







reading notes of《Artificial Intelligence in Drug Design》
文章目录
1.Introduction
-
In the classic Corwin Hansch articleit was illustrated that, in general, biological activity for a group of “congeneric” chemicals can be described by a comprehensive model: L o g 1 / C 50 = a π + b ε + c S + d Log\ 1/C_{50}=a\pi+b\varepsilon+cS+d Log 1/C50=aπ+bε+cS+d
-
Deep learning is a particular kind of machine learning that overcomes these difficulties by representing the world as a nested hierarchy of concepts, with each concept defined in relation to simpler concepts, and more abstract representations computed in terms of less abstract ones.
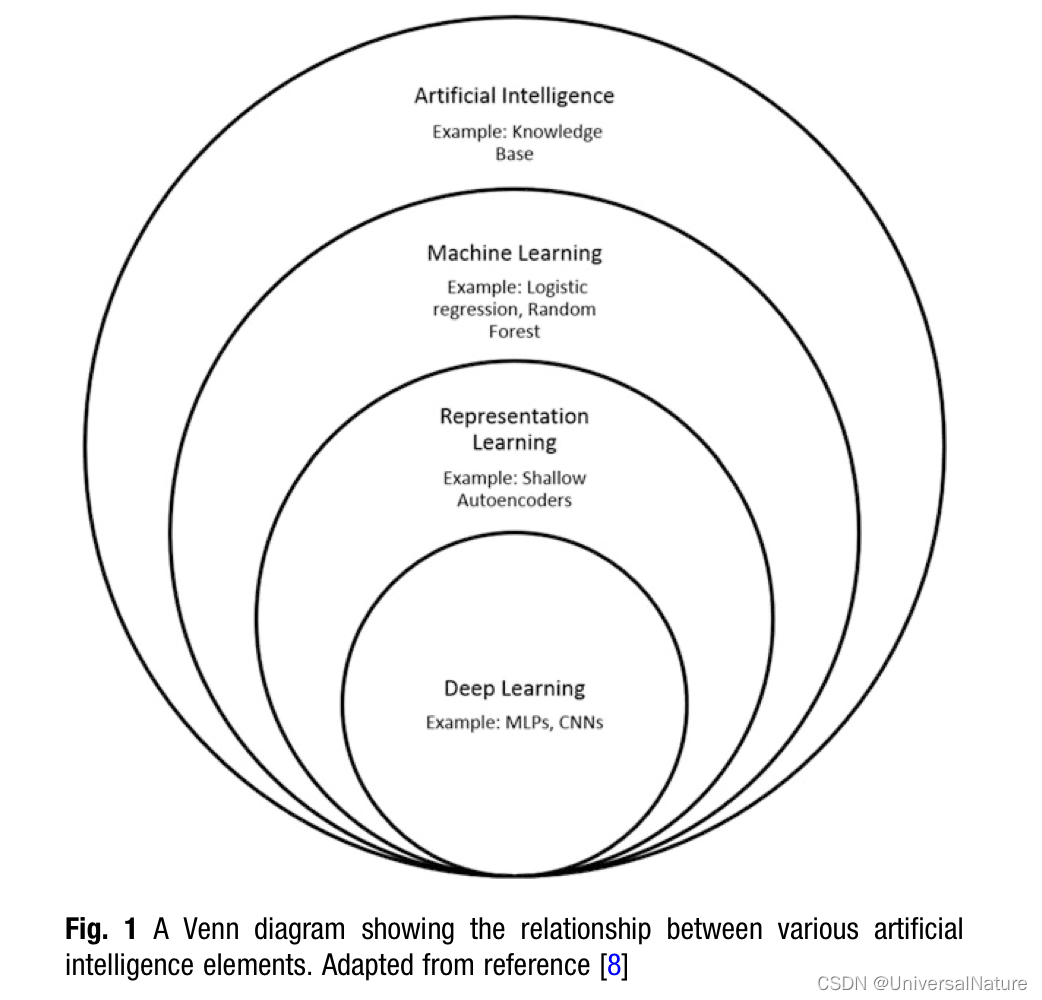
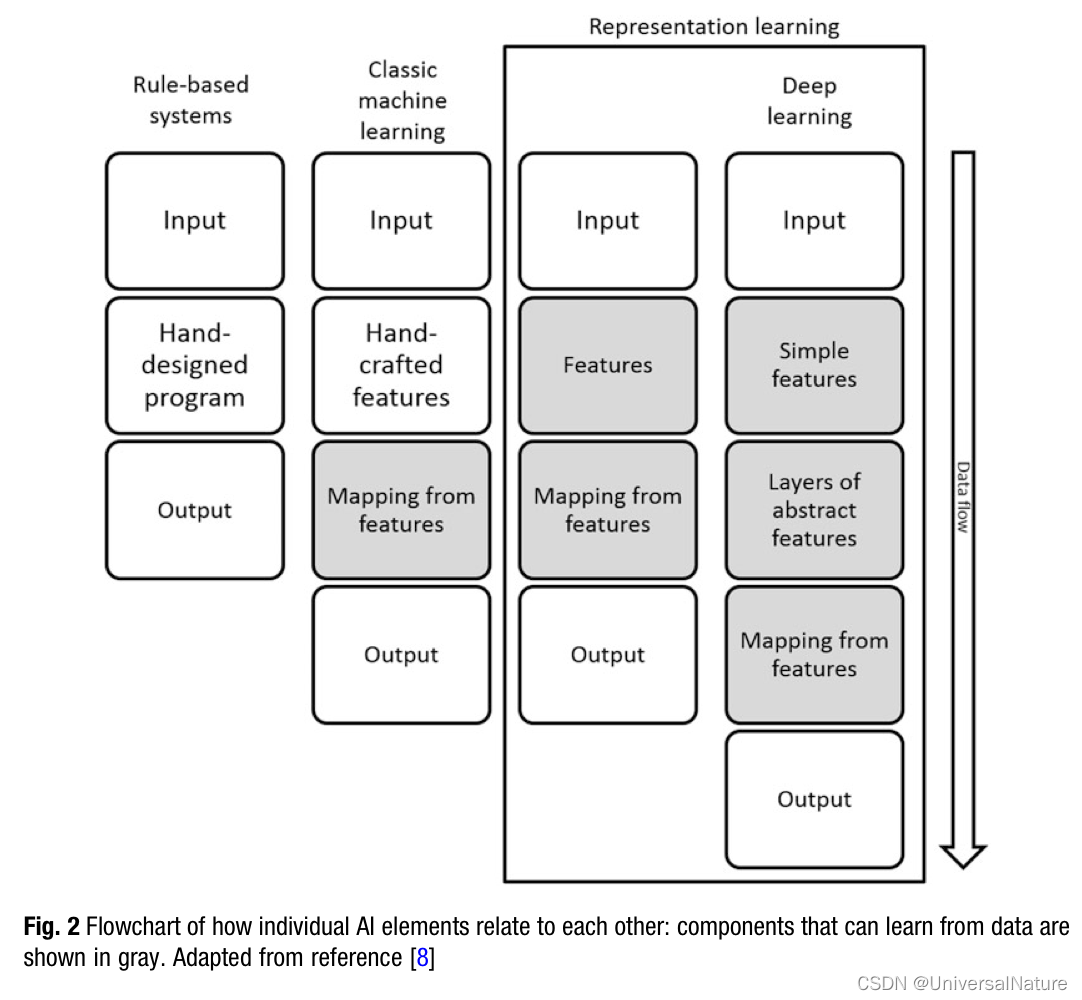
1.1.A Brief History of AI
-
The origins of the field can be traced as far back as the 1940s with the advent of the McCulloch-Pitts neuron as an early model of brain function.
-
In the 1950s, the perceptron became the first model that could learn its weights from the input.
-
The inherent limitations of the early methods eventually become apparent—expectations were raised far beyond the reality and progress was much slower than anticipated. This lead to the first “AI winter”—a period in which general interest in the field decreased dramatically, as did the funding.
-
An approach termed connectionism gathered speed in the 1980s. The central idea in connectionism is that a large number of simple computational units can achieve intelligent behavior when networked together.
-
The second wave of neural network research lasted until the mid-1990s. Expectations were, once again, raised too high and unrealistically ambitious claims were made while seeking investment. When AI research did not fulfil these expectations, investors and the public were disappointed. At the same time, other fields of machine learning made advances. Kernel machines and graphical models both achieved good results on many important tasks. These two factors led to a decline in the popularity of neural networks that lasted until the first decade of the twenty-first century.
-
The third wave of neural network research began with a break- through in 2006.
-
That deep learning models can achieve good performance has been known for some time and such models have been successfully used in commercial applications since the 1990s.
-
As more and more of our activities take place on computers, greater volumes of data are recorded every day leading to the current age of “big data.”
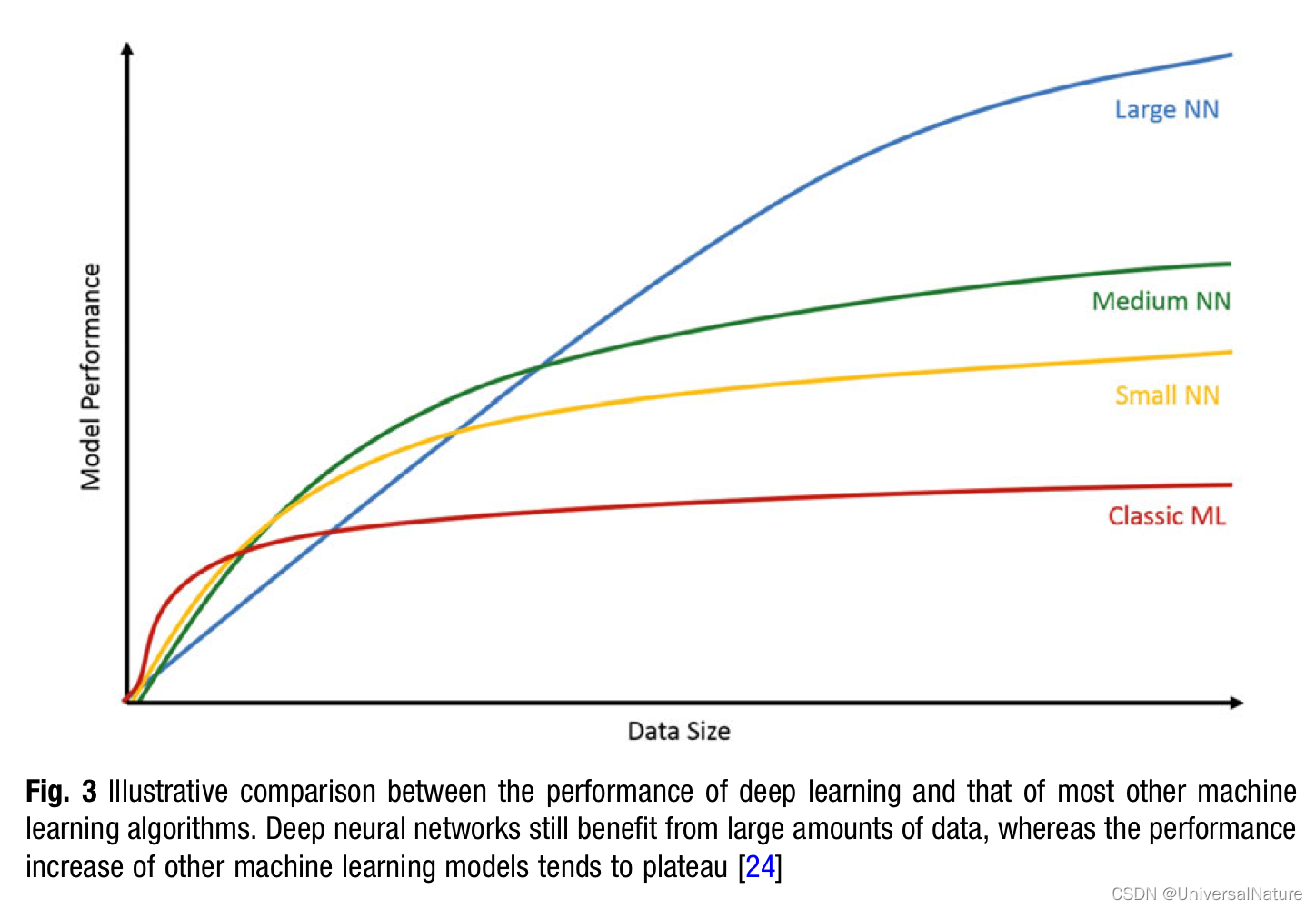
- Since the introduction of hidden layers artificial neural networks have doubled in size every 2.4 years.
- Chellapilla et al. proposed three novel methods to speed up deep convolutional neural networks: unrolling convolutions, using basic linear algebra software subroutines and using graphics processing units (GPUs).
- The recent rise of deep learning has also been greatly facilitated by various algorithmic developments.
- Last but not least, the increased availability and usability of software and documentation for training neural networks is another reason for the rapid adoption of deep learning in recent years.
2.Deep Learning Applications in Computational Chemistry
2.1.QSAR
- Perhaps the first application of deep learning to QSAR was during the Merck challenge in 2012.
- Random forest models were preferred in this case due to lower computational cost of training and the increased model interpretability.
- When trained on the same datasets and descriptors DNN predictions are frequently similar to those of other methods in terms of their practical utility. This observation is not surprising—while algorithmic improvements may result in slightly better statistics the overall quality of any model is still bound to the existence of an actual relationship between the modeled property and the features used to describe the molecules.
- It has further been suggested that the improvement relies on the training sets for the activities sharing similar compounds and features, and there being significant correlations between those activities.
- The (2-dimensional) structure of a molecule naturally forms a graph, which makes a class of deep learning techniques known as graph convolutional neural networks (GCNNs) a logical method choice in chemistry.
2.2.Generative Modeling
- Genetic algorithms are a popular choice for global optimization and have been applied in the chemistry domain.
- The three main deep learning approaches revolve around variational autoencoders (VAEs), reinforcement learning (RL) and generative adversarial networks (GANs). Recently, graph convolutional networks have also been applied to this problem.
- One of the seminal demonstrations of this method is the work of Go ́mezBombarelli et al. ,which used an autoencoder with a latent space that was optimized by an additional network to reflect a particular property.
- Convergence for GANs is not straightforward and can suffer from several issues, including mode collapse and overwhelming of the generator by the discriminator during training.
- Recently, DeepSMILES and SELFIES representations have also been developed in order to overcome some of the limitations of the SMILES syntax in the context of deep learning.
- RL considers the generator as an agent that must learn how to take actions (add characters) within an environment or task (SMILES generation) to maximize some notion of reward (properties).
- Generally speaking, VAEs and RNN approaches require large volumes of data to train as they model distributions. Usually ChEMBL or ZINC, both containing more than a million small molecules, are used to derive those models.
- To complicate the matter further, as experimental data is expensive and time consuming to gather the fitness of the generated molecules is usually assessed via QSAR models. A recent study used as many as 11 QSAR models to score and optimize compounds. Building good quality QSAR models is not trivial and requires the availability of high-quality experimental data. To circumvent that, most published work uses easily calculable properties like AlogP, molecular weight, etc. While demonstrating that the models work in principle, those experiments have little practical application.
2.3.Active Learning for Large-Scale Virtual Screening
-
Assuming that screening of larger libraries is intrinsically beneficial—and this has been debated in the literature—active learning should represent a more elegant alternative to the brute force approach.
-
In active learning, a cheaper surrogate model is iteratively trained on docking results for a subset of the overall library with the aim of avoiding the need to run the expensive calculations on all of the molecules.
-
The ability to provide useful estimates of prediction uncertainty is important for efficient exploration.
-
Predicting multiple outputs simultaneously, for example a docking score together with an interaction finger- print, can provide the opportunity to make a more nuanced assessment of virtual hits.
2.4.Deep Learning and Imputation
- An ongoing issue with many machine learning approaches, including standard deep learning, is the challenge of dealing with sparse data. In biomedical research sparse datasets are the norm rather than the exception and the level of missing data can be very high.
- Imputation is typically utilized as a pre-processing step to generate the dense input data that most machine learning algorithms require.
3.The Impact of Deep Learning
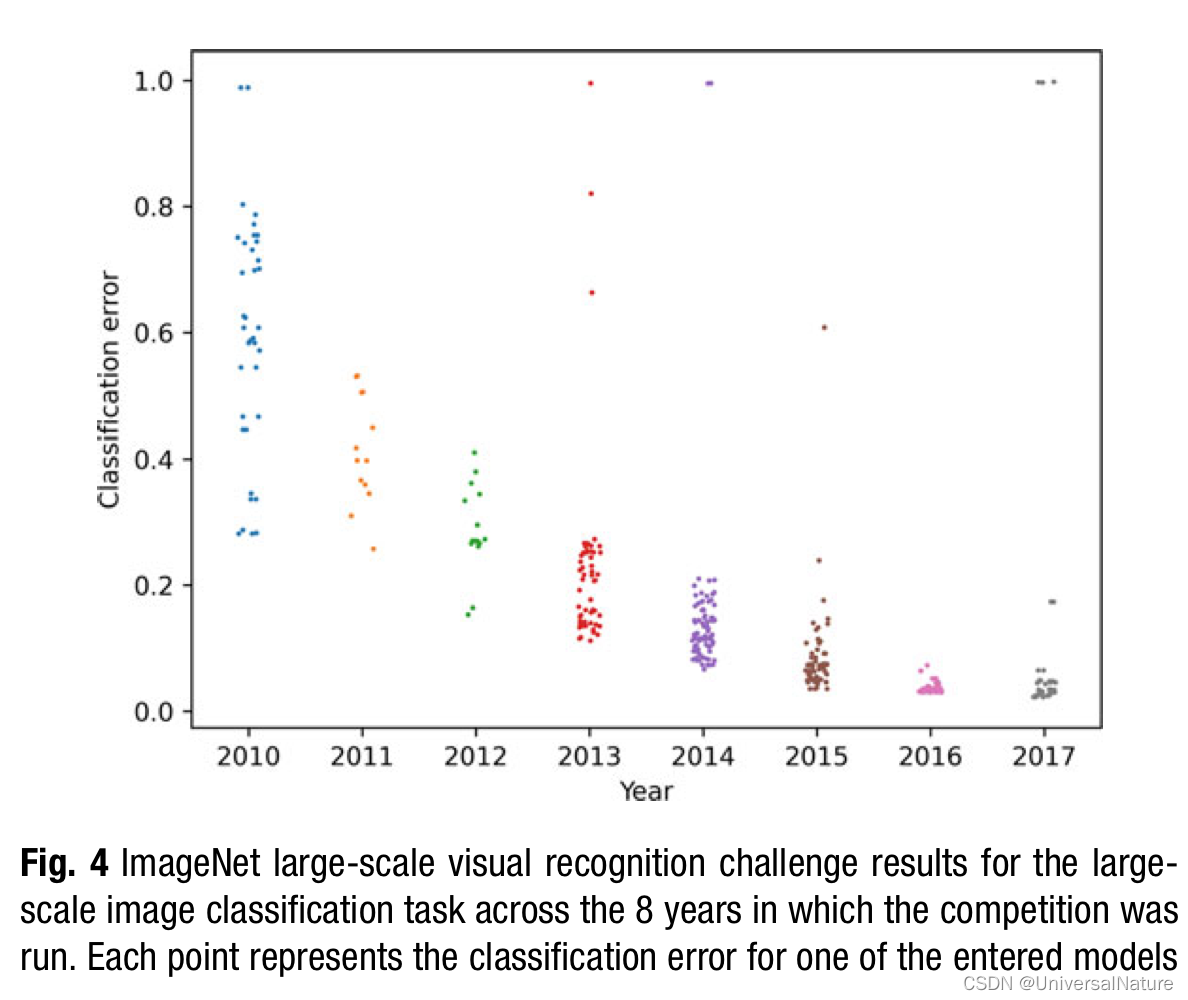
- One common factor that links the applications of deep learning described above (image analysis, NLP, game playing) is that they are artificial in the sense that they are governed by and, in many cases, evaluated according to human perceptions and experience.
- By contrast, most applications of deep learning in computational chemistry are concerned, at some level, with physical processes that are governed by fundamental physical laws. It is, perhaps, not surprising that the greater impact of an approach originally inspired by human neural architecture is perceived to be in the domain of human endeavor.
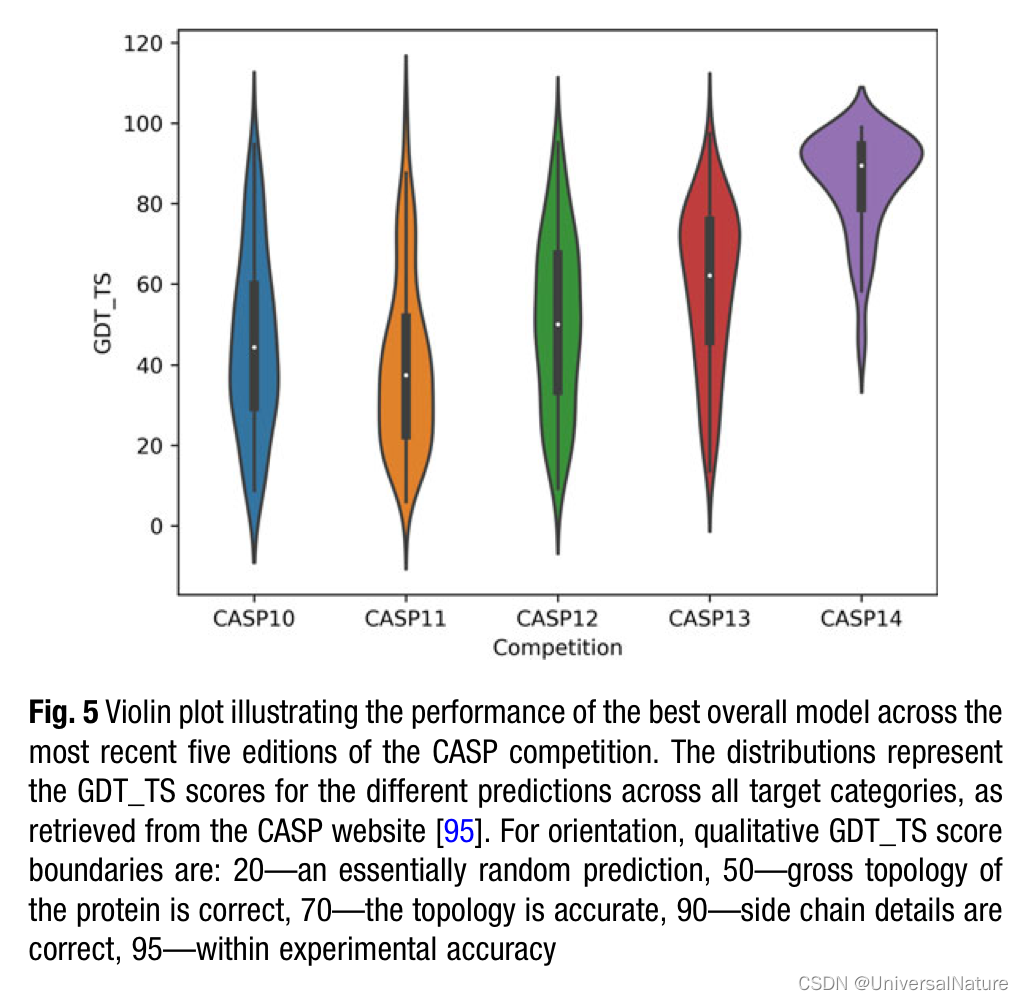
- On a more practical note, the availability of large training sets is another key factor for many successful applications of deep learning to date.
4.Open Issues with Deep Learning
- However, in our view there remain a number of challenges that currently prevent deep learning from achieving a level of practical benefit matching its popularity in both the popular and scientific literature.
4.1.Interpretability
- The “black box” nature has a number of negative repercussions:
- without an explanation of why a particular prediction is being made, other scientists such as medicinal chemists are likely to place much less emphasis on that prediction in their decision making processes.
- without understanding a model it can be very difficult to anticipate its likely failure modes i.e., when it will give reliable predictions on new examples that are distinct from those in the training set
- opaque models can conceal certain biases. In the context of most computational chemistry applications ethical issues are probably not critical but this may become the case where, for example, clinical data is utilized in training
- One recent publication has proposed the following elements of explainable AI (“XAI”): Transparency, Justification, Informative, Uncertainty estimation
- Feature attribution is probably the most commonly used local explanation approach in computational chemistry and, as most predictions are made for small molecules, the features that are typically used are individual atoms.
- Given its popularity, it is important to consider how robust this approach is. A recent study examined the behavior of one particular “coloring” algorithm across different datasets, descriptors and models. Atom “coloring” was found to be much more sensitive to descriptor and model choice than the overall predictive performance.
- One recent work has attempted to overcome the issue of interpretability in chemical deep learning by designing the architectures to allow for extraction of chemical insights from its decision making.
- Deep learning approaches are well known for identifying spurious correlations in training data that can lead to poor relative performance in a production setting.
- Approaches that attempt to automatically summarize explanations across datasets, for example to by identifying different “classification strategies” used by the model, have also been developed.
- One recent study compared four different approaches to uncertainty quantification—ensemble- based methods, distance-based methods, mean-variance estimation and union-based methods.
- One of the challenges in estimated uncertainty with models trained on experimental data is deconvoluting the epistemic uncertainty—that due to the model—from the aleatoric uncertainty— that due to the noise in the data itself.
- A fundamental aspect of modeling that ultimately may determine the limits both of predictive performance and interpretability is that of representation. (I think it’s a sort of Inductive Bias)
- It is possible for a learned representation to compensate for an input representation that is only weakly related to the properties of interest, but it is inevitably a harder problem to solve and the resulting model will be likely harder to interpret since any explanations must eventually be mapped back to the input representation.
4.2.Cost and Complexity
- State of the art approaches continue to push the limits of what is possible in terms of size. The compute costs alone for training one GPT-3 model have been estimated at $4.6 million.
- Away from the bleeding edge the increased costs of training associated with the drive toward ever larger and more complex model architectures have a number of potential consequences:
- the ability to reliably and robustly converge the training of these models is negatively impacted
- the ability to explore model variability within a specific architecture is reduced
- Increasing training costs is that it greatly limits the scope for performing hyperparameter optimization
- Beyond issues of democratization, extreme complexity has potentially serious implications for rigorous scientific review and debate over new techniques and results.
5.The Future of Deep Learning
- In the context of typical computational chemistry applications, such as QSAR modeling, the sometimes marginal improvements in predictive performance provided by deep learning are difficult to justify when balanced against the increased cost and reduced interpretability.
- One area where computational chemistry more frequently has access to large datasets is at the intersection with readouts such as transcriptomics or high content imaging.
- Challenges resulting from the computational cost and complexity of modern deep learning approaches seem likely to persist for the foreseeable future. Providing programmatic (API) access to very large models, such as GPT-3, would be one way to address this challenge.
















 4083
4083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











