






一、DB检测模型训练:
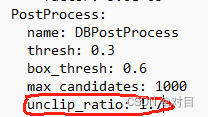
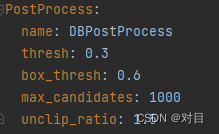
1.1 修改配置文件中的参数,该值越大,训练出来的模型的检测框也就越大,如下图所示:
1.2 为了保证训练好的模型转成推理模型效果一致,需要做以下修改:
1.2.1 把tools/infer/predict_det.py下这一行给注释掉
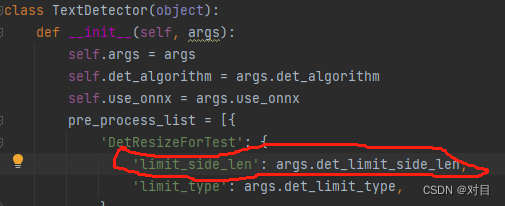
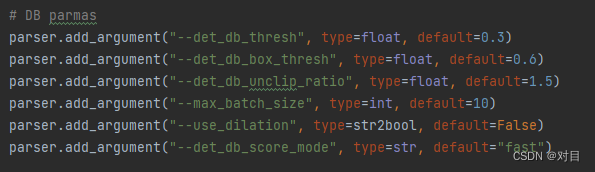
1.2.2 修改tools/infer/utillity.py脚本中的参数,要和配置文件中的后处理参数保持一致
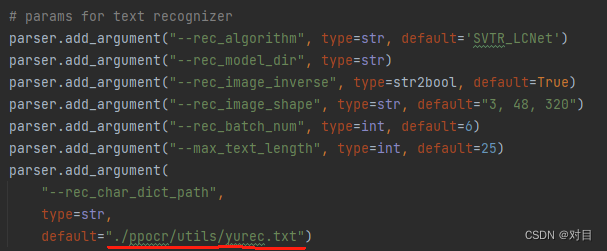
二、SVTR识别模型训练:
2.1 新建自己的字典文件,并修改配置文件中的字典文件地址:
![]()
如果要识别空格,要在字典文件中加上空格(不确定),反正下面要修改为true
![]()
2.2 转推理模型时做以下修改:
修改tools/infer/utillity.py脚本中字典文件地址,其他参数也要和配置文件中的保持一致
















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









