






使用自己的数据集训练st-gcn的流程
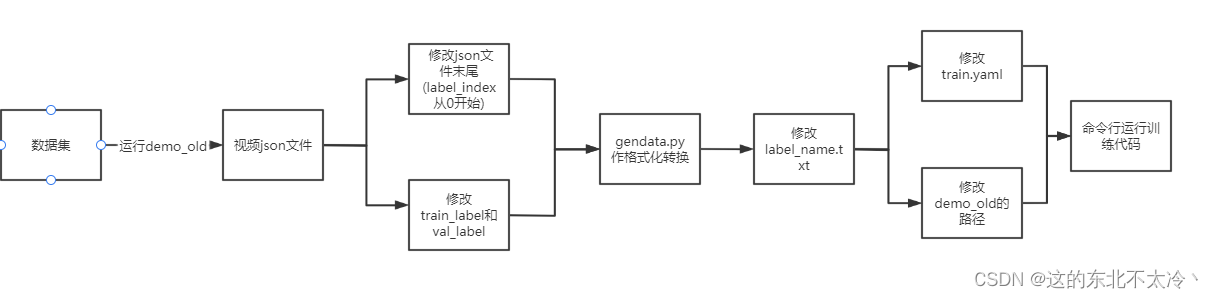
1.数据集
数据集要求将相同类别的视频放到同一文件夹

2.脚本运行demo_old
将文件夹下所有视频转为json格式
import os
dataSet_path = 'D:/dataSet/training_lib_KTH'#修改
for classes in os.listdir(dataSet_path):
classes_path = os.path.join(dataSet_path, classes)
if os.path.isdir(classes_path):
print(classes_path)
for file in os.listdir(classes_path):
file_path = os.path.join(classes_path,file)
str = 'python main.py demo_old --video {}'.format(file_path)
os.system(str)
3.更改json文件末尾
“label”:“unknow”,“label_index”: -1
改为
“label”:“自己的标签”,“label_index”: 标签下标
注意:第一个标签的下标要从0开始,否则后面会报错
3(2).修改train_label和val_label
这里建议参照以下博客的2.(3)
4.后面的步骤
后面的步骤上面博客说的很清楚,但有几个注意点
注意:
- label_name的行数从第1行开始的,这里的第一行对应的是label_index为0的类别。
- 数据集视频帧数不要超过300帧,5~6s的视频时长比较好,不要10几s的视频时长。
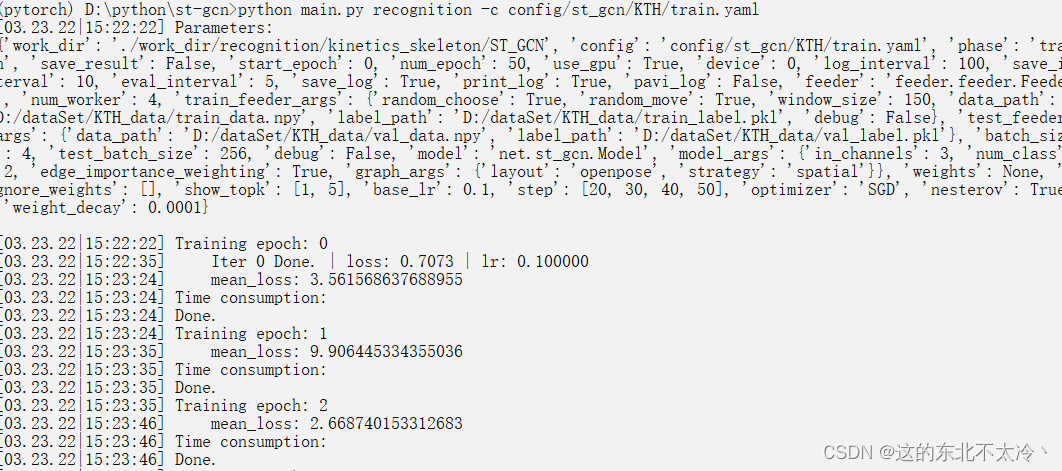
5.最后的结果
参考博客
[https://blog.csdn.net/weixin_48159023/article/details/121604637]
在校大学生,课业繁忙,不能及时回复,实在抱歉。

















 5519
5519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









