






首先介绍一下性能度量
性能度量:对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量
性能度量反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果;这意味着模型的"好坏"是相对的,什么样的模型是好的,不仅取决于算法和数据,还决定于任务需求。
分类任务中常用的性能度量
-
错误率与精度:通常我们把分类错误的样本数占样本总数的比例称为"错误率" ,即如果在m 个样本中有α 个样本分类错误,则错误率E= α/m; 相应的,1-α/m 称为"精度",即"精度=1一错误率“
错误率和精度虽常用,但并不能满足所有任务需求。以西瓜问题为例,假定瓜农拉来一车西瓜,我们用训练好的模型对这些西瓜进行判别,显然,错误率衡量了有多少比例的瓜被判别错误。但是若我们关心的是"挑出的西瓜中有多少比例是好瓜",或者"所有好瓜中有多少比例被挑了出来,那么错误率显然就不够用了,“查准率”与“查全率”更适合此类需求的性能度量
-
查准率、查全率
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划 分为真正例(true positive) 、假正例(false positive) 、真反倒(true negative) 、假反例(false negative) 四种情形

TP:被正确划分为正例的个数,即实际为正例且被分类器划分为正例的样例数
FP:被错误地划分为正例的个数,即实际为反例但被分类器划分为正例的样例数
FN:被错误地划分为反例的个数,即实际为正例但被分类器划分为反例的样例数
TN:被正确划分为反例的个数,即实际为反例且被分类器划分为反例的样例数
查准率P:
查全率R:
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
例如:查全率是希望将好瓜尽可能的选出来,可通过增加选瓜的数量来实现,如果将所有西瓜都选上,那么所有的好瓜也必然都被选上了,这样查准率就会比较低;查准率是希望选出的瓜中好瓜比例尽可能高,则可只挑选最有把握的瓜, 但这样就难免会漏掉不少好瓜,使得查全率较低.
P-R曲线:
在很多情形下,我们可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为"最可能"是正例的样本,排在最后的则是学习器认为"最不可能"是正例的样本。按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查全率、查准率,以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称" P-R 曲线"

如何通过P-R曲线比较两个机器学习模型的效果:
-
若一个学习器的P-R 曲线被另一个学习器的曲线完全"包住" , 则可断言后者的性能优于前者, 例如图2.3 中学习器A 的性能优于学习器C; 如果两个学习器的P-R 曲线发生了交叉, 例如图2.3 中的A 与B ,则难以一般性地断言两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较。
-
在很多情形下,人们往往仍希望把学习器A 与B 比出个高低。这时一个比较合理的判据是比较P-R 曲线下面积的大小,它在一定程度上表征了学习器在查准率和查全率上取得相对"双高"的比例。但这个值不太容易估算, 因此,人们设计了一些综合考虑查准率、查全率的性能度量,如平衡点,F1度量.
P-R曲线的绘制:(参考博客:http://t.csdn.cn/rbcFh)
图中有10个样本,真实标签和预测结果如下,首先根据学习器的预测结果对样例进行排序:
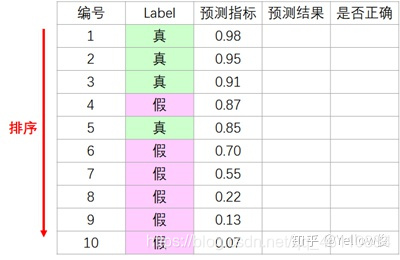
按此顺序逐个把样本作为正例进行预测, 我们把第一个样本作为正例:

此时可得到:
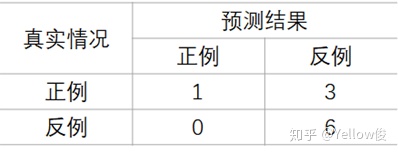
此时查准率P与查全率R分别为:
接着,我们把前三个当作正例:
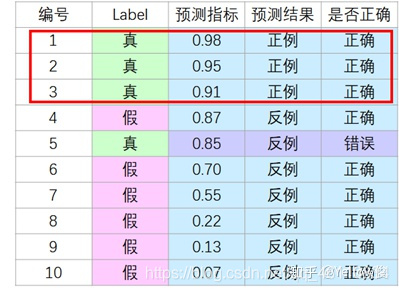
此时可得到:
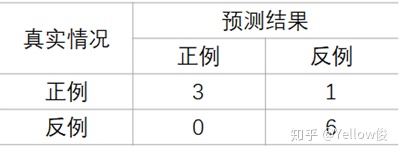
此时查准率P与查全率R分别为:
我们按顺序逐个把样本作为正例进行预测,就可以计算出当前的查全率、查准率。
ROC曲线:
ROC 全称是"受试者工作特征" (Receiver Operating Characteristic) 曲线,与P-R曲线相似,我们根据学习器的预测结果对样例进行排序,样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图'就得到了”ROC“曲线,与P-R 曲线使用查准率、查全率为纵、横轴不同, ROC 曲线的纵轴是"真正例率" (True Positive Rate,简称TPR) ,横轴是"假正例率" (False PositiveRate,简称FPR)

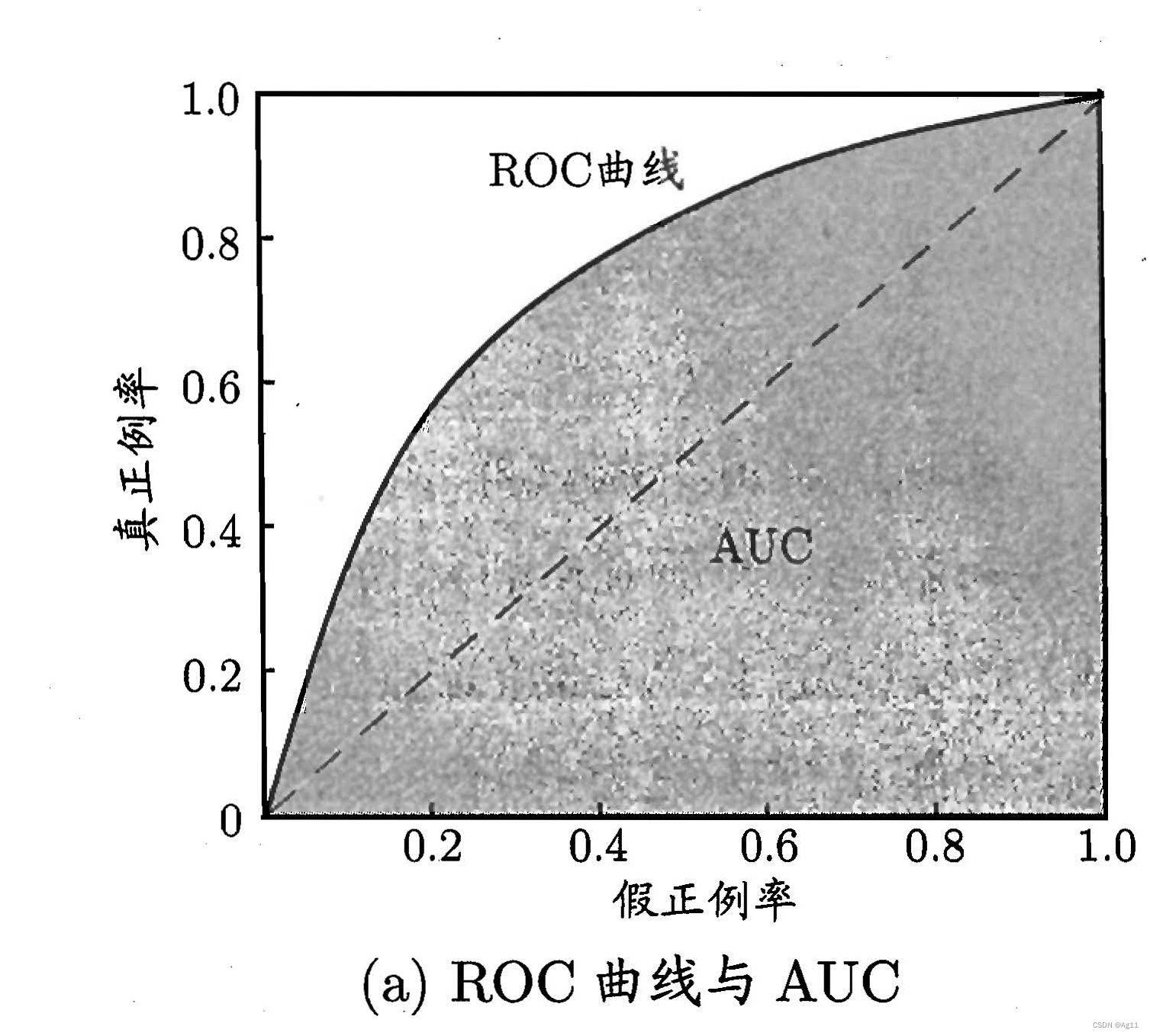
-
若一个学习器的ROC 曲线被另一个学习器的曲线完全"包住", 则可断言后者的性能优于前者;若两个学习器的ROC 曲线发生交叉,则难以一般性地断言两者孰优孰劣。此时如果一定要进行比较, 则较为合理的判据是比较ROC 曲线下的面积,即AUC
P-R曲线和ROC曲线绘制的代码实现:
导入需要的包:
from distutils.log import error
import matplotlib
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn. model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import roc_curve
from sklearn.linear_model import LogisticRegression加载数据集,进行训练,这里使用的是经典用于二分类任务的数据集, 乳腺癌数据集
# 使用Sklearn提供的乳腺癌数据集
data = load_breast_cancer()
X = data.data
y = data.target
# 划分训练集和测试集数据
X_train,X_test,y_train, y_test = train_test_split(X,y,test_size=0.3)
# 训练模型
model = LogisticRegression()
model.fit(X_train, y_train)
# predict_proba的输出是每个类别的概率,对于二分类问题,它的形状始终是(n_sample,2)
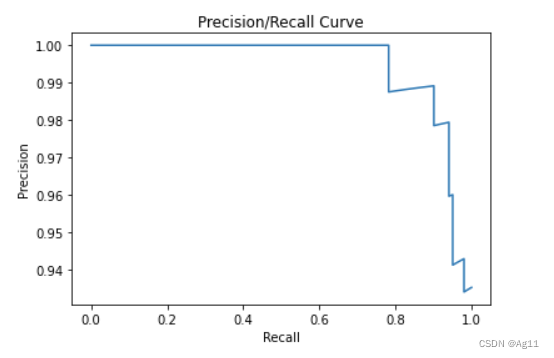
scores = model.predict_proba(X_test) P-R曲线的绘制:
plt.figure("P-R Curve")
plt.title('Precision/Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
# precision_recall_curve的输入为:
# y_test:二进制标签
# scores:估计的概率
# pos_label:正类的标签
# 计算不同的阈值的查全率和查准率,此实现仅限于二进制分类任务
precision, recall, thresholds = precision_recall_curve(y_test, scores[:,-1],pos_label=1)
plt.plot(recall,precision)
plt.show()运行结果如下:
ROC曲线绘制
plt.figure("ROC Curve")
plt.title('TPR/FPR Curve')
plt.xlabel('FPR')
plt.ylabel('TPR')
# roc_curve的输入为:
# y: 样本标签
# scores: 模型对样本属于正例的概率输出
# pos_label: 标记为正例的标签,本例中标记为1的即为正例
fpr,tpr, thresholds = metrics.roc_curve(y_test,scores[:,-1],pos_label=1)
plt.plot(fpr,tpr)
plt.show()运行结果如下:

PR曲线和ROC曲线的联系: (参考文章: ROC曲线和PR(Precision-Recall)曲线的联系_SEAN是一只程序猿 )
在机器学习中,ROC(Receiver Operator Characteristic)曲线被广泛应用于二分类问题中来评估分类器的可信度,但是当处理一些高度不均衡的数据集时,PR曲线能表现出更多的信息,发现更多的问题
参考书籍:[1]周志华. 机器学习[M]. 清华大学出版社, 2016.














 1602
1602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









