







Word2vec算法背景
Word2Vec是一种用于自然语言处理的词嵌入技术,它是由Google的Tomas Mikolov等人在2013年提出的。它的算法思想是基于词的上下文进行学习,使语义相近的词距离更近,使词向量的表达能力更强。同时由于Word2vec模型的设计更简单,训练复杂度会更低。
Word2vec模型结构
Word2vec有俩种结构,分别是 Continuous Bag-of-Words Model(CBOW)和 Continuous Skip-gram Model。它们的思想都是学习词与其上下文之间的关系,使得词向量更具有代表性。
Continuous Bag-of-Words Model
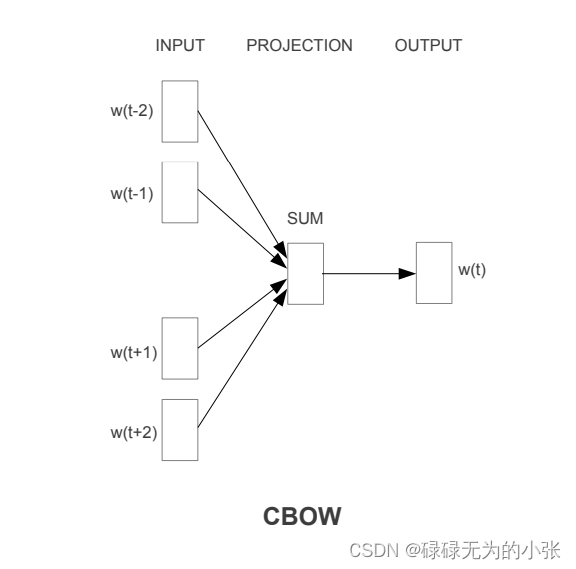
CBOW是基于中心词的上下文来预测中心词,从而学习词向量的方法。首先选择中心词
w
t
w_{t}
wt,设定上下文窗口为
R
R
R,表示离中心词的最大距离R,就可以得到中心词的上下文
[
W
t
−
R
,
W
t
−
R
+
1
,
⋯
,
W
t
−
1
,
W
t
+
1
,
⋯
,
W
t
+
R
]
[W_{t-R},W_{t-R+1},\cdots,W_{t-1},W_{t+1},\cdots,W_{t+R}]
[Wt−R,Wt−R+1,⋯,Wt−1,Wt+1,⋯,Wt+R]。然后对这些上下文的词做one-hot得到每个词的输入向量
W
(
1
×
V
)
W(1\times V)
W(1×V)。我们在对它们做一个映射,即乘一个向量矩阵
E
(
V
×
N
)
E(V\times N)
E(V×N),每个上下文的词就可以得到对应的词向量。然后将向量相加就可以得到一个上下文的表征向量,在对其做分类预测,这样就完成基于上下文预测中心词的任务。然后我们通过大批量的数据学习,就可以使模型学习到中心词和上下文之间的关系,最终我们得到的向量矩阵
E
E
E是我们所求的词向量矩阵。
Skip-gram
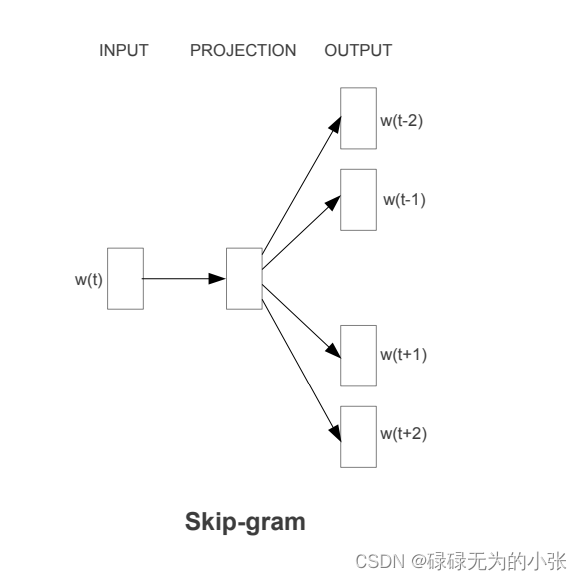
Skip-gram是通过中心词预测上下文。给定一个中心词
W
t
W_{t}
Wt,
设定上下文窗口为R,故中心词的上下文为
[
W
t
−
R
,
⋯
,
W
t
−
1
,
W
t
+
1
,
⋯
,
W
t
+
R
]
[W_{t-R},\cdots,W_{t-1},W_{t+1},\cdots,W_{t+R}]
[Wt−R,⋯,Wt−1,Wt+1,⋯,Wt+R]。对中心词做one-hot,得到输入向量
W
(
1
×
V
)
W(1\times V)
W(1×V),在做一个映射,乘上矩阵
E
(
V
×
N
)
E(V\times N)
E(V×N),得到中心词的词向量。这样就可以通过预测上下文的方式不断地训练调优向量矩阵。
同时我们可以发现一个问题,每一次的分类是在长度为 ∣ V ∣ |V| ∣V∣上做softmax,随着 ∣ V ∣ |V| ∣V∣的增大,计算也相应增大。这时如果减少 ∣ V ∣ |V| ∣V∣的长度,那么相应的算法复杂度也将下降。所以这时可以采用Negative-Sampling的方法实现我们的目的。
Negative-Sampling
Negative-Sampling就是负例采样,首先我们在词表中除去中心词和上下文词,然后从剩下的词中随机抽取 k k k个词作为负例,再与上下文词相结合,从而实现长度从 ∣ V ∣ |V| ∣V∣降至 k + 1 k+1 k+1。
举个例子,假如目标句子为“这是自然语言处理中的词向量化算法”,中心词为词,设置上文窗口为,那么上下文为 [ 的 , 向 ] [的,向] [的,向],那么我们可以随机采样“这”、“法”作为负样本,然后就可以预测在[这,的,法]、[这,向,法]的概率分布。这样可以大大降低我们的计算量。
应用
在实际应用中,我们通常使用Skip-gram算法,一方面是它在原理上更加合理,因为我们是预测与中心词更加可能的搭配。在CBOW中,通过较小的上下文窗口去预测中心词是比较难的,因为上下文窗口无法提供足够丰富的上下文,那么去预测中心词的话效果理所应当比较差。另一方面是在实际使用中,CBOW的效果是不如于Skip-gram。结合Bert算法来看的话,它的模型设计跟CBOW更加相似,但是它考虑的上下文语意是更加丰富的,模型也更加复杂。















 1634
1634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









