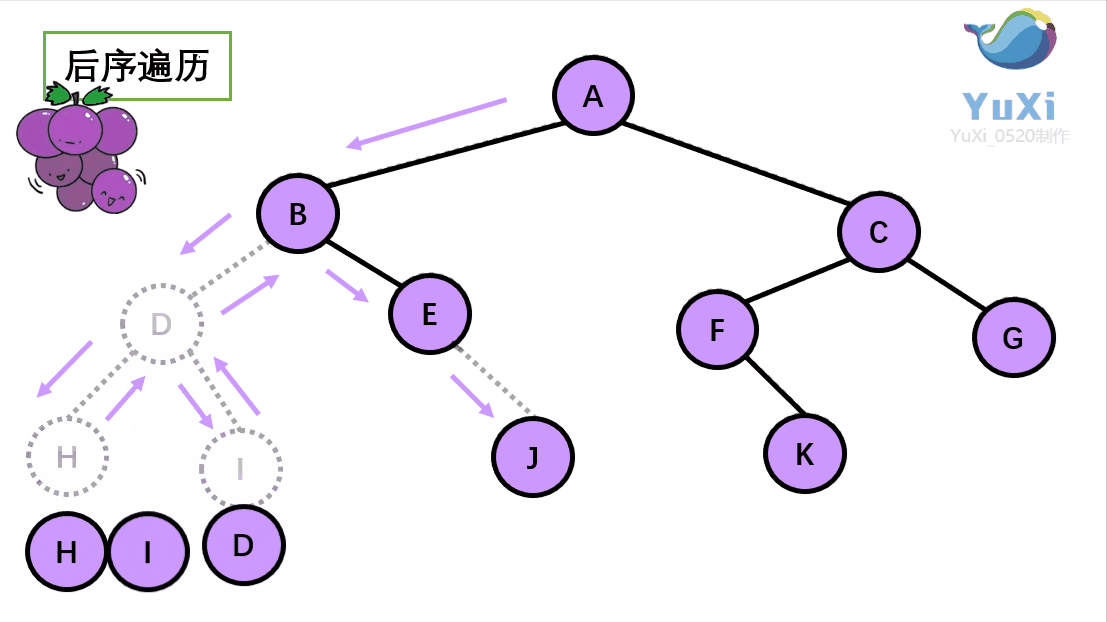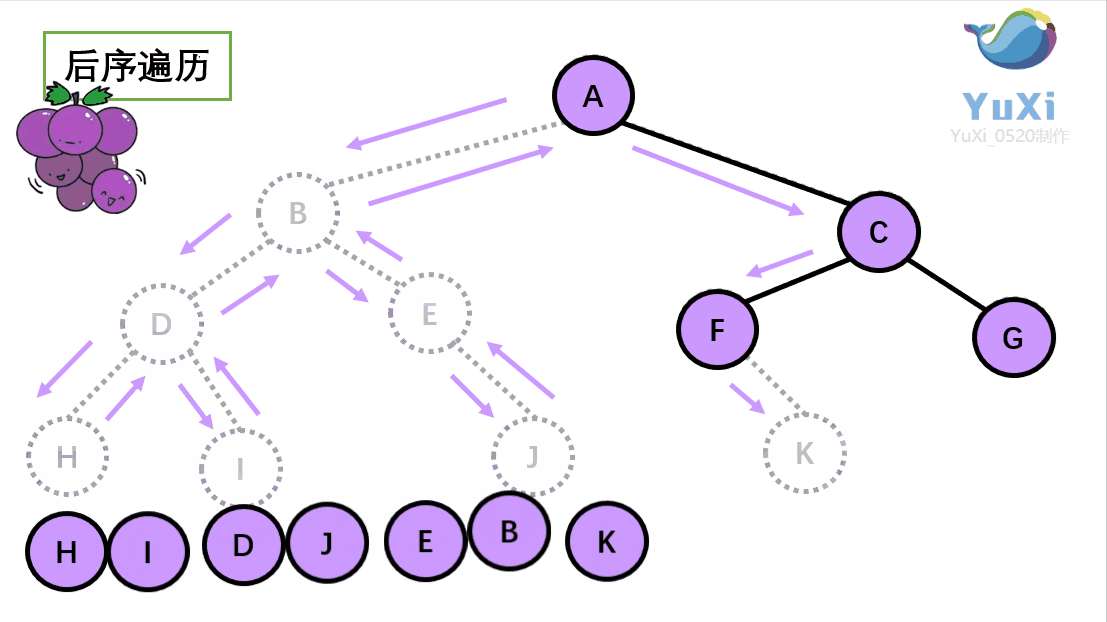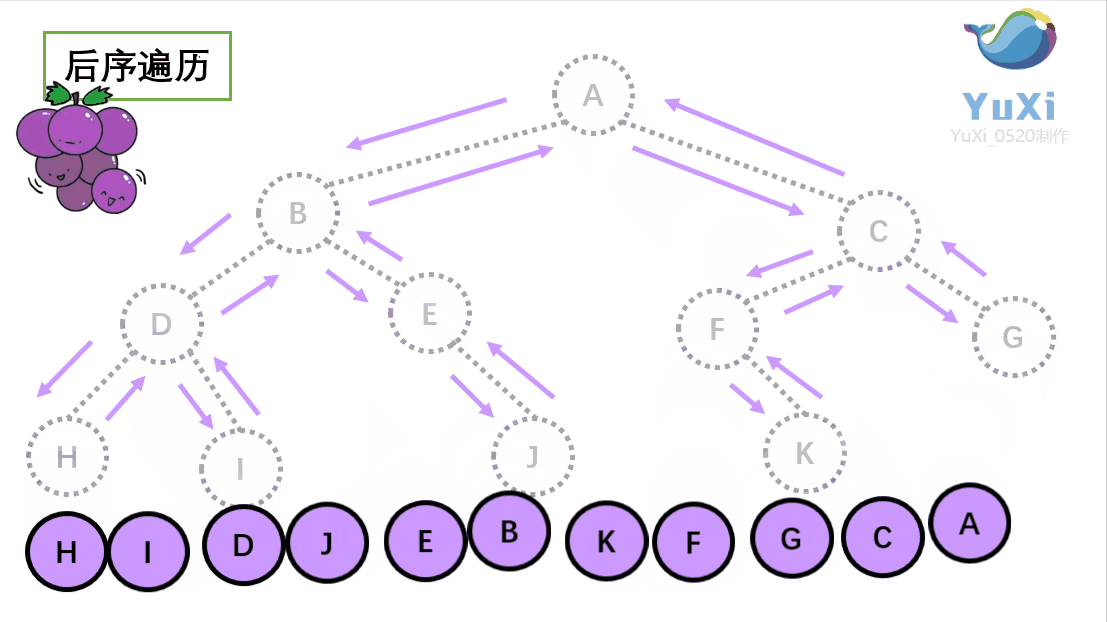
后序遍历就像是剪葡萄,我们要把一串葡萄剪成一颗一颗的。围着树的外围绕一圈,如果发现一剪刀就能剪下的葡萄(必须是一颗葡萄)(也就是葡萄要一个一个掉下来,不能一口气掉超过1个这样),就把它剪下来,组成的就是后序遍历了。
4. 层次遍历
由遍历序列恢复二叉树
1) 已知先序和中序求原二叉树并写出后序
先序:ABCDEFGH
中序:BDCEAFHG
解题步骤:(中序确定左右子树、先序确定根节点)
①首先确定根节点 先序中最先出现的是根节点 所以确定A是根节点
②根据中序确定根节点A的左右子树 BDCE是A的左子树 FHG是A的右子树
③然后与A相连的左子树的根节点是什么呢?刚才说到越靠前的越是根节点,所以A的左子树的根节点是在先序中最先出现的B,然后再根据中序可以知道DCE是B的右子树,那么该右子树的根结点有是什么,再次回到先序中确定C是一个根节点。以此类推、、、、、
2) 已知中序和后序求原二叉树并写出前序
中序:BDCEAFHG
后序:DECBHGFA
解题步骤:(中序确定左右子树、后序确定根节点)
①首先确定根节点 后序中最晚出现的是根节点 所以确定A是根节点
②根据中序确定根节点A的左右子树 BDCE是A的左子树 FHG是A的右子树
③然后与A相连的左子树的根节点是什么呢?刚才说到越靠后的越是根节点,所以A的左子树的根节点是在后序中最晚出现的B,然后再根据中序可以知道DCE是B的右子树,那么该右子树的根结点有是什么,再次回到后序中确定C是一个根节点。以此类推、、、、、
————————————————
原文链接:https://blog.csdn.net/qq_41099859/article/details/91358221
前缀、中缀、后缀表达式
文章链接:https://blog.csdn.net/fireflylane/article/details/83017889
第五次作业
5.1 树叶节点遍历(树-基础题)
【问题描述】
从标准输入中输入一组整数,在输入过程中按照左子结点值小于根结点值、右子结点值大于等于根结点值的方式构造一棵二叉查找树,然后从左至右输出所有树中叶结点的值及高度(根结点的高度为1)。例如,若按照以下顺序输入一组整数:50、38、30、64、58、40、10、73、70、50、60、100、35,则生成下面的二叉查找树:
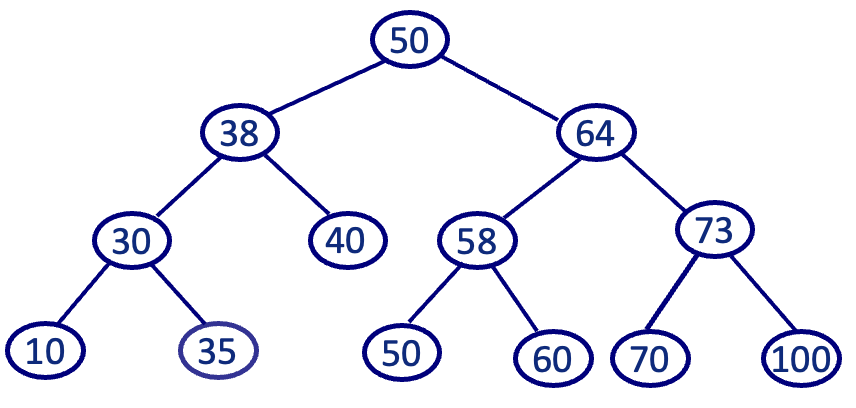
从左到右的叶子结点包括:10、35、40、50、60、70、100,叶结点40的高度为3,其它叶结点的高度都为4。
【输入形式】
先从标准输入读取整数的个数,然后从下一行开始输入各个整数,整数之间以一个空格分隔。
【输出形式】
按照从左到右的顺序分行输出叶结点的值及高度,值和高度之间以一个空格分隔。
【样例输入】
13
50 38 30 64 58 40 10 73 70 50 60 100 35
【样例输出】
10 4
35 4
40 3
50 4
60 4
70 4
100 4
【样例说明】
按照从左到右的顺序输出叶结点(即没有子树的结点)的值和高度,每行输出一个。
「代码」
#include <stdlib.h>
#include <stdio.h>
typedef int datatype;
struct node {
datatype data;
struct node *lchild, *rchild;
};
typedef struct node BTNode, *BTNodeptr;
BTNodeptr insertBST(BTNodeptr T, datatype item);
void preBitree(BTNodeptr T);
int i=1;//深度
int main()
{
int n, item;
BTNodeptr root=NULL;
scanf("%d",&n);
for(int i=0; i<n; i++){ //构造一个有n个元素的BST树
scanf("%d", &item);
insertBST(root, item);
}
preBitree(root);
return 0;
}
BTNodeptr insertBST(BTNodeptr T, datatype item)
{
if(T == NULL){
T = (BTNodeptr)malloc(sizeof(BTNode));
T->data = item;
T->lchild = T->rchild = NULL;
}
else if( item < T->data)
T->lchild = insertBST(T->lchild, item);
else if( item >= T->data)
T->rchild = insertBST(T->rchild,item);
// else
// do-something; //树中存在该元素
return T;
}
BTNodeptr insertBST(BTNodeptr T, datatype item)//二叉排序树的建立
{
if(T == NULL){
T = (BTNodeptr)malloc(sizeof(BTNode));
T->data = item;
T->lchild = T->rchild = NULL;
}
else if( item < T->data)
insertBST(T->lchild, item);
else if( item >= T->data)
insertBST(T->rchild, item);
// else
// do-something; //树中存在该元素
}
void preBitree(BTNodeptr T)//前序遍历
{
if(T == NULL)
{
return;//return不带参数返回时直接返回上一层函数
}
else;
{
if(T->lchild == NULL&&T->rchild == NULL)
printf("%d %d\n", T->data,i);//打印树中的节点数据
i++;
preBitree(T->lchild);//递归遍历左子树
preBitree(T->rchild);//递归遍历右子树
i--;
}
}
5.2 词频统计(树实现)
【问题描述】
编写程序统计一个英文文本文件中每个单词的出现次数(词频统计),并将统计结果按单词字典序输出到屏幕上。
要求:程序应用二叉排序树(BST)来存储和统计读入的单词。
注:在此单词为仅由字母组成的字符序列。包含大写字母的单词应将大写字母转换为小写字母后统计。在生成二叉排序树不做平衡处理。
【输入形式】
打开当前目录下文件article.txt,从中读取英文单词进行词频统计。
【输出形式】
程序应首先输出二叉排序树中根节点、根节点的右节点及根节点的右节点的右节点上的单词(即root、root->right、root->right->right节点上的单词),单词中间有一个空格分隔,最后一个单词后没有空格,直接为回车(若单词个数不足三个,则按实际数目输出)。
程序将单词统计结果按单词字典序输出到屏幕上,每行输出一个单词及其出现次数,单词和其出现次数间由一个空格分隔,出现次数后无空格,直接为回车。
【样例输入】
当前目录下文件article.txt内容如下:
“Do not take to heart every thing you hear.”
“Do not spend all that you have.”
“Do not sleep as long as you want;”
【样例输出】
do not take
all 1
as 2
do 3
every 1
have 1
hear 1
heart 1
long 1
not 3
sleep 1
spend 1
take 1
that 1
thing 1
to 1
want 1
you 3
【样例说明】
程序首先在屏幕上输出程序中二叉排序树上根节点、根节点的右子节点及根节点的右子节点的右子节点上的单词,分别为do not take,然后按单词字典序依次输出单词及其出现次数。
「代码」
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
#define MAXWORD 10000
struct tnode {
char word[MAXWORD];
int count;
struct tnode *left,*right;
} BTNode, *BTNodeptr;//BST,单词树结构
int getword(FILE *bfp,char *w);
struct tnode *addtree(struct tnode *p,char *w);//标准函数,参考ppt或书
void treeprint( struct tnode *p);
int main()
{
char word[MAXWORD];
FILE *bfp;
struct tnode *root=NULL; //BST树根节点指针
char filename[32]="article.txt";
if((bfp = fopen(filename, "r")) == NULL){ //打开一个文件
fprintf(stderr, "%s can’t open!\n",filename);
return -1;
}
while( getword(bfp,word) != EOF) //从文件中读入一个单词
root = addtree(root, word);
/*输出二叉排序树中根节点、根节点的右节点及根节点的右节点的右节点上的单词*/
printf("%s %s" ,root->word,root->right->word);
if(root->right->right!=NULL)
printf(" %s" ,root->right->right->word);
printf("\n");
treeprint(root); //遍历输出单词树
return 0;
}
struct tnode *addtree(struct tnode *p, char *w) /*install w at or below p*/
{
int cond;
if( p == NULL )
{/* a new word has arived */
p=(struct tnode*)malloc(sizeof(struct tnode));/* make a new node */
strcpy(p->word,w);
p->count= 1;
p->left= p->right= NULL;
}
else if ((cond = strcmp(w,p->word)) == 0)
p->count ++; /* repeated word */
else if ( cond < 0) /*lower into left subtree*/
p->left =addtree(p->left, w);
else /* greater into right subtree */
p->right = addtree(p->right, w);
return (p);
}
void treeprint(struct tnode *p)/* print re p tecursirely*/
{
if(p != NULL)
{
treeprint(p->left);
printf("%s %d\n" ,p->word,p->count);
treeprint(p->right);
}
}
int getword(FILE *bfp,char word[])//之前的词频统计程序里实现过该函数
{
int i=0;
char temp;
while((temp=fgetc(bfp))!=EOF){
if(isalpha(temp)){
word[i]=tolower(temp);
i++;
}
else if(i>0){//说明i中已经至少有一个字符
word[i]='\0';
return 0;
}
}
return EOF;
}
5.3 计算器(表达式计算-表达式树实现)
【问题描述】
从标准输入中读入一个整数算术运算表达式,如24 / ( 1 + 2 + 36 / 6 / 2 - 2) * ( 12 / 2 / 2 )= ,计算表达式结果,并输出。
要求:
- 表达式运算符只有+、-、*、/,表达式末尾的=字符表示表达式输入结束,表达式中可能会出现空格;
- 表达式中会出现圆括号,括号可能嵌套,不会出现错误的表达式;
- 出现除号/时,以整数相除进行运算,结果仍为整数,例如:5/3结果应为1。
- 要求采用表达式树来实现表达式计算。
表达式树(expression tree):
我们已经知道了在计算机中用后缀表达式和栈来计算中缀表达式的值。在计算机中还有一种方式是利用表达式树来计算表达式的值。表达式树是这样一种树,其根节点为操作符,非根节点为操作数,对其进行后序遍历将计算表达式的值。由后缀表达式生成表达式树的方法如下:
-
读入一个符号:
-
如果是操作数,则建立一个单节点树并将指向他的指针推入栈中;
-
如果是运算符,就从栈中弹出指向两棵树T1和T2的指针(T1先弹出)并形成一棵新树,树根为该运算符,它的左、右子树分别指向T2和T1,然后将新树的指针压入栈中。
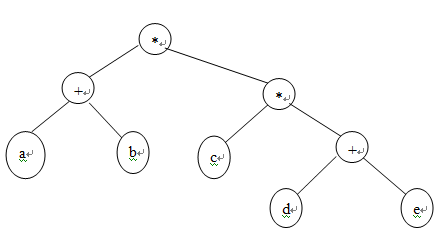
例如输入的后缀表达为:
ab+cde+**
则生成的表达式树为:
【输入形式】
从键盘输入一个以=结尾的整数算术运算表达式。操作符和操作数之间可以有空格分隔。
【输出形式】
首先在屏幕上输出表达式树根、左子节点及右子节点上的运算符或操作数,中间由一个空格分隔,最后有一个回车(如果无某节点,则该项不输出)。然后输出表达式计算结果。
【样例输入】
24 / ( 1 + 2 + 36 / 6 / 2 - 2) * ( 12 / 2 / 2 ) =
【样例输出】
* / /
18
【样例说明】
按照运算符及括号优先级依次计算表达式的值。在生成的表达树中,*是根节点的运算符,/ 是根节点的左子节点上运算符,/是根节点的右子节点上运算符,按题目要求要输出。
思路
如果上一个表达式计算题按照ppt的方法取巧做了,那么意味着这道题就比较复杂了。不过别着急,弄懂了并不难,一步步来即可。按照三步走:
- 中缀转后缀表达式
中缀–>后缀:
1.从左到右进行遍历
2.运算数,直接输出.
3.左括号,直接压入堆栈
4.右括号,(意味着括号已结束)不断弹出栈顶运算符并输出直到遇到左括号(弹出但不输出)
5.运算符,将该运算符与栈顶运算符进行比较,
如果优先级高于栈顶运算符则压入堆栈(该部分运算还不能进行),
如果优先级低于等于栈顶运算符则将栈顶运算符弹出并输出,然后比较新的栈顶运算符.
(低于弹出意味着前面部分可以运算,先输出的一定是高优先级运算符,等于弹出是因为同等优先级,从左到右运算)
直到优先级大于栈顶运算符或者栈空,再将该运算符入栈.
6.如果对象处理完毕,则按顺序弹出并输出栈中所有运算符.
————————————————
原文链接:https://blog.csdn.net/wujing1_1/article/details/107774753 - 构建表达式树
后缀表达式–>表达式树:
我们一次一个符号地读入表达式。
如果符号是操作数,那么就建立一个单结点树并将它推入栈中。
如果符号是操作符,那么就从栈中弹出两棵树T1和T2(T1先弹出)并形成一棵新的树,该树的根就是操作符,它的左、右儿子分别是T2和T1。然后将指向这颗树的指针压入栈中。 - 计算后缀表达式
以上三点的具体实现方法及参考文章已在代码相应的函数部分注释出
「代码」
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<ctype.h>
#define MAXSIZE 100
typedef int dataType;
enum symbol {OTHER, NUM, OP, EQ};//符号类型
enum oper {EPT, LEFT, RIGHT, ADD, MIN, MUL, DIV}; //运算类型及优先级
int Pri[ ]={ -1, 0, 0, 1, 1, 2, 2 }; //运算符优先级
union sym {
dataType num;
enum oper op;
} ; //符号值
enum symbol getSym( union sym *item);
enum oper Op_stack[MAXSIZE];//运算符栈
int Otop=-1; //运算符栈顶指示器,初始为空栈
void operate(enum oper op );//操作运算符栈
void pushOp(enum oper op);
enum oper popOp(void);
enum oper topOp(void);
struct Postfix {
enum symbol type;//由于char与int类型混杂,type来指示当前位置的数据类型
dataType num;
enum oper op; //数字num 或 运算符op
} ;
struct Postfix Postfixs[MAXSIZE];//后缀表达式
int i=0;
void print_Postfixs(void);//测试,输出后缀表达式
struct node //表达式树
{
/* 数字和运算符 */
enum symbol type;
dataType num;
enum oper op; //数字num 或 运算符op
struct node *lchild;
struct node *rchild;
};
typedef struct node BTNode, *BTNodeptr;
BTNode *Tree_Stack[MAXSIZE];//树栈
int Ttop=-1; //栈顶指示器,初始为空栈
void push_stack(BTNode *data);
BTNode *pop_stack(void);
void Postorder (BTNodeptr t);//测试,后序遍历树,与后缀表达式一致即正确
BTNode *create_express_tree(void);//建立表达式树
dataType Num_stack[MAXSIZE]; //数据栈
int Ntop=-1; //数据栈顶指示器,初始为空栈
void pushNum(dataType num);
dataType popNum(void);
void error(char s[ ]);
void compute();//计算后缀表达式
void print_op_num(BTNode *p);
int main()
{
union sym temp;
enum symbol s;
while( (s = getSym(&temp)) != EQ) {
if(s == NUM)
{
Postfixs[i].type = NUM;
Postfixs[i].num = temp.num;
i++;
}
else if(s == OP)
operate(temp.op);
else {
printf("Error in the expression!(1)\n");
return 1;
}
}
while(Otop >=0) {//将栈中所有运算符弹出
Postfixs[i].type = OP;
Postfixs[i].op = popOp();
i++;
}
//中缀-->后缀,Done!
//测试,输出后缀表达式
// print_Postfixs();
BTNodeptr root=NULL;
root=create_express_tree();
//测试,后序遍历树
// Postorder(root);
// printf("\n");
if(root!=NULL)
print_op_num(root);
if(root->lchild!=NULL)
print_op_num(root->lchild);
if(root->rchild!=NULL)
print_op_num(root->rchild);
printf("\n");
compute();
printf("%d\n",Num_stack[0]);
return 0;
}
enum symbol getSym( union sym *item)
{
int c, n;
while((c = getchar()) != '=') {
if(c >= '0' && c <= '9'){
for(n=0; c >= '0' && c <= '9'; c= getchar())
n = n*10 + c-'0';
ungetc(c, stdin);
item->num = n;
return NUM;
}
else
switch(c) {
case '+': item->op = ADD; return OP;
case '-': item->op = MIN; return OP;
case '*': item->op = MUL; return OP;
case '/': item->op = DIV; return OP;
case '(': item->op = LEFT; return OP;
case ')': item->op = RIGHT; return OP;
case ' ': case '\t': case '\n': break;
default: return OTHER;
}
}
return EQ;
}
void operate(enum oper op )
{
/*
中缀-->后缀:
1.从左到右进行遍历
2.运算数,直接输出.
3.左括号,直接压入堆栈
4.右括号,(意味着括号已结束)不断弹出栈顶运算符并输出直到遇到左括号(弹出但不输出)
5.运算符,将该运算符与栈顶运算符进行比较,
如果优先级高于栈顶运算符则压入堆栈(该部分运算还不能进行),
如果优先级低于等于栈顶运算符则将栈顶运算符弹出并输出,然后比较新的栈顶运算符.
(低于弹出意味着前面部分可以运算,先输出的一定是高优先级运算符,等于弹出是因为同等优先级,从左到右运算)
直到优先级大于栈顶运算符或者栈空,再将该运算符入栈.
6.如果对象处理完毕,则按顺序弹出并输出栈中所有运算符.
————————————————
原文链接:https://blog.csdn.net/wujing1_1/article/details/107774753
*/
if (op == RIGHT) { //运算符为右括号时,开始弹栈,直到弹出左括号
enum oper c;
while ( (c=popOp()) != LEFT){
Postfixs[i].type = OP;
Postfixs[i].op = c;
i++;
}
}
else if (Otop ==-1 || op == LEFT ) { //空栈或者栈顶为左括号时直接将运算符压栈
pushOp(op);
}
else //if(op==MUL || op==DIV || op==ADD || op==MIN)
{
while(Otop >=0 && Pri[topOp()]>=Pri[op] ){ // >= or > 思考
Postfixs[i].type = OP;
Postfixs[i].op = popOp();
i++;
}
pushOp(op);
}
}
void pushOp(enum oper op){
if(Otop == MAXSIZE -1){
printf("Operator stack is full!");
exit(1);
}
Op_stack[++Otop] = op;
}
enum oper popOp(){
if(Otop != -1){
return Op_stack[Otop--] ;
}
return EPT;
}
enum oper topOp(){
return Op_stack[Otop];
}
//测试,中缀-->后缀
//1 + 2 * 3 + ( 4 * 5 + 6 ) / 7 =
//1 2 3 * + 4 5 * 6 + 7 / +
void print_Postfixs()
{
for(int j=0; j<i; j++)
{
if(Postfixs[j].type == NUM)
printf("%d ",Postfixs[j].num);
else if(Postfixs[j].type == OP)
switch(Postfixs[j].op) {
case ADD: printf("+ "); break;
case MIN: printf("- "); break;
case MUL: printf("* "); break;
case DIV: printf("/ "); break;
default: printf("OTHERS"); break;
}
}
printf("\n");
}
void print_op_num(BTNode *p)
{
if(p->type == NUM)
printf("%d ",p->num);
else if(p->type == OP)
switch(p->op) {
case ADD: printf("+ "); break;
case MIN: printf("- "); break;
case MUL: printf("* "); break;
case DIV: printf("/ "); break;
default: printf("OTHERS"); break;
}
}
BTNode *create_express_tree()
{
/*
后缀表达式-->表达式树:
我们一次一个符号地读入表达式。
如果符号是操作数,那么就建立一个单结点树并将它推入栈中。
如果符号是操作符,那么就从栈中弹出两棵树T1和T2(T1先弹出)并形成一棵新的树,该树的根就是操作符,它的左、右儿子分别是T2和T1。然后将指向这颗树的指针压入栈中。
————————————————
原文链接:https://blog.csdn.net/buaa_shang/article/details/9124075
*/
BTNode *current;
for(int j=0; j<i; j++)
{
if(Postfixs[j].type == NUM)
{
current = (BTNodeptr)malloc(sizeof(BTNode));
current->type = NUM;
current->num = Postfixs[j].num;
current->lchild = NULL;
current->rchild = NULL;
push_stack(current);
}
else if(Postfixs[j].type == OP)
{
current = (BTNodeptr)malloc(sizeof(BTNode));
current->type = OP;
current->op = Postfixs[j].op;
current->rchild = pop_stack();
current->lchild = pop_stack();
push_stack(current);
}
}
return Tree_Stack[0];
}
void push_stack(BTNode *data)
{
if(Ttop == MAXSIZE -1){
printf("Operator stack is full!");
exit(1);
}
Tree_Stack[++Ttop]=data;
}
BTNode *pop_stack()
{
if(Ttop != -1){
return Tree_Stack[Ttop--] ;
}
printf("Operator stack is full!");
exit(1);
}
void Postorder (BTNodeptr t)
{
if(t!=NULL){
Postorder(t->lchild);
Postorder(t->rchild);
print_op_num(t);/* 访问T指结点 */
}
}
void compute()
{
dataType tmp;
for(int j=0; j<i; j++)
{
if(Postfixs[j].type == NUM)
pushNum(Postfixs[j].num);
else if(Postfixs[j].type == OP)
switch(Postfixs[j].op) {
case ADD:
pushNum(popNum() + popNum()); break;
case MIN:
tmp = popNum();
pushNum(popNum() - tmp); break;
case MUL:
pushNum(popNum() * popNum()); break;
case DIV:
tmp = popNum();
pushNum(popNum() / tmp); break;
case LEFT:case EPT:case RIGHT: break;
}
}
}
void pushNum(dataType num)
{
if(Ntop == MAXSIZE -1)
error("Data stack is full!");
Num_stack[++Ntop] = num;
}
dataType popNum()
{
if(Ntop == -1)
error("Error in the expression!3");
return Num_stack[Ntop--] ;
}
void error(char s[ ])
{
fprintf(stderr, "%s\n",s);
exit(1);
}
5.4 网络打印机选择
【问题描述】
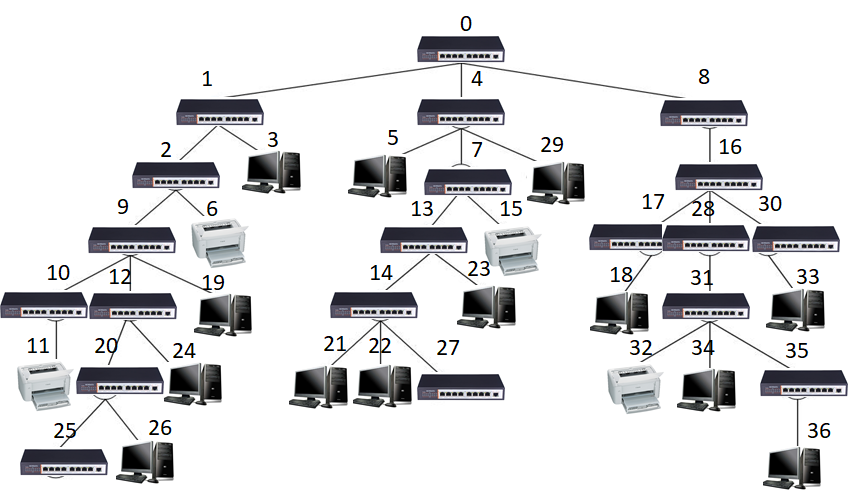
某单位信息网络结构呈树型结构,网络中节点可为交换机、计算机和打印机三种设备,计算机和打印机只能位于树的叶节点上。如要从一台计算机上打印文档,请为它选择最近(即经过交换机最少)的打印机。
在该网络结构中,根交换机编号为0,其它设备编号可为任意有效正整数,每个交换机有8个端口(编号0-7)。当存在多个满足条件的打印机时,选择按树前序遍历序排在前面的打印机。
【输入形式】
首先从标准输入中输入两个整数,第一个整数表示当前网络中设备数目,第二个整数表示需要打印文档的计算机编号。两整数间以一个空格分隔。假设设备总数目不会超过300。
然后从当前目录下的in.txt读入相应设备配置表,该表每一行构成一个设备的属性,格式如下:
<设备ID> <类型> <设备父节点ID> <端口号>
<设备ID>为一个非负整数,表示设备编号;<类型>分为:0表示交换机、1表示计算机、2表示打印机;<设备父结点ID>为相应结点父结点编号,为一个有效非负整数;<端口号>为相应设备在父结点交换机中所处的端口编号,分别为0-7。由于设备配置表是按设备加入网络时的次序编排的,因此,表中第一行一定为根交换机(其属性为0 0 -1 -1);其它每个设备结点一定在其父设备结点之后输入。每行中设备属性间由一个空格分隔,最后一个属性后有换行符。
【输出形式】
向控制台输出所选择的打印机编号,及所经过的交换机的编号,顺序是从需要打印文档的计算机开始,编号间以一个空格分隔。
【样例输入】
37 19
in.txt中的信息如下:
0 0 -1 -1
1 0 0 0
2 0 1 2
3 1 1 5
4 0 0 1
5 1 4 0
6 2 2 2
7 0 4 2
8 0 0 4
9 0 2 0
10 0 9 0
11 2 10 3
12 0 9 2
13 0 7 0
14 0 13 0
15 2 7 3
16 0 8 1
17 0 16 0
18 1 17 5
19 1 9 5
20 0 12 1
21 1 14 1
22 1 14 2
23 1 13 2
24 1 12 5
25 0 20 1
26 1 20 2
27 0 14 7
28 0 16 1
29 1 4 3
30 0 16 7
31 0 28 0
32 2 31 0
33 1 30 2
34 1 31 2
35 0 31 5
36 1 35 3
【样例输出】
11 9 10
【样例说明】
样例输入中37表示当前网络共有37台设备,19表示编号为19的计算机要打印文档。in.txt设备表中第一行0 0 -1 -1表示根节点交换机设备,其设备编号为0 、设备类型为0(交换机)、父结点设备编号-1表示无父设备、端口-1表示无接入端口;设备表第二行1 0 0 0表示设备编号为1 、设备类型为0(交换机)、父结点设备编号0(根交换机)、端口0表示接入父结点端口0;设备表中行5 1 4 0表示设备编号为5 、设备类型为1(计算机)、父结点设备编号4、端口0表示接入4号交换机端口0;设备表中行6 2 2 2表示设备编号为6 、设备类型为2(打印机)、父结点设备编号2、端口2表示接入2号交换机端口2。
样例输出11 9 10表示选择设备编号为11的打印机打印文档,打印需要经过9号和10号交换机(尽管6号和11号打印机离19号计算机距离相同,但11号打印机按树前序遍历时排在6号之前)。
「代码」
2018级期末考试题
本体涉及图的知识,待学完来写
在这里插入代码片
5.7 实验: 树的构造与遍历
1. 实验目的与要求
在学习和理解二叉树的原理、构造及遍历方法的基础上,应用所学知识来解决实际问题。
本实验将通过一个实际应用问题的解决过程掌握Huffman树的构造、Huffman编码的生成及基于所获得的Huffman编码压缩文本文件。
涉及的知识点包括树的构造、遍历及C语言位运算和二进制文件。
2. 实验内容
【问题描述】
编写一程序采用Huffman编码对一个正文文件进行压缩。具体压缩方法如下:
-
对正文文件中字符(换行字符’\n’除外,不统计)按出现次数(即频率)进行统计。
-
依据字符频率生成相应的Huffman树(未出现的字符不生成)。
-
依据Huffman树生成相应字符的Huffman编码。
-
依据字符Huffman编码压缩文件(即将源文件字符按照其Huffman编码输出)。
说明:
-
只对文件中出现的字符生成Huffman树,注意:一定不要处理\n,即不要为其生成Huffman编码。
-
采用ASCII码值为0的字符作为压缩文件的结束符(即可将其出现次数设为1来参与编码)。
-
在生成Huffman树前,初始在对字符频率权重进行(由小至大)排序时,频率相同的字符ASCII编码值小的在前;新生成的权重节点插入到有序权重序列中时,若出现相同权重,则将新生成的权重节点插入到原有相同权重节点之后(采用稳定排序)。
-
在生成Huffman树时,权重节点在前的作为左孩子节点,权重节点在后的作为右孩子节点。
-
遍历Huffman树生成字符Huffman码时,左边为0右边为1。
-
源文件是文本文件,字符采用ASCII编码,每个字符占8个二进制位;而采用Huffman编码后,高频字符编码长度较短(小于8位),因此最后输出时需要使用C语言中的位运算将字符的Huffman码依次输出到每个字节中。
【输入形式】
对当前目录下文件input.txt进行压缩。
【输出形式】
将压缩后结果输出到文件output.txt中,同时将压缩结果用十六进制形式(printf("%x",…))输出到屏幕上,以便检查和查看结果。
3. 实验准备
1.文件下载
从教学平台(judge.buaa.edu.cn)课程下载区下载文件lab_tree2.rar,该文件中包括了本实验中用到的文件huffman2student.c和input.txt:
-
huffman2student.c:该文件给出本实验程序的框架,框架中部分内容未完成(见下面相关实验步骤),通过本实验补充完成缺失的代码,使得程序运行后得到相应要求的运行结果;
-
input.txt:为本实验的测试数据。
2.huffman2student.c文件中相关数据结构说明
结构类型说明:
struct tnode { //Huffman树结构节点类型
char c;
int weight;
struct tnode *left;
struct tnode *right;
} ;
结构类型struct tnode用来定义Huffman树的节点,其中;
1)对于树的叶节点,成员c和weight用来存放字符及其出现次数;对于非叶节点来说,c值可不用考虑,weight的值满足Huffman树非叶节点生成条件,若p为当前Huffman树节点指针,则有:
p->weight = p->left->weight + p->right->weigth;
2)成员left和right分别为Huffman树节点左右子树节点指针。
全局变量说明:
int Ccount[128]={0};
struct tnode *Root=NULL;
char HCode[128][MAXSIZE]={0};
int Step=0;
FILE *Src, *Obj;
整型数组Ccount存放每个字符的出现次数,如Ccount[‘a’]表示字符a的出现次数。
变量Root为所生成的Huffman树的根节点指针。
数组HCode用于存储字符的Huffman编码,如HCode[‘a’]为字符a的Huffman编码,本实验中为字符串”1000”。
变量Step为实验步骤状态变量,其取值为1、2、3、4,分别对应实验步骤1、2、3、4。
变量Src、Obj为输入输出的文件指针,分别用于打开输入文件“input.txt”和输出文件“output.txt”。
4. 实验步骤
【步骤1】
1)实验要求
在程序文件huffman2student.c中“//【实验步骤1】开始”和“ //【实验步骤1】结束”间编写相应代码,以实现函数statCount,统计文本文件input.txt中字符出现频率。
//【实验步骤1】开始
void statCount()
{
}
//【实验步骤1】结束
2) 实验说明
函数statCount用来统计输入文件(文件指针为全局变量Src)中字符的出现次数(频率),并将字符出现次数存入全局变量数组Ccount中,如Ccount[‘a’]存放字符a的出现次数。
注意:在该函数中Ccount[0]一定要置为1,即Ccount[0]=1。编码值为0(’\0’)的字符用来作为压缩文件的结束符。
3) 实验结果
函数print1()用来打印输出步骤1的结果,即输出数组Ccount中字符出现次数多于0的字符及次数,编码值为0的字符用NUL表示。完成【步骤1】编码后,本地编译并运行该程序,并在标准输入中输入1,程序运行正确时在屏幕上将输出如下结果:

图1 步骤1运行结果
在本地运行正确的情况下,将你所编写的程序文件中//【实验步骤1】开始”和“ //【实验步骤1】结束”间的代码拷贝粘贴到实验报告后所附代码【实验步骤1】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据1评判结果为完全正确):
表明实验步骤1:通过,否则:不通过。
「代码1」
//【实验步骤1】开始
void statCount()
{
//字符频率统计:
char c;
while( (c=fgetc(Src)) != EOF){
Ccount[c]++;
}
Ccount[0]=1;
}
//【实验步骤1】结束
【步骤2】
1) 实验要求
在程序文件huffman2student.c中的 “//【实验步骤2】开始”和“ //【实验步骤2】结束”间编写相应代码,实现函数createHTree,该函数生成一个根结点指针为Root的Huffman树。
//【实验步骤2】开始
void createHTree( )
{
}
//【实验步骤2】结束
2) 实验说明
在程序文件huffman2student.c中函数createHTree将根据每个字符的出现次数(字符出现次数存放在全局数组Ccount中,Ccount[i]表示ASCII码值为i的字符出现次数),按照Huffman树生成规则,生成一棵Huffman树。
| 算法提示: |
-
依据数组Ccout中出现次数不为0的( 即Ccount[i]>0)项,构造出树林F={T0, T1, ¼, Tm},初始时Ti(0≤i≤m)为只有一个根结构的树,且根结点(叶结点)的权值为相应字符的出现次数的二叉树(每棵树结点的类型为struct tnode,其成员c为字符,weight为树节点权值):
for(i=0; i<128; i++)
if(Ccount[i]>0)
{
p = (struct tnode *)malloc(sizeof(struct tnode));
p->c = i; p->weight = Ccount[i];
p->left = p->right = NULL;
add p into F;
} -
对树林F中每棵树按其根结点的权值由小至大进行排序(排序时,当权值weight相同时,字符c小的排在前面),得到一个有序树林F
-
while 树个数>1 in F
a) 将F中T0和T1作为左、右子树合并成为一棵新的二叉树T’,并令T’->weight= T0->weight+ T1->wei
b) 删除T0和T1 from F,同时将T’加入F。要求加入T’后F仍然有序。若F中有树根结点权值与T’相同,则T’应加入到其后
-
Root = T0 (Root为Huffman树的根结点指针。循环结束时,F中只有一个T0)
注:在实现函数createHTree时,在框中还可根据需要定义其它函数,例如:
void myfun()
{
…
}
void createHTree()
{
…
myfun();
…
}
3) 实验结果
函数print2()用来打印输出步骤2的结果,即按前序遍历方式遍历步骤2所生成(由全局变量Root所指向的)Huffman树结点字符信息。输出时编码值为0的字符用NUL表示、空格符用SP表示、制表符用TAB表示、回车符用CR表示。完成【步骤2】编码后,本地编译并运行该程序,并在标准输入中输入2,程序运行正确时在屏幕上将输出如下结果:

在本地运行正确的情况下,将你在本地所编写的程序文件中//【实验步骤2】开始”和“ //【实验步骤2】结束”间的代码拷贝粘贴到实验报告后所附代码【实验步骤2】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据2评判结果为完全正确):
表明实验步骤2:通过,否则:不通过。
「代码2」
//【实验步骤2】开始
void createHTree()
{
//第一步为了生成Huffman树,首先根据字符统计结果生成一个有序链表:
struct tnode *p,*F[100];
int start=0,end=-1;
for(int i=0; i<128; i++)
if(Ccount[i]>0)
{
p = (struct tnode *)malloc(sizeof(struct tnode));
p->c = i;
p->weight = Ccount[i];
p->left = p->right = NULL;
//add p into F;
F[++end]=p;
}
//对树林F中每棵树按其根结点的权值由小至大进行排序(排序时,当权值weight相同时,字符c小的排在前面),得到一个有序树林F
struct tnode * temp;
for(int i=end; i>0 ; i--){
for(int j=0;j<i;j++)
if(F[j]->weight>F[j+1]->weight){
temp=F[j];
F[j]=F[j+1];
F[j+1]=temp; /* 交换两个元素的位置 */
}
}
//第二步按Huffman树生成算法,由有序表构造Huffman树:
//while 树个数>1 in F
// a) 将F中T0和T1作为左、右子树合并成为一棵新的二叉树T’,并令T’->weight= T0->weight+ T1->weight
// b) 删除T0和T1 from F,同时将T’加入F。要求加入T’后F仍然有序。若F中有树根结点权值与T’相同,则T’应加入到其后
while(start+1<end){
p = (struct tnode *)malloc(sizeof(struct tnode));
p ->weight = F[start]->weight + F[start+1]->weight;
p->left = F[start];
p->right = F[start+1]; /*将新树的根结点加入到有序结点链表中*/
start=start+2;
//insertSortLink(p);
F[++end]=p;
for(int i=end; i>0 ; i--){
for(int j=start;j<i;j++)
if(F[j]->weight>F[j+1]->weight){
temp=F[j];
F[j]=F[j+1];
F[j+1]=temp; /* 交换两个元素的位置 */
}
}
}
p = (struct tnode *)malloc(sizeof(struct tnode));
p ->weight = F[start]->weight + F[start+1]->weight;
p->left = F[start];
p->right = F[start+1];
//Root = T0 (Root为Huffman树的根结点指针。循环结束时,F中只有一个T0)
Root=p;
}
//【实验步骤2】结束
【步骤3】
1) 实验要求
在程序文件huffman2student.c中的 “//【实验步骤3】开始”和“ //【实验步骤3】结束”间编写相应代码,实现函数makeHCode,该函数依据【实验步骤3】中所产生的Huffman树为文本中出现的每个字符生成对应的Huffman编码。遍历Huffman树生成字符Huffman码时,左边为0右边为1。
//【实验步骤3】开始
void makeHCode( )
{
}
//【实验步骤3】结束
2) 实验说明
【步骤3】依据【步骤2】所生成的根结点为Root的Huffman树生为文本中出现的每个字符生成相应的Huffman编码。全局变量HCode定义如下:
char HCode[128][MAXSIZE];
HCode变量用来存放每个字符的Huffman编码串,如HCode[‘e’]存放的是字母e的Huffman编码串,在本实验中实际值将为字符串”011”。
| 算法提示: |
可编写一个按前序遍历方法对根节点为Root的树进行遍历的递归函数,并在遍历过程中用一个字符串来记录遍历节点时从根节点到当前节点的路径(经过的边),经过左边时记录为’0’,经过右边时记录为’1’;当遍历节点为叶节点时,将对应路径串存放到相应的HCode数组中,即执行strcpy(HCode[p->c],路径串)。
注:在实现函数makeHCode时,在框中还可根据需要定义其它函数,如调用一个有类于前序遍历的递归函数来遍历Huffman树生成字符的Huffman编码:
void visitHTree()
{
…
}
void makeHCode()
{
…
visitHTree();
…
}
3) 实验结果
函数print3()用来打印输出步骤3的结果,即输出步骤3所生成的存储在全局变量HCode中非空字符的Huffman编码串。完成【步骤3】编码后,本地编译并运行该程序,并在标准输入中输入3,在屏幕上将输出ASCII字符与其Huffman编码对应表,冒号左边为字符,右边为其对应的Huffman编码,其中NUL表示ASCII编码为0的字符,SP表示空格字符编码值为0的字符用,程序运行正确时在屏幕上将输出如下结果:
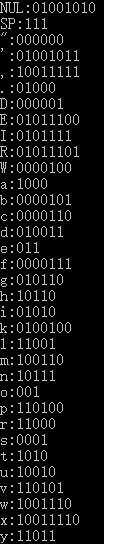
图3 步骤3运行结果
在本地运行正确的情况下,将你在本地所编写的程序文件中//【实验步骤3】开始”和“ //【实验步骤3】结束”间的代码拷贝粘贴到实验报告后所附代码【实验步骤3】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据3评判结果为完全正确):
表明实验步骤3:通过,否则:不通过。
「代码3」
//【实验步骤3】开始
char Huffman[MAXSIZE]; //用于生成Huffman编码
void createHCode(struct tnode *p,char code, int level)
{
if(level != 0)
Huffman[level-1] = code;
if(p->left == NULL && p->right == NULL){
Huffman[level] ='\0' ;
strcpy(HCode[p->c], Huffman);
}
else {
createHCode(p->left, '0', level+1);
createHCode(p->right, '1', level+1);
}
}
void makeHCode()
{
createHCode(Root, 0, 0);
}
//【实验步骤3】结束
【步骤4】
1) 实验要求
在程序文件huffman2student.c函数中的 “//【实验步骤4】开始”和“ //【实验步骤4】结束”间编写相应代码,实现函数atoHZIP,该函数依据【实验步骤3】中所生成的字符ASCII码与Huffman编码对应表(存储在全局变量HCode中,如HCode[‘e’]存放的是字符e对应的Huffman编码串,在本实验中值为字符串”011”),将原文本文件(文件指针为Src)内容(ASCII字符)转换为Huffman编码文件输出到文件output.txt(文件指针为Obj)中,以实现文件压缩。同时将输出结果用十六进制形式(printf("%x",…))输出到屏幕上,以便检查和查看结果。
//【实验步骤4】开始
void atoHZIP( )
{
}
//【实验步骤4】结束
2) 实验说明
| 算法提示: |
Huffman压缩原理:在当前Windows、Linux操作系统下,文本文件通常以ASCII编码方式存储和显示。ASCII编码是定长编码,每个字符固定占一个字节(即8位),如字符’e’的ASCII编码为十进制101(十六进制65,二进制为01100101)。而Huffman编码属于可变长编码,本实验中其依据文本中字符的频率进行编码,频率高的字符的编码长度短(小于8位),而频率低的字符的编码长度长(可能多于8位),如在本实验中,字符’ ’(空格)的出现频率最高(出现65次),其Huffman编码为111(占3位,远小于一个字节的8位),其它出现频率较高的字符,如字符’e’的Huffman编码为011、字符’o’的Huffman编码为111;字符’x’出现频率低(出现1次),其Huffman编码为10011110(占8位,刚好一个字节)(注意,在其它问题中,字符最长Huffman编码可能会超过8位)。正是由于高频字符编码短,将使得Huffman编码文件(按位)总长度要小于ASCII文本文件,以实现压缩文件的目的。
然而,将普通ASCII文本文件转换为变长编码的文件不便之处在于C语言中输入/输出函数数据处理的最小单位是一个字节(如putchar()),无法直接将Huffman(不定长)编码字符输出,在输出时需要将不定长编码序列转换为定长序列,按字节输出。而对于不定长编码,频率高的字符其编码要比一个字节短(如本实验中字符’e’的Huffman编码为011,不够一个字节,还需要和其它字符一起组成一个字节输出),频率低的编码可能超过一个字节。如何将不定长编码字符序列转换成定长字符序列输出,一个简单方法是:
-
根据输入字符序列将其Huffman编码串连接成一个(由0、1字符组成的)串;
-
然后依次读取该串中字符,依次放入到一个字节的相应位上;
-
若放满一个字节(即8位),可输出该字节;剩余的字符开始放入到下一个字节中;
-
重复步骤2和3,直到串中所有字符处理完。
下面通过实例来说明:
原始文件input.txt中内容以“I will…”开始,依据所生成的Huffman码表,字母I对应的Huffman编码串为“0101111”,空格对应“111”,w对应“1001110”,i对应“01010”,l对应 “11001”。因此,将其转换后得到一个Huffman编码串“01011111111001110010101100111001…”,由于在C中,最小输出单位是字节(共8位),因此,要通过C语言的位操作符将每8个01字符串放进一个字节中,如第一个8字符串“01011111”中的每个0和1放入到一个字符中十六进制(即printf(”%x”,c)输出时,屏幕上将显示5f)(如下图所示)。下面程序段将Huffman编码串每8个字符串放入一个字节(字符变量hc)中:
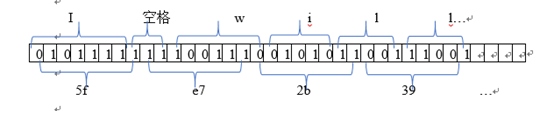
char hc;
…
for(i=0; s[i] != ‘\0’; i++) {
hc = (hc << 1) | (s[i]-'0');
if((i+1)%8 == 0) {
fputc(hc,obj); //输出到目标(压缩)文件中
printf("%x",hc); //按十六进制输出到屏幕上
}
}
…
说明:
1.当遇到源文本文件输入结束时,应将输入结束符的Huffman码放到Huffman编码串最后,即将编码串HCode[0]放到Huffman编码串最后。
2.在处理完成所有Huffman编码串时(如上述算法结束时),处理源文本最后一个字符(文件结束符)Huffman编码串(其编码串为“01001010”)时,可能出现如下情况:其子串”010”位于前一个字节中输出,而子串“01010”位于另(最后)一个字节的右5位中,需要将这5位左移至左端的头,最后3位补0,然后再输出最后一个字节。
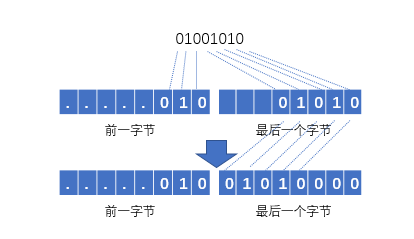
注:在实现函数atoHZIP时,在框中还可根据需要定义其它函数或全局变量,如:
void myfun()
{
…
}
void atoHZIP()
{
…
myfun();
…
}
3) 实验结果
函数print4()用来打印输出步骤4的结果,即根据输出步骤3所生成的存储在全局变量HCode中Huffman编码串,依次对源文本文件(input.txt)的ASCII字符转换为Huffman编码字符输出到文件output.txt中,同时按十六进行输出到屏幕上。完成【步骤4】编码后,本地编译并运行该程序,并在标准输入中输入4,在屏幕上将输出:
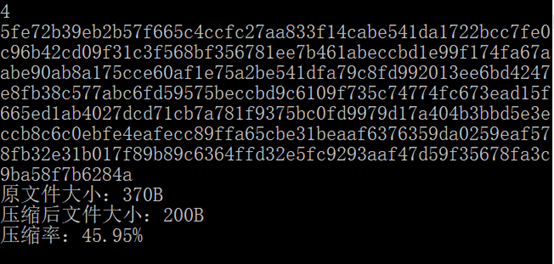
说明:
从屏幕输出结果可以看出,由于采用了不定长的Huffman编码,且出现频率高的字符的编码长度短,压缩后,文件大小由原来的370字节变为200字节,文件压缩了45.95%。
在本地运行正确的情况下,将你在本地所编写的程序文件中//【实验步骤4】开始”和“ //【实验步骤4】结束”间的代码拷贝粘贴到教学平台实验报告后所附代码【实验步骤4】下的框中,然后点击提交按钮,若得到如下运行结果(测试数据4评判结果为完全正确):
表明实验步骤4:通过,否则:不通过。
「代码4」
//【实验步骤4】开始
void atoHZIP()
{
unsigned char *pc,hc=0;//⚠️ unsigned char 8字节,char 4字节,否则会输出 ffffff 哦。
int c=0,i=0;
fseek(Src,0, SEEK_SET); //从src文件头开始
do {
c=fgetc(Src) ; //依次获取源文件中每个字符
if (c == EOF) c=0; //源文件结束
for(pc = HCode[c]; *pc != '\0'; pc++){ //转换为huffman码
hc = (hc << 1) | (*pc-'0'); i++;
if(i==8){ //每满8位输出一个字节
fputc(hc,Obj);
printf("%x",hc);
i = 0;
}
}
if(c==0 && i!=0){ //处理文件结束时不满一个字节的情况
while(i++<8) hc = (hc << 1);
fputc(hc,Obj);
printf("%x",hc);
}
} while (c ); //c=0时文件结束
}
//【实验步骤4】结束
「完整代码」
//文件压缩-Huffman实现
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAXSIZE 32
struct tnode { //Huffman树结构
int c;
int weight; //树节点权重,叶节点为字符和它的出现次数
struct tnode *left,*right;
} ;
int Ccount[128]={0}; //存放每个字符的出现次数,如Ccount[i]表示ASCII值为i的字符出现次数
struct tnode *Root=NULL; //Huffman树的根节点
char HCode[128][MAXSIZE]={{0}}; //字符的Huffman编码,如HCode['a']为字符a的Huffman编码(字符串形式)
int Step=0; //实验步骤
FILE *Src, *Obj;
void statCount(void); //步骤1:统计文件中字符频率
void createHTree(void); //步骤2:创建一个Huffman树,根节点为Root
void makeHCode(void); //步骤3:根据Huffman树生成Huffman编码
void atoHZIP(void); //步骤4:根据Huffman编码将指定ASCII码文本文件转换成Huffman码文件
void print1(void); //输出步骤1的结果
void print2(struct tnode *p); //输出步骤2的结果
void print3(void); //输出步骤3的结果
void print4(void); //输出步骤4的结果
int main()
{
if((Src=fopen("input.txt","r"))==NULL) {
fprintf(stderr, "%s open failed!\n", "input.txt");
return 1;
}
if((Obj=fopen("output.txt","w"))==NULL) {
fprintf(stderr, "%s open failed!\n", "output.txt");
return 1;
}
scanf("%d",&Step); //输入当前实验步骤
statCount(); //实验步骤1:统计文件中字符出现次数(频率)
(Step==1) ? print1(): 1; //输出实验步骤1结果
createHTree(); //实验步骤2:依据字符频率生成相应的Huffman树
(Step==2) ? print2(Root): 2; //输出实验步骤2结果
makeHCode(); //实验步骤3:依据Root为树的根的Huffman树生成相应Huffman编码
(Step==3) ? print3(): 3; //输出实验步骤3结果
(Step>=4) ? atoHZIP(),print4(): 4; //实验步骤4:据Huffman编码生成压缩文件,并输出实验步骤4结果
fclose(Src);
fclose(Obj);
return 0;
}
//【实验步骤1】开始
void statCount()
{
//字符频率统计:
char c;
while( (c=fgetc(Src)) != EOF){
Ccount[c]++;
}
Ccount[0]=1;
}
//【实验步骤1】结束
//【实验步骤2】开始
void createHTree()
{
//第一步为了生成Huffman树,首先根据字符统计结果生成一个有序链表:
struct tnode *p,*F[100];
int start=0,end=-1;
for(int i=0; i<128; i++)
if(Ccount[i]>0)
{
p = (struct tnode *)malloc(sizeof(struct tnode));
p->c = i;
p->weight = Ccount[i];
p->left = p->right = NULL;
//add p into F;
F[++end]=p;
}
//对树林F中每棵树按其根结点的权值由小至大进行排序(排序时,当权值weight相同时,字符c小的排在前面),得到一个有序树林F
struct tnode * temp;
for(int i=end; i>0 ; i--){
for(int j=0;j<i;j++)
if(F[j]->weight>F[j+1]->weight){
temp=F[j];
F[j]=F[j+1];
F[j+1]=temp; /* 交换两个元素的位置 */
}
}
//第二步按Huffman树生成算法,由有序表构造Huffman树:
//while 树个数>1 in F
// a) 将F中T0和T1作为左、右子树合并成为一棵新的二叉树T’,并令T’->weight= T0->weight+ T1->weight
// b) 删除T0和T1 from F,同时将T’加入F。要求加入T’后F仍然有序。若F中有树根结点权值与T’相同,则T’应加入到其后
while(start+1<end){
p = (struct tnode *)malloc(sizeof(struct tnode));
p ->weight = F[start]->weight + F[start+1]->weight;
p->left = F[start];
p->right = F[start+1]; /*将新树的根结点加入到有序结点链表中*/
start=start+2;
//insertSortLink(p);
F[++end]=p;
for(int i=end; i>0 ; i--){
for(int j=start;j<i;j++)
if(F[j]->weight>F[j+1]->weight){
temp=F[j];
F[j]=F[j+1];
F[j+1]=temp; /* 交换两个元素的位置 */
}
}
}
p = (struct tnode *)malloc(sizeof(struct tnode));
p ->weight = F[start]->weight + F[start+1]->weight;
p->left = F[start];
p->right = F[start+1];
//Root = T0 (Root为Huffman树的根结点指针。循环结束时,F中只有一个T0)
Root=p;
}
//【实验步骤2】结束
//【实验步骤3】开始
char Huffman[MAXSIZE]; //用于生成Huffman编码
void createHCode(struct tnode *p,char code, int level)
{
if(level != 0)
Huffman[level-1] = code;
if(p->left == NULL && p->right == NULL){
Huffman[level] ='\0' ;
strcpy(HCode[p->c], Huffman);
}
else {
createHCode(p->left, '0', level+1);
createHCode(p->right, '1', level+1);
}
}
void makeHCode()
{
createHCode(Root, 0, 0);
}
//【实验步骤3】结束
//【实验步骤4】开始
void atoHZIP()
{
unsigned char *pc,hc=0;//⚠️ unsigned char 8字节,char 4字节,否则会输出 ffffff 哦。
int c=0,i=0;
fseek(Src,0, SEEK_SET); //从src文件头开始
do {
c=fgetc(Src) ; //依次获取源文件中每个字符
if (c == EOF) c=0; //源文件结束
for(pc = HCode[c]; *pc != '\0'; pc++){ //转换为huffman码
hc = (hc << 1) | (*pc-'0'); i++;
if(i==8){ //每满8位输出一个字节
fputc(hc,Obj);
printf("%x",hc);
i = 0;
}
}
if(c==0 && i!=0){ //处理文件结束时不满一个字节的情况
while(i++<8) hc = (hc << 1);
fputc(hc,Obj);
printf("%x",hc);
}
} while (c ); //c=0时文件结束
}
//【实验步骤4】结束
void print1()
{
int i;
printf("NUL:1\n");
for(i=1; i<128; i++)
if(Ccount[i] > 0)
printf("%c:%d\n", i, Ccount[i]);
}
void print2(struct tnode *p)
{
if(p != NULL){
if((p->left==NULL)&&(p->right==NULL))
switch(p->c){
case 0: printf("NUL ");break;
case ' ': printf("SP ");break;
case '\t': printf("TAB ");break;
case '\n': printf("CR ");break;
default: printf("%c ",p->c); break;
}
print2(p->left);
print2(p->right);
}
}
void print3()
{
int i;
for(i=0; i<128; i++){
if(HCode[i][0] != 0){
switch(i){
case 0: printf("NUL:");break;
case ' ': printf("SP:");break;
case '\t': printf("TAB:");break;
case '\n': printf("CR:");break;
default: printf("%c:",i); break;
}
printf("%s\n",HCode[i]);
}
}
}
void print4()
{
long int in_size, out_size;
fseek(Src,0,SEEK_END);
fseek(Obj,0,SEEK_END);
in_size = ftell(Src);
out_size = ftell(Obj);
printf("\n原文件大小:%ldB\n",in_size);
printf("压缩后文件大小:%ldB\n",out_size);
printf("压缩率:%.2f%%\n",(float)(in_size-out_size)*100/in_size);
}















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









