






CTC算法简介
CTC(Connectionist Temporal Classification)算法是一个用于OCR(文字识别)、ASR(语言识别)等任务场景的算法,主要用于解决输入序列和输入序列长度不一,难以对齐的问题。它提出了一种新的对齐方式,将输出序列切分为多个时间段,通过制定一定的处理规则来实现序列对齐的问题。
CTC算法
CTC算法的核心思想是在解决输入和输出序列的匹配问题。在语音识别中,我们无法确切的切分一个音所占的长度;在文字识别中,我们也无法自动切分出一个字所占的长度,从而进行切分识别。所以CTC提出了输入序列和输出序列之间不需要一一对齐,即不需要严格对齐。在CTC算法中,将文字图片切分成了等长的T块,并对每块进行多分类,从而实现文本的识别(语音识别也是一样的)。
当然此时大家的疑惑是这T块的识别中是不是有连着重复的字,如“cat”识别成“cccaatt”、“apple”识别成“appple”。
对于“cccaatt”这种识别,我们只需要将连续的重复字删除即可,但使用这中方法会导致“appple”识别成“aple”,这显然存在错误。故CTC的作者引入了"Blank"解决了这个问题
新标签blank
CTC算法引入了“blank”标签(即在原本的分类标签中加上了一个新的标签),用于指代句首、句尾或者词与词之间的间隙。
论文作者主要将blank插入到不同的词之间(本文使用“_”指代blank)即在识别“apple”时,“pp”之间插入了一个blank,那么“app_ple”或者“ap_pple”就可以识别成“apple”了。解决了语音识别或者文字识别中出现重复字符的情况。
故我们仅需对分类结果进行俩个操作:1、去除连续的重复字符;2、去除blank标签。我们就可以实现不严格对齐了。
CTC loss
解决了相邻字符相同的问题后,我们又遇到一个问题,那就是一个结果可能有多个匹配的路径。那么在模型训练时我们需要去寻找所有可能的路径,使各个路径的可能性最大化。所以作者提出了一种寻找所有路径的方法,并建立相应的损失函数
寻找所有路径
在模型训练时,我们需要去最大化与真实标签相匹配的所有路径的概率。所以我们需要从真实标签入手,去寻找真实标签对应的路径。例如我们的真实标签为(ab),序列长度为 T T T,那么我们将letter扩展为长度为 T T T的序列。
首先在所有“ab”中插入 b l a n k blank blank,即“_a_b_”。如果使用暴力算法去寻找所有路径,机器运行时间的消耗是非常大的。所以这里可以使用动态规划的思想,确定起始状态、转移条件,结束边界。
我们规定路径的第一个词只能为 b l a n k blank blank或者第一个字母“a”,同样的路径最后一个词也是 b l a n k blank blank或者最后一个字母“b”。
接下来我们需要确定的就是转移条件了,假设 x t = s k x_{t}=s_{k} xt=sk(其中 x t x_{t} xt是指 t t t时刻的输出, s k s_{k} sk是指标签第 k k k个元素),那么这个元素存在三种情况
- s k = b l a n k s_{k}=blank sk=blank,这种情况他就只能在 t + 1 t+1 t+1转移到当前的 b l a n k blank blank和下一个标签a,从下图上看 b l a n k blank blank从 x 1 x_{1} x1只能转移到第一个 b l a n k blank blank和标签a,不能转移到a下面的 b l a n k blank blank,否则就会出现路径中丢失a的情况。
- s k = s k + 2 s_{k}=s_{k+2} sk=sk+2,即标签 s k s_{k} sk和标签 s k + 2 s_{k+2} sk+2是相同的字符(除 b l a n k blank blank),那么它同第一种情况一样,只能转移到 t + 1 t+1 t+1时刻中的 s k s_{k} sk和 s k + 1 s_{k+1} sk+1。
- 除上述俩种情况外的情况,可以直接转移
t
+
1
t+1
t+1时刻中的
s
k
s_{k}
sk、
s
k
+
1
s_{k+1}
sk+1和
s
k
+
2
s_{k+2}
sk+2

通过上述的动态规划算法即可以实现寻找全部路径。
定义损失函数
由于我们的目的是使与真实结果路径的概率最大,即使
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)的概率达到最大,这里我们记所有可能的路径为
l
l
l,记
π
i
\pi_{i}
πi为其中的一条的路径,即
π
i
∈
l
\pi_{i}\in l
πi∈l,故损失函数为
O
M
L
(
l
)
=
−
∑
π
i
∈
l
ln
(
p
(
π
i
∣
x
)
)
O^{ML}(l) = -\sum_{\pi_{i}\in l}\ln(p(\pi_{i}|x))
OML(l)=−πi∈l∑ln(p(πi∣x))
向前向后算法
由于 p ( π i ∣ x ) p(\pi_{i}|x) p(πi∣x)的表达式未知,所以需要通过推导寻找其表达式。论文作者通过向前算法和向后算法结合,推导出了其表达式
首先定义向前变量 α t ( s ) = ∑ π i 1 : t ∈ l 1 : t ∏ t ′ = 1 t y π i t ′ t ′ \alpha_{t}(s) =\sum_{\pi_{i}^{1:t}\in l^{1:t}}\prod^{t}_{t'=1} y_{\pi_{i}^{t'}}^{t'} αt(s)=πi1:t∈l1:t∑t′=1∏tyπit′t′
即表示了在 1 → t 1\to t 1→t时刻经过标签 s s s的所有路径的概率和
在实际应用中,可以通过动态规划算法来求得 α t ( s ) \alpha_{t}(s) αt(s),具体如下
初始化 α 1 ( 1 ) = y b l a n k 1 \alpha_{1}(1) = y_{blank}^{1} α1(1)=yblank1, α 1 ( 2 ) = y l 1 1 \alpha_{1}(2) = y_{l_{1}}^{1} α1(2)=yl11( l 1 l_{1} l1是指label中的第一个字符), α 1 ( s ) = 0 ∣ ∀ s > 2 \alpha_{1}(s)=0|\forall s>2 α1(s)=0∣∀s>2
转移公式如下
α
t
(
s
)
=
{
(
α
t
−
1
(
s
−
1
)
+
α
t
−
1
(
s
)
)
y
s
t
i
f
l
s
=
b
l
a
n
k
∣
l
s
−
2
=
l
s
(
α
t
−
1
(
s
−
2
)
+
α
t
−
1
(
s
−
1
)
+
α
t
−
1
(
s
)
)
y
s
t
o
t
h
e
r
s
\alpha_{t}(s) = \left\{ \begin{aligned} &(\alpha_{t-1}(s-1)+\alpha_{t-1}(s))y_{s}^{t} & if\quad l_{s} = blank|l_{s-2} = l_{s} \\ &(\alpha_{t-1}(s-2)+\alpha_{t-1}(s-1)+\alpha_{t-1}(s))y_{s}^{t} & others\\ \end{aligned} \right .
αt(s)={(αt−1(s−1)+αt−1(s))yst(αt−1(s−2)+αt−1(s−1)+αt−1(s))ystifls=blank∣ls−2=lsothers
通过上述公式即可求出变量 α \alpha α
然后定义了向后变量 β t ( s ) = ∑ π i t : T ∈ l t : T ∏ t ′ = t T y π i t ′ t ′ \beta_{t}(s) = \sum_{\pi_{i}^{t:T}\in l^{t:T}}\prod^{T}_{t'=t} y_{\pi_{i}^{t'}}^{t'} βt(s)=πit:T∈lt:T∑t′=t∏Tyπit′t′
表示了在
T
→
t
T\to t
T→t时刻经过标签
s
s
s的所有路径的概率和
初始化
β
T
(
∣
l
∣
)
=
y
b
l
a
n
k
T
\beta_{T}(|l|) = y_{blank}^{T}
βT(∣l∣)=yblankT,
β
T
(
∣
l
∣
−
1
)
=
y
l
∣
l
∣
T
\beta_{T}(|l|-1) = y_{l_{|l|}}^{T}
βT(∣l∣−1)=yl∣l∣T(
∣
l
∣
|l|
∣l∣是指label的长度),
β
T
(
s
)
=
0
∣
∀
s
<
∣
l
∣
−
1
\beta_{T}(s)=0|\forall s<|l|-1
βT(s)=0∣∀s<∣l∣−1
转移公式如下
β
t
(
s
)
=
{
(
β
t
+
1
(
s
)
+
β
t
+
1
(
s
+
1
)
)
y
s
t
i
f
l
s
=
b
l
a
n
k
∣
l
s
+
2
=
l
s
(
β
t
+
1
(
s
)
+
β
t
+
1
(
s
+
1
)
+
β
t
+
1
(
s
+
2
)
)
y
s
t
o
t
h
e
r
s
\beta_{t}(s) = \left\{ \begin{aligned} &(\beta_{t+1}(s)+\beta_{t+1}(s+1))y_{s}^{t} &if\quad l_{s} = blank|l_{s+2} = l_{s} \\ &(\beta_{t+1}(s)+\beta_{t+1}(s+1)+\beta_{t+1}(s+2))y_{s}^{t} & others\\ \end{aligned} \right .
βt(s)={(βt+1(s)+βt+1(s+1))yst(βt+1(s)+βt+1(s+1)+βt+1(s+2))ystifls=blank∣ls+2=lsothers
通过上述公式即可求出变量 β \beta β
然后将俩个变量相乘,得到 α t ( s ) β t ( s ) = ∑ π i ∈ l ∣ π i t = s y s t p ( π i ∣ x ) \alpha_{t}(s)\beta_{t}(s) = \sum_{\pi_{i}\in l |\pi_{i}^{t}=s} y_{s}^{t}p(\pi_{i}|x) αt(s)βt(s)=πi∈l∣πit=s∑ystp(πi∣x)
他们相乘之后就得到所有 t t t时刻经过标签 s s s路径的概率,结果中多了一个 y s t y_{s}^{t} yst,这是因为向前和向后变量各有一个,但是总的路径中只到一次。
所以 ∑ π i ∈ l ∣ π i t = s p ( π i ∣ x ) = α t ( s ) β t ( s ) y s t \sum_{\pi_{i}\in l |\pi_{i}^{t}=s}p(\pi_{i}|x) = \frac{\alpha_{t}(s)\beta_{t}(s)}{ y_{s}^{t}} πi∈l∣πit=s∑p(πi∣x)=ystαt(s)βt(s)
所以有 − ∑ π i ∈ l ln ( p ( π i ∣ x ) ) = − ln ( ∏ π i ∈ l p ( π i ∣ x ) ) = − ln ( ∑ s = 1 ∣ l ∣ ∑ π i ∈ l ∣ π i t = s p ( π i ∣ x ) ) = − ln ( ∑ s = 1 ∣ l ∣ α t ( s ) β t ( s ) y s t ) -\sum_{\pi_{i}\in l}\ln(p(\pi_{i}|x)) =-\ln(\prod_{\pi_{i}\in l}p(\pi_{i}|x))= -\ln(\sum_{s=1}^{|l|}\sum_{\pi_{i}\in l |\pi_{i}^{t}=s}p(\pi_{i}|x)) =-\ln(\sum_{s=1}^{|l|}\frac{\alpha_{t}(s)\beta_{t}(s)}{ y_{s}^{t}}) −πi∈l∑ln(p(πi∣x))=−ln(πi∈l∏p(πi∣x))=−ln(s=1∑∣l∣πi∈l∣πit=s∑p(πi∣x))=−ln(s=1∑∣l∣ystαt(s)βt(s))
接下来对
y
s
t
y_{s}^{t}
yst求导就有
∂
−
∑
π
i
∈
l
ln
(
p
(
π
i
∣
x
)
)
∂
y
s
t
=
−
1
∑
s
=
1
∣
l
∣
α
t
(
s
)
β
t
(
s
)
y
s
t
α
t
(
k
)
β
t
(
k
)
y
k
t
2
\frac{\partial -\sum_{\pi_{i}\in l}\ln(p(\pi_{i}|x))}{\partial y_{s}^{t}} = -\frac{1}{\sum_{s=1}^{|l|}\frac{\alpha_{t}(s)\beta_{t}(s)}{ y_{s}^{t}}}\frac{\alpha_{t}(k)\beta_{t}(k)}{y_{k}^{t^{2}}}
∂yst∂−∑πi∈lln(p(πi∣x))=−∑s=1∣l∣ystαt(s)βt(s)1ykt2αt(k)βt(k)
此处分母是平方的原因是 α \alpha α和 β \beta β各包含一个 y y y,所以原来的方程中只有一个一次的 y y y,求导完就为1了,但是为了保持它们的形式,我们需要补俩个 y y y给它,即 y 2 y^{2} y2
寻找最佳路径
由于模型预测的路径存在多对一的情况,若我们仅选择每个时刻的最大概率作为结果,那么可能存在多条相同结果的路径概率值大于该结果的情况,那么就说明了模型结果不一定是最佳路径。那么为了解决这个问题分别使用了prefix beam search和beam search。
beam search
beam search的思想相对简单,它是从时刻
1
1
1开始预测,寻找
n
n
n(
n
n
n为超参此处假设为3)个概率最大的值作为候选,然后从3个候选产生的9条路径中,寻找在求时刻
2
2
2最大概率的三条路径,以此类推寻找最佳的3条路径。具体过程见下图
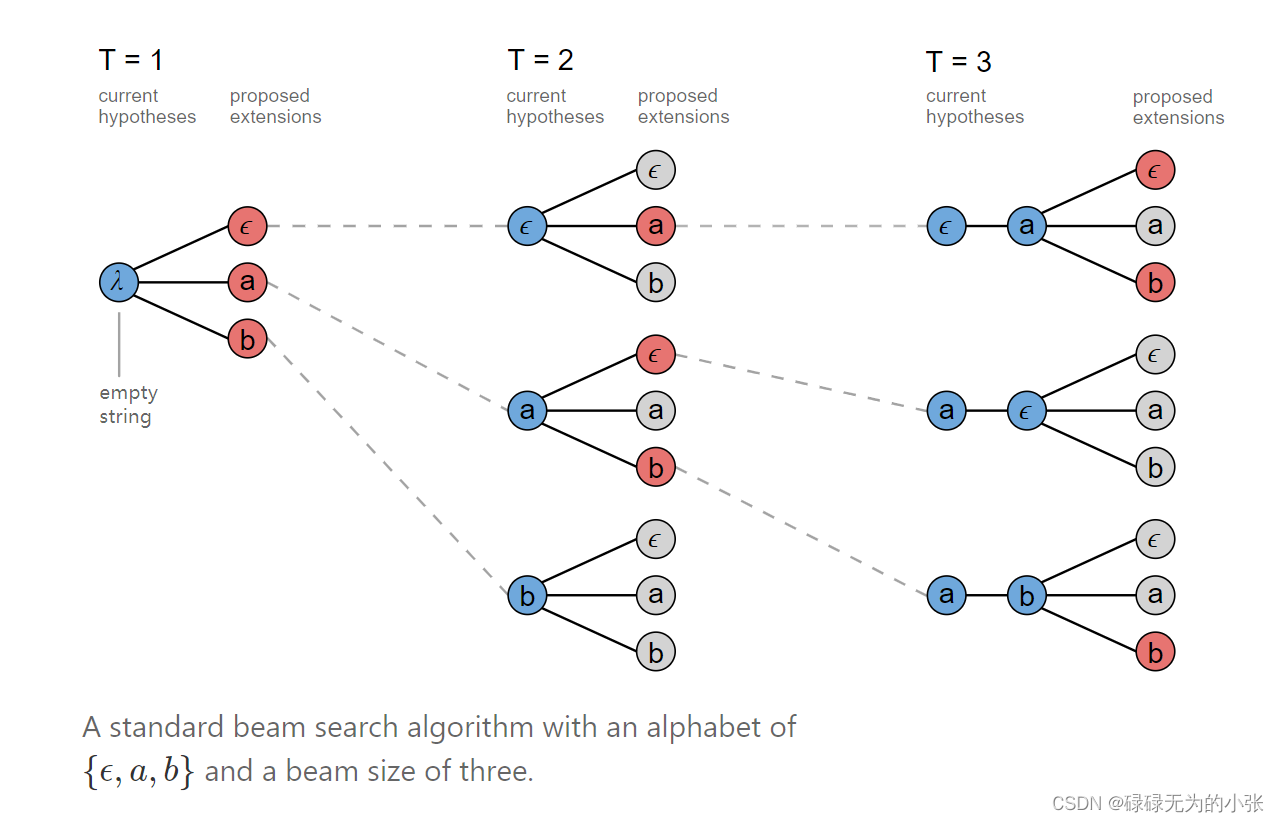
但是beam search只能找到相对最优,并不能保证找到最佳的路径。
prefix beam search
由于beam search算法并未考虑到序列等价的情况(即不同路径同一结果),会导致部分序列概率偏低。使用prefix beam search可以有效的解决这个问题。beam search是寻找每个时刻最大概率的三个序列,而prefix beam search是在每个步骤都考虑下一步所有可能的序列,并将序列和并,选取概率最高的k个序列再进行搜索,有效的缓解了beam search的缺点。具体过程见下图
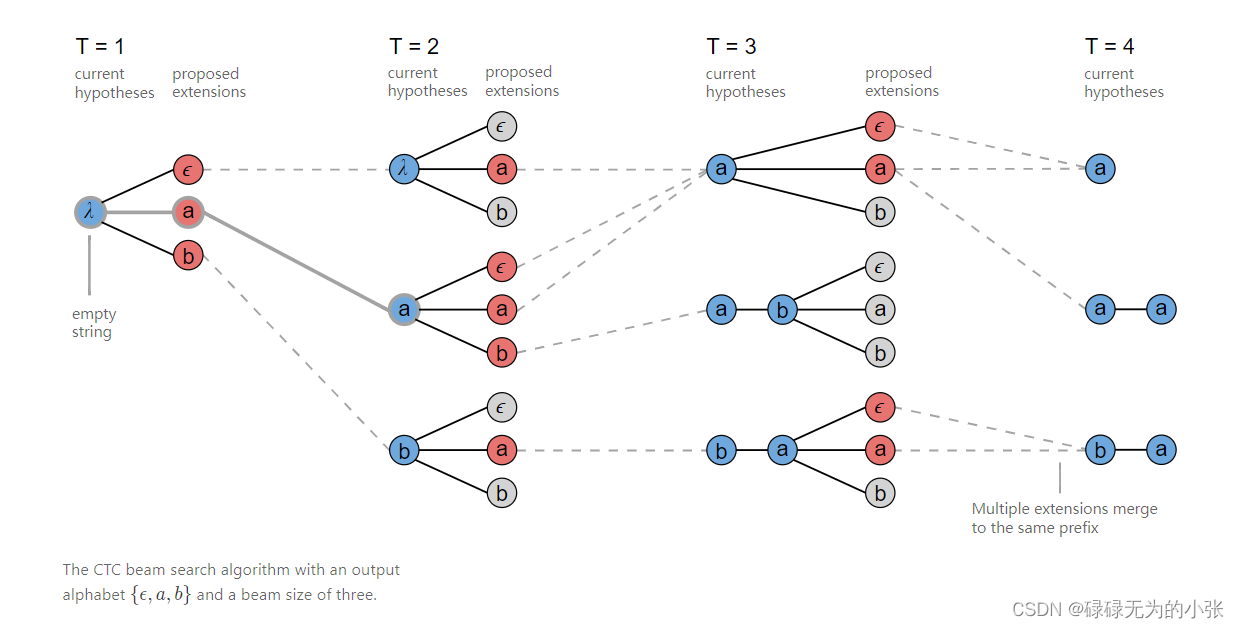
通过这个方法一般而言是可以找到最优解,但并不绝对。如果beam值够大,那么肯定是可以找到最优解的。
本文是个人的理解,若存在错误请指正。














 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









