







Spark组件部署
所需的压缩包百度网盘自取:
实操使需的压缩包: 链接
提取码:q9r6
一、前提条件:Hadoop Ha部署,确保有下面的所有进程
[root@master1 hadoop]# jps
71504 QuorumPeerMain
72320 ResourceManager
71602 JournalNode
72466 Jps
72424 NodeManager
71773 NameNode
71885 DataNode
72204 DFSZKFailoverController
[root@slave1 hadoop]# jps
2800 QuorumPeerMain
3074 DataNode
2884 JournalNode
2966 NameNode
3223 DFSZKFailoverController
3323 NodeManager
3454 Jps
[root@slave2 hadoop]# jps
11267 Jps
10905 JournalNode
10828 QuorumPeerMain
11134 NodeManager
10991 DataNode
二、解压 scala 安装包到“/usr/local/src”路径下,并更名为 scala,截图并保存结果
1、进入/h3cu/目录下找到压缩包
[root@master1 ~]# cd /h3cu/
[root@master1 h3cu]# ls
hadoop-2.7.1.tar.gz spark-2.0.0-bin-hadoop2.6.tgz
jdk-8u152-linux-x64.tar.gz zookeeper-3.4.8.tar.gz
scala-2.11.8.tgz
2、解压scala
[root@master1 h3cu]# tar -zxvf scala-2.11.8.tgz -C /usr/local/src/
3、重命名scala
[root@master1 h3cu]# cd /usr/local/src/
[root@master1 src]# mv scala-2.11.8/ scala
三、 设置 scala 环境变量,并使环境变量只对当前用户生效,截图并保存结果
1、添加scala环境变量
[root@master1 src]# vim /root/.bashrc
export SCALA_HOME=/usr/local/src/scala
export PATH=$PATH:$SCALA_HOME/bin
2、使环境变量立即生效
[root@master1 src]# source /root/.bashrc
四、进入 scala 并截图,截图并保存结果
1、输入命令 scala 进入scala界面
[root@master1 src]# scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_152).
Type in expressions for evaluation. Or try :help.
scala>
五、解压 Spark 安装包到“/usr/local/src”路径下,并更名为 spark,截图并保存结果
1、退出scala界面
使用ctrl + c 键退出scala界面
2、进入/h3cu/目录找到Spark
[root@master1 src]# cd /h3cu/
[root@master1 h3cu]# ls
hadoop-2.7.1.tar.gz spark-2.0.0-bin-hadoop2.6.tgz
jdk-8u152-linux-x64.tar.gz zookeeper-3.4.8.tar.gz
scala-2.11.8.tgz
3、解压Spark
[root@master1 h3cu]# tar -zxvf spark-2.0.0-bin-hadoop2.6.tgz -C /usr/local/src/
4、重命名Spark
[root@master1 h3cu]# cd /usr/local/src/
[root@master1 src]# mv spark-2.0.0-bin-hadoop2.6/ spark
六、设置 Spark 环境变量,并使环境变量只对当前用户生效,截图并保存结果
1、添加Spark环境变量
[root@master1 src]# vim /root/.bashrc
export SPARK_HOME=/usr/local/src/spark
export PATH=$PATH:$SAPTH_HOME=/bin
2、使环境变量立即生效
[root@master1 src]# source /root/.bashrc
七、修改 Spark 参数配置,指定 Spark slave 节点,截图并保存结果
1、进入/usr/local/src/spark/conf目录
[root@master1 src]# cd /usr/local/src/spark/conf/
2、新建slaves文件并写入
[root@master1 conf]# vi slaves
master1
slave1
slave2
注:该文件内容不可多无用空格或其他字符,严格遵守规范
3、新建spark-env.sh文件并写入
[root@master1 conf]# vim spark-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152/
export HADOOP_HOME=/usr/local/hadoop
export SCALA_HOME=/usr/local/src/scala
export SPARK_MASTER_IP=master1
export SPARK_MASTER_PORT=7077
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_YARN_USER_ENV="CLASSPATH=/usr/local/hadoop/etc/hadoop"
export YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master1:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark"
注:其中,三个参数的意义分别为:
SPARK_DIST_CLASSPATH 是完成 spark 和 hadoop 的挂接;
HADOOP_CONF_DIR 是说明了 hadoop 相关配置信息的目录;
SPARK_MASTER_IP 是指明该集群中主节点的 IP 地址或者名称。
4、集群分发
[root@master1 conf]# scp -r /usr/local/src/spark/ slave1:/usr/local/src/
[root@master1 conf]# scp -r /usr/local/src/spark/ slave2:/usr/local/src/
5、确保所有机器环境变量已经生效
[root@master1 conf]# source /root/.bashrc
注:三台机器均需执行
八、启动 Spark,并使用命令查看 webUI 结果,截图并保存结果
1、进入spark安装目录下启动spark
[root@master1 conf]# cd /usr/local/src/spark/
[root@master1 spark]# sbin/start-all.sh
注:确保zookeeper已经正常启动
[root@master1 spark]# jps
71504 QuorumPeerMain
72320 ResourceManager
71602 JournalNode
73397 Worker
73303 Master
73481 Jps
72424 NodeManager
71773 NameNode
71885 DataNode
72204 DFSZKFailoverController
[root@slave1 hadoop]# jps
2800 QuorumPeerMain
3905 Worker
3074 DataNode
2884 JournalNode
2966 NameNode
3223 DFSZKFailoverController
3992 Jps
3323 NodeManager
[root@slave2 hadoop]# jps
11542 Worker
11608 Jps
10905 JournalNode
10828 QuorumPeerMain
11134 NodeManager
10991 DataNode
2、浏览器输入master1-1:8080查看web UI
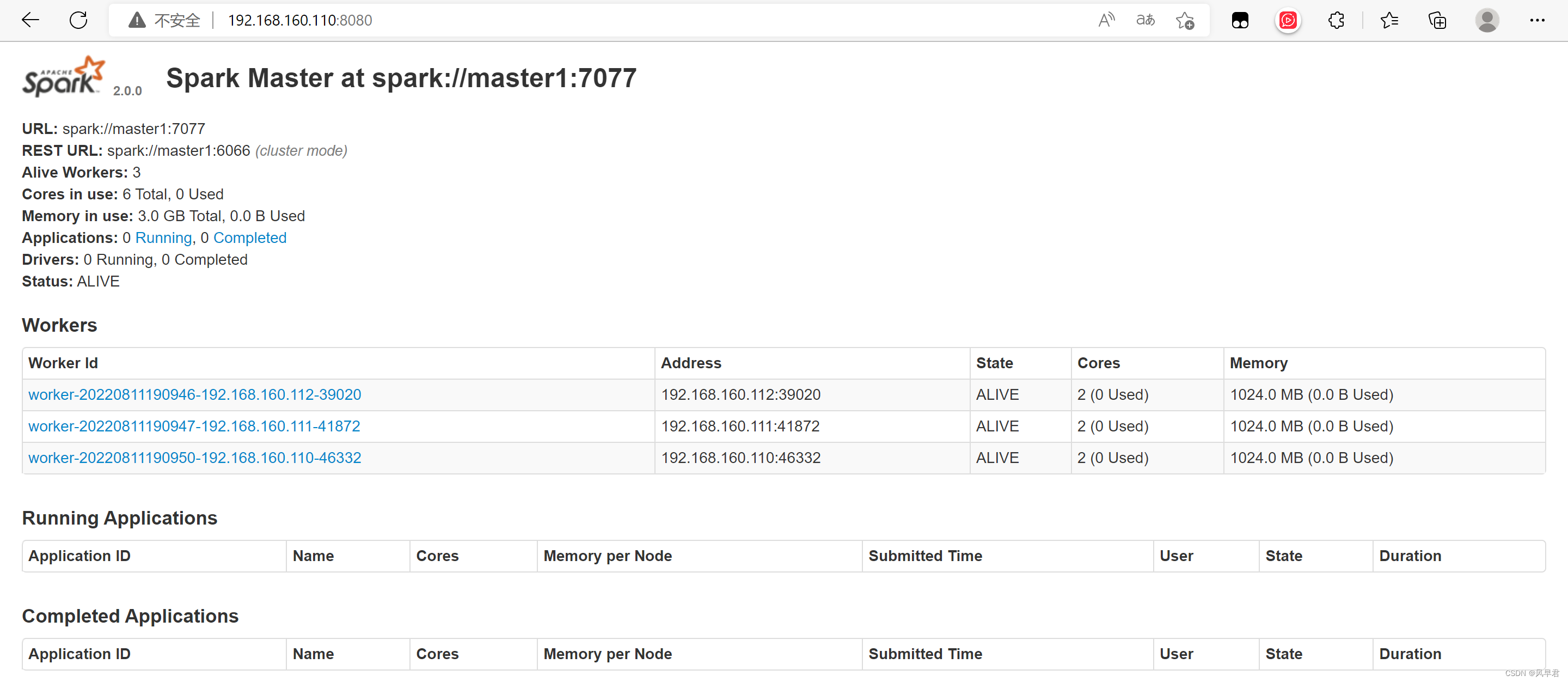
3、slave端启动master
[root@slave1 hadoop]# cd /usr/local/src/spark/
[root@slave1 spark]# sbin/start-master.sh
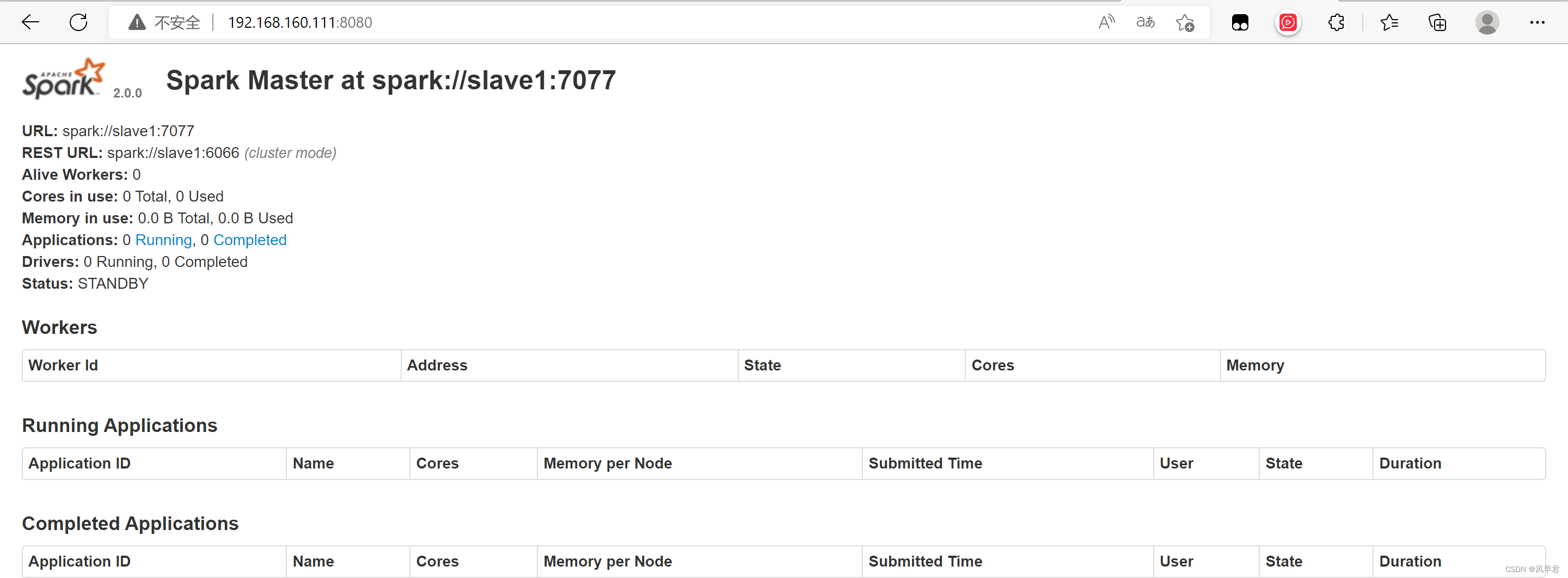
注:通过观察可知,主节点的 Master 状态为活动状态,从节点的Master状态为备用状态,即为集群成功运行















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









