







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
首先你要拥有spark和scala的安装包
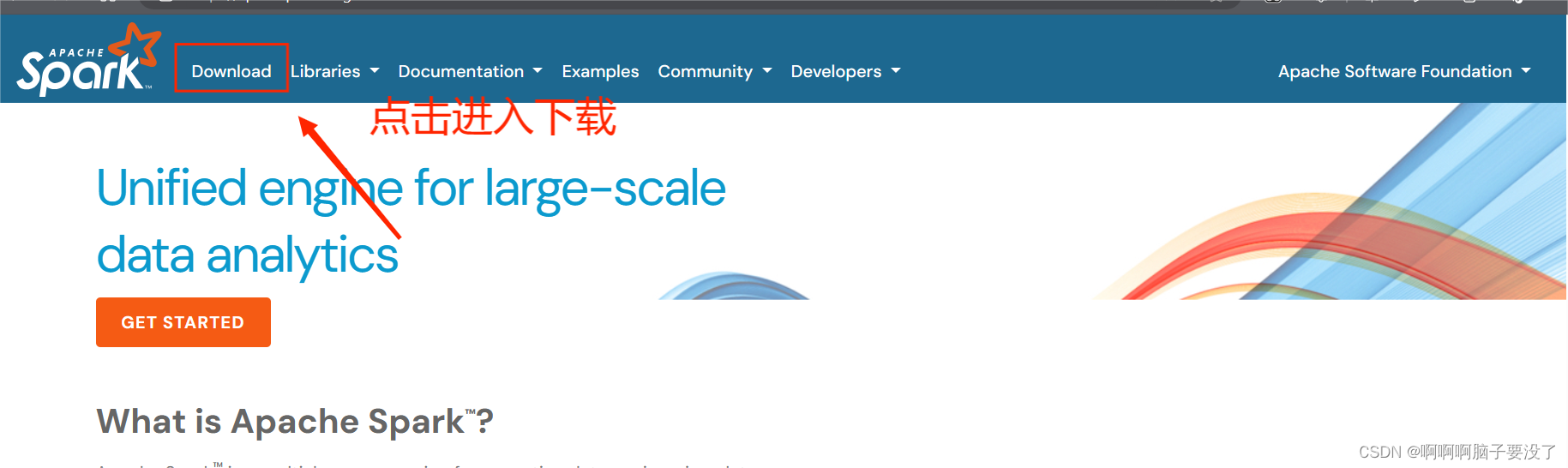
进入官网下载spark和Scala的安装包
spark

scala



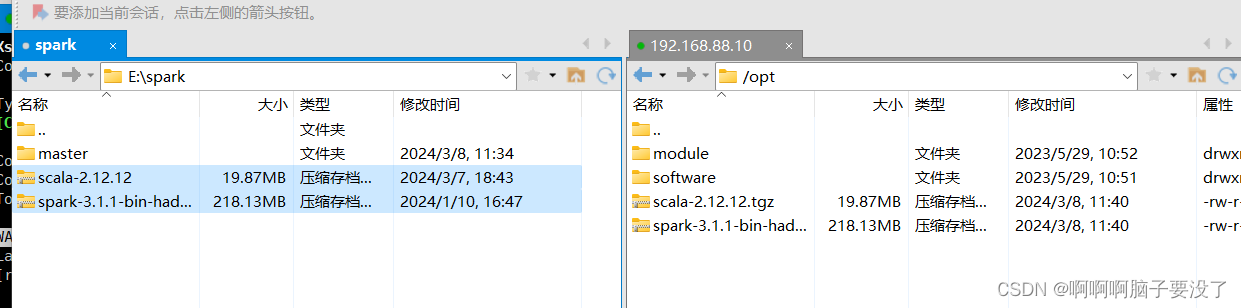
准备好后,将安装包导入虚拟机使用xshell或拖拽,建议导到opt目录下
进行scala的安装与配置
进入虚拟机或使用xshell进行配置(派大星选择用xshell)
使用xshell就要设置一下虚拟机的网络配置,改为NAT模式和子网IP改为192.168.88.0
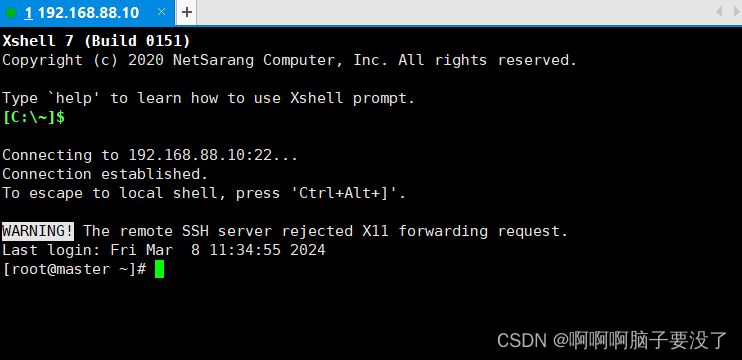
这是xshell连接成功的页面
解压安装包代码如下
tar -zxvf /opt/scala-2.12.12.tgz -C /opt/
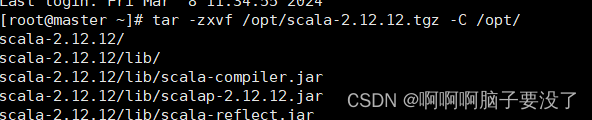
接着就要配置环境变量了
用vim命令进入etc下的profile
vim /opt/profile
进入后在最后加入这三行代码
#SCALA
export SCALA_HOME=/opt/scala-2.12.12
export PATH= P A T H : PATH: PATH:{SCALA_HOME}/bin
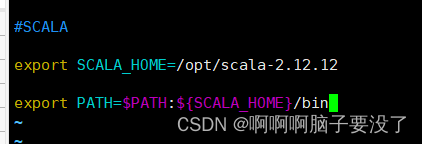
编写好后退出,用source使代码生效,在用scala -version查看是否成功,出现安装的版本号即为成功

进行spark安装与部署
解压安装包代码如下
tar -zxvf /opt/spark-3.1.1-bin-hadoop3.2.tgz -C /opt/

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
00ff254613a03fab5e56a57acb)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2192
2192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









