






Hadoop集群的搭建
1.Hadoop概述
1.1:Hadoop是什么
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 由Google三篇论文发家:
- GFS:Google的分布式文件系统,对应hadoop的Hdfs
- MapReduce分布式计算模型:Google的分布式计算模型,用于解决PageRank问题。对应hadoop的MapReduce
- BigTable:劣势存储HBase的理论基础
- 主要解决海量数据的存储和海量数据的分析计算问题
- 广义上来说,Hadoop通常是指一个更广泛的概念-----Hadoop生态圈
- Hadoop三大发行版本:
- Apache:其版本最原始(最基础),对于入门学习最好
- Cloudera:在大型互联网企业中用的较多
- Hortonworks:文档较好
1.2:Hadoop的优势
- 高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失
- 高扩展性:在集群间分配任务数据,可方遍地扩展以千计地节点
- 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理的速度
- 高容错性:能够自动将失败的任务重新分配。
1.3:Hadoop组成
- Hadoop现有版本:Hadoop1.X、Hadoop2.X、Hadoop3.X。
- Hadoop1.X:包括MapReduce负责计算和资源调度,HDFS负责数据存储,以及其他辅助工具(Common)
- Hadoop2.X:包括MapReduce负责计算,Yarn负责资源调度、HDFS负责数据存储、以及其他辅助工具 Common
- Hadoop3.X:该版本只是在2.X的版本上稍加修改,进一步提升了Hadoop的性能。
- HDFS:分布式文件存储系统
- NameNode:存储文件的元数据,如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限)、以及每个文件的块所在的DataNode等。
- DataNode:在本地文件系统存储文件块数据,以及块数据校验和。
- Secondary DataNode:用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
- Yarn:负责资源调度
- ResourceManager:处理客户端请求,监控NodeManager、启动或监控ApplicationMaster、资源的分配与调度
- NodeManager:管理单个节点上的资源、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令、资源的分配与调度
- ApplicationMaster:负责数据的切分、为应用程序申请资源并分配给内部的任务、任务的监控与容错
- Container:Container是Yarn中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等
- MapReduce:负责计算
- Map阶段:并行处理输入的数据
- Reduce阶段:对Map结果进行汇总。
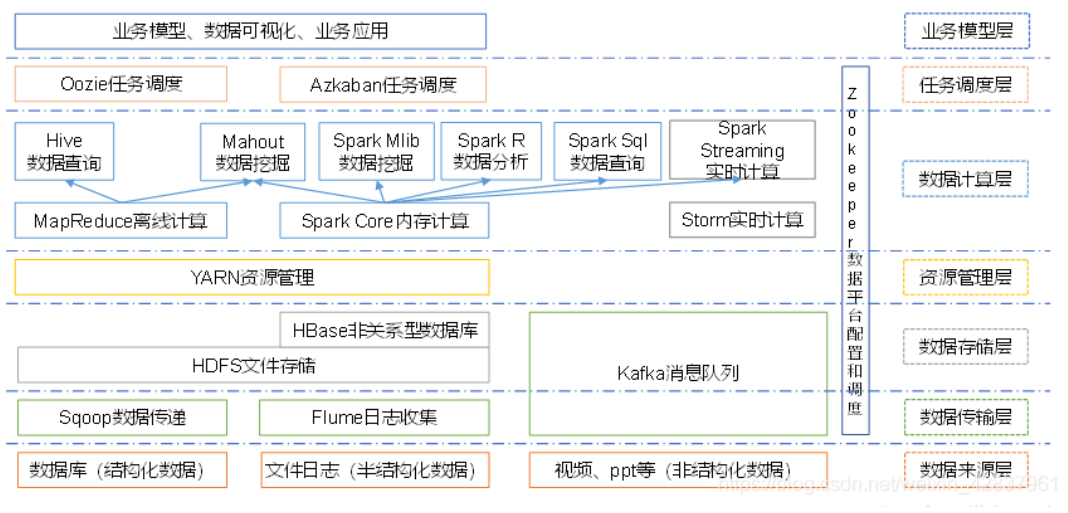
1.4:大数据生态体系结构:
2.搭建虚拟机,配置环境
2.1:所需环境
VMware、CentOS7操作系统、JDK1.8、Hadoop3.X
所需安装文件:
链接:https://pan.baidu.com/s/1ELOeWnKHMUIe0bglp46uHA
提取码:insp
快照:
链接:https://pan.baidu.com/s/1_nTGfFTQZ6EtOAnVAZLCZg
提取码:mh2o
2.2:VMware安装过程:
略(傻瓜式安装)
2.3:安装虚拟机

一直点击下一步,直至下图位置,找到对应得CentOS的映像文件(iso文件):




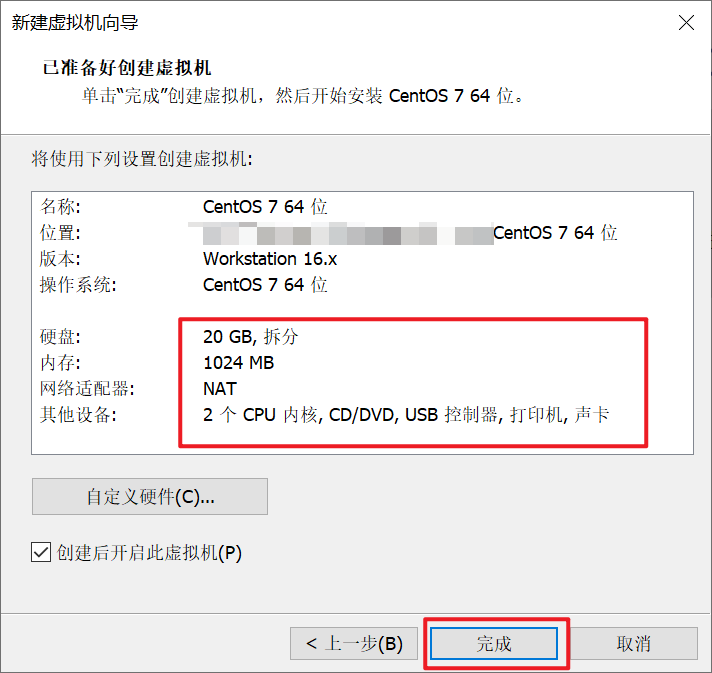
接下来一直点击下一步,直至最后,点击完成:

选择中文,点击继续:

选择安装位置,点击完成即可:


点击开始安装: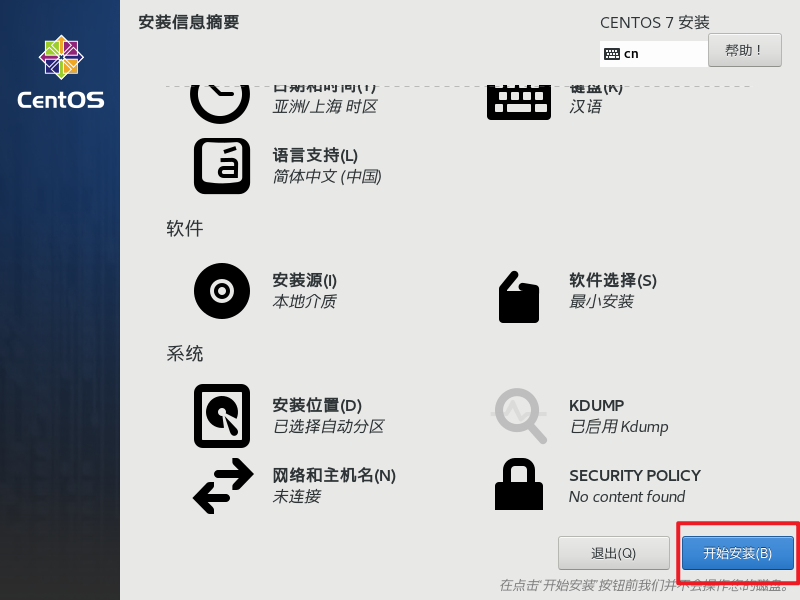
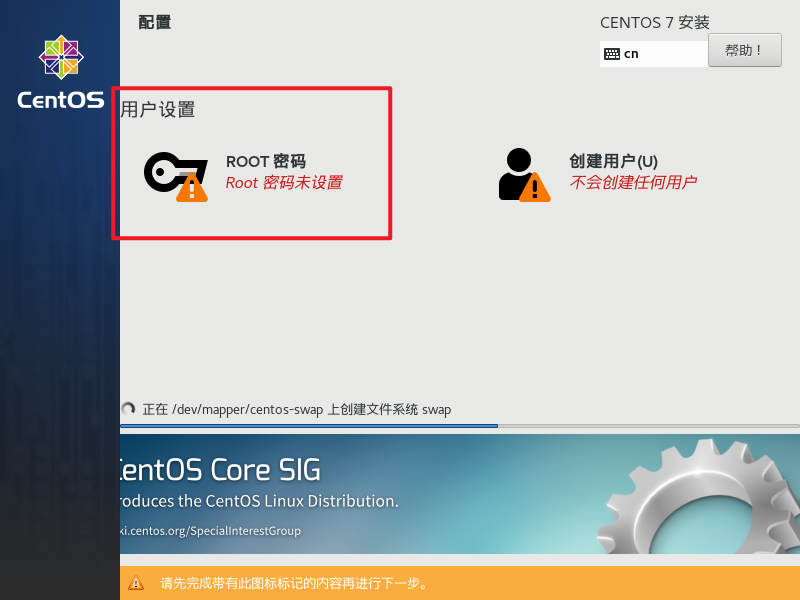
设置虚拟机密码:

点击重启即可,虚拟机安装完毕,接下来进行环境配置。
2.4:配置网卡
进入ifconfig-ens33所在的目录:
cd /etc/sysconfig/network-scripts/
# 编辑ifconfig-ens33文件
vi ifconfig-ens33

其中,配置文件中:
-
BOOTPROTO=static:表示配置静态ip;修改为静态ip后,需要添加ip地址。
-
ONBOOT=yes:是否激活网卡,激活后就可以连接到外网。
-
IPADDR=192.168…:静态IP的查看方式:




最后,配置好后需要重启网卡:
service network restart # 重启后,查看是否生效 ping www.baidu.com ping 主机ip
2.5:克隆虚拟机,搭建集群
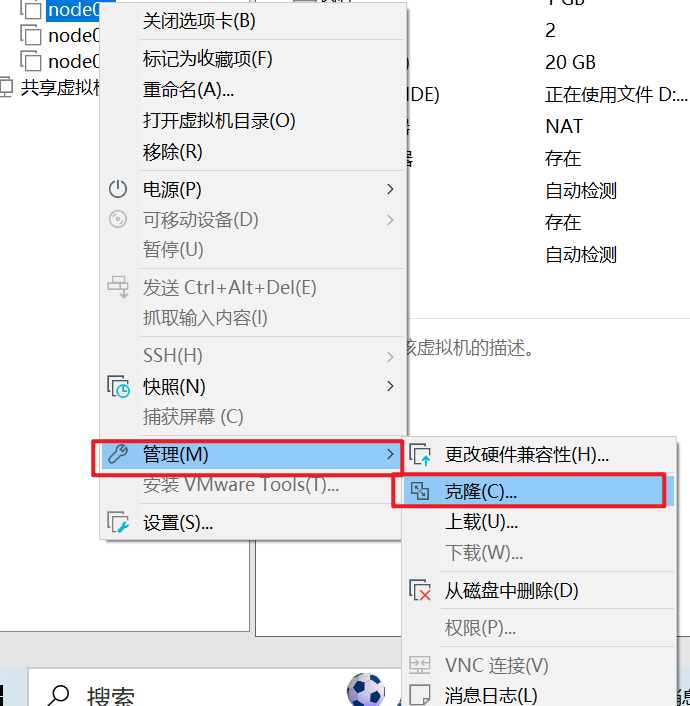



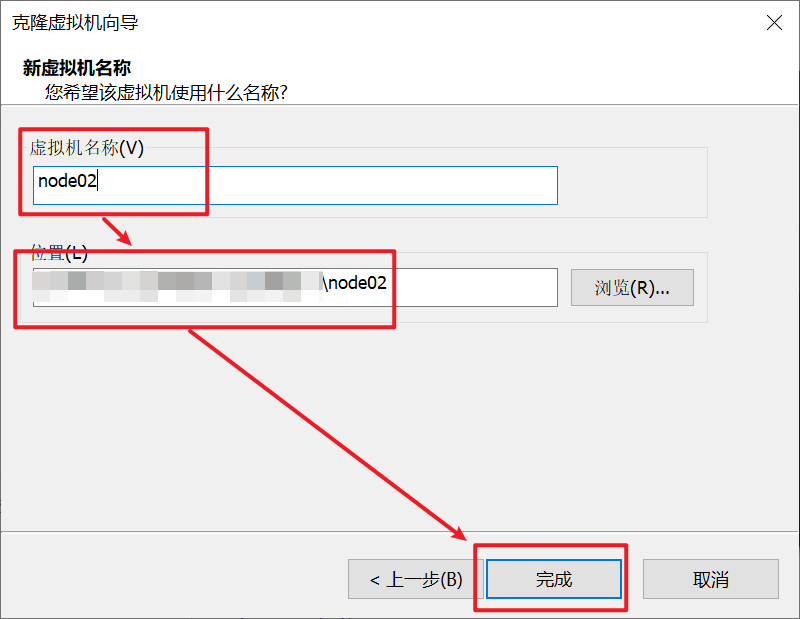
克隆好后,我们需要修改虚拟机的ip:
IPADDR=192.168.xxx.151
# 最后一个字节在原基础上加一即可,自行配置,可以任意
# 配置好后重启网卡
service network restart
# 测试是否生效
ping www.baidu.com
ping ip
再次克隆,步骤同上,此时我们拥有三台虚拟机,但这三台都是独立的个体,并不是集群!接下来进行集群配置。
3.搭建集群
在搭建集群之前,由于我们没有在CentOS上安装可视化桌面,所以我们可以通过其他可视化桌面工具连接到虚拟机,此处我们使用MobaXterm工具。其他工具包括finalshell等都可以。
3.1:通过MobaXterm连接虚拟机
- 安装MobaXterm过程:略
- 连接虚拟机过程:


- 其他两台虚拟机操作过程同上,连接上虚拟机之后,输入用户名登录即可,第一次登录可能需要输入密码。

3.2:配置主机名映射以及主机名:
vi /etc/hosts
# 进入目录之后,添加IP地址
192.168.xxx.xxx node01
192.168.xxx.xxx node02
192.168.xxx.xxx node03
# 配置主机名
vi /etc/hostname
# 修改完后,重启虚拟机
reboot
主机名映射(hosts)


主机名(hostname)
其他两台虚拟机依次操作。
3.3:创建hadoop用户:
创建hadoop用户
useradd hadoop
passwd hadoop

使hadoop用户具有root权限,方便以后执行具有root权限的命令
vi /etc/sudoers
# 在root ALL=(ALL) ALL下加入一条命令(也可以在%wheel ALL+(ALL) ALL下添加)
hadoop ALL=(ALL) NOPASSWD:ALL

3.4:创建文件存放目录,并赋予权限
# JDK等编译插件存放位置:/opt/moudle
mkdir /opt/moudle
# hadoop等软件存放位置:/opt/software
mkdir /opt/software
# 修改两个文件加的所有者和所属组均为hadoop用户
chown hadoop:hadoop /opt/moudle
chown hadoop:hodoop /opt/software
# 查看是否具有权限
ll

其他两台虚拟机依此操作!
操作完成后,重启三台虚拟机!
配置好后,就可以来回切换用户,接下来如没有特别提示,我们都在hadoop用户下操作!
【注】
3.5:配置免密登录(配置SSH):
-
在第一次使用ssh时,会没有.ssh目录,我们需要在root用户下先执行:
ssh localhost # 按提示输入对应内容即可

-
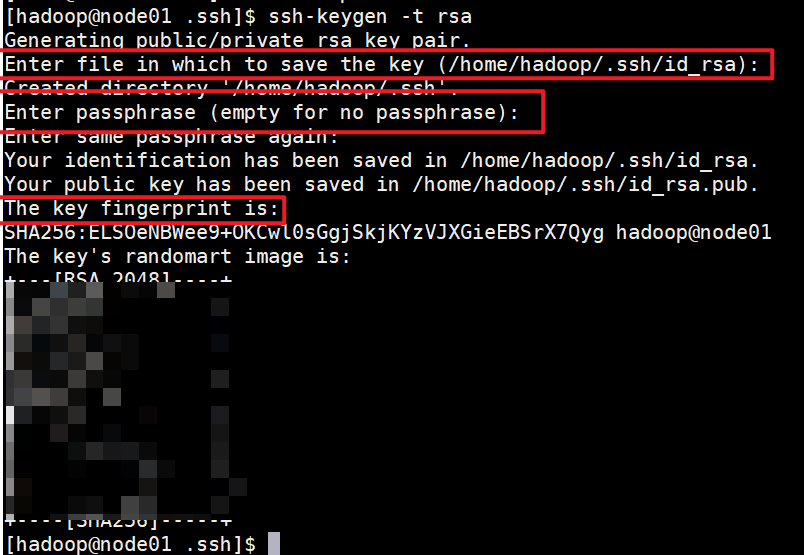
生成公钥和私钥:
首先进入hadoop用户下的.ssh文件夹:
su hadoop
生成公钥和私钥:
ssh-keygen -t rsa # 之后连续回车三次即可生成两个文件:id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到其他机器:
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
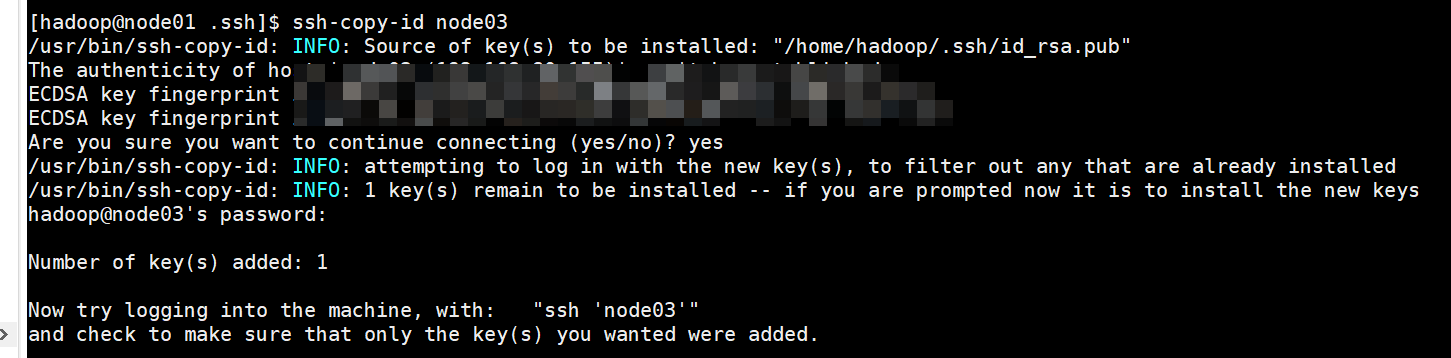

【注】其他两台机器的hadoop用户以及node01用户也要上述操作!
至此,三台虚拟机可以任意无密匙切换!
4.安装JDK
-
下载JDK:略
-
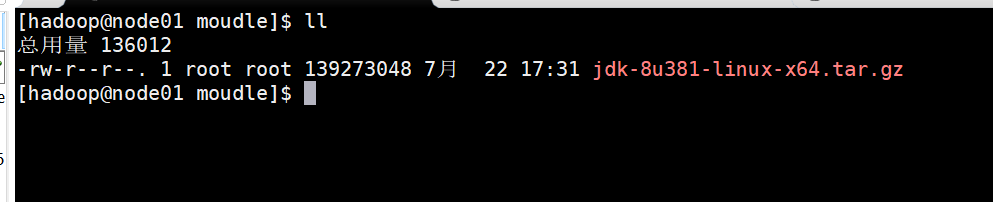
安装JDK:将下载的JDK拷贝到/opt/moudle目录下:
如何将windows中的文件拖入虚拟机:
- 直接拖入到对应文件夹下即可;

-
解压JDK:
tar -zxvf jdk-8u381-linux-x64.tar.gz
删除压缩包,节约空间
rm -rf jdk-8u381-linux-x64.tar.gz -
安装Vim(可跳过,但是不安装就只能适用vi操作,不能使用vim):
为了方便我们使用,下载一个vim编辑器,旨在使得我们编写脚本文件或者其他配置时便于观察。

# 检查是否安装过vim,只要没有上述三个包中的一个,就需要重新安装vim rpm -qa|grep vim # 安装vim(切换会root用户下执行) yum -y install vim* -
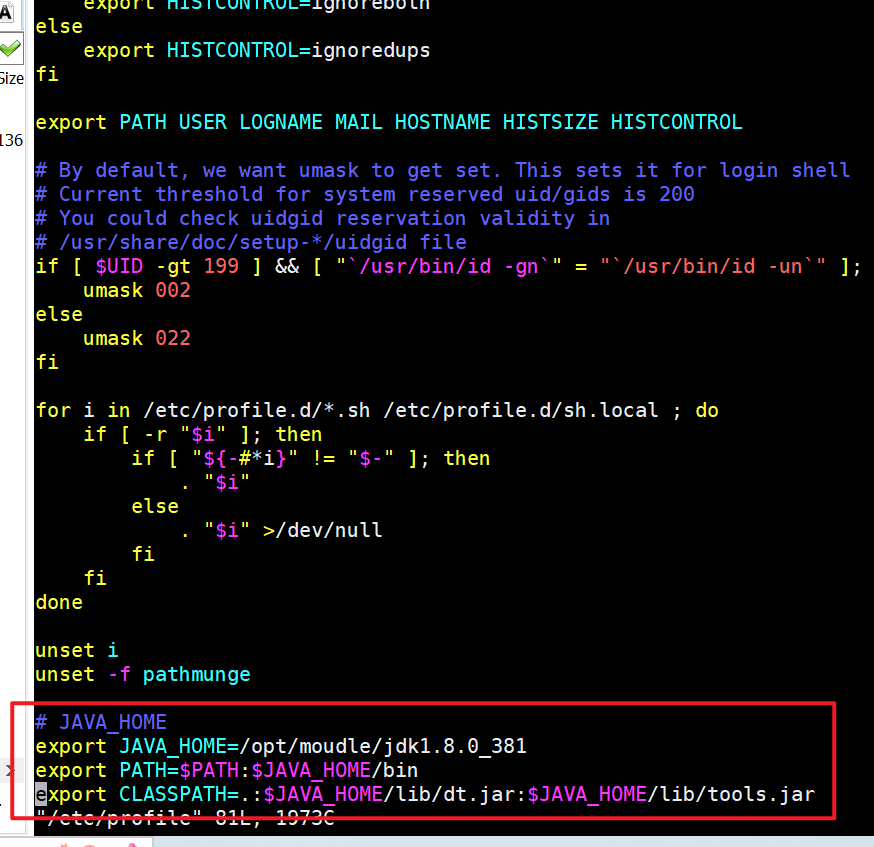
配置JDK的环境变量:
# 进入/etc/profile文件 sudo vim /etc/profile # 在文件最后一行加入JAVA_HOME(使用自己的JDK安装路径)# JAVA_HOME export JAVA_HOME=/opt/moudle/jdk1.8.0_381 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
-
查看是否安装成功:

-
将安装好的JDK在其他两台上也需要进行同样的操作步骤,但是,以后我们使用scp命令进行远程拷贝
# 将node01中的JDK安装文件发送到其他两台虚拟机 scp -r /opt/moudle/jdk1.8.0_381/ hadoop@node02:/opt/moudle/ scp -r /opt/moudle/jdk1.8.0_381/ hadoop@node03:/opt/moudle/ # 将node01中的JDK配置文件发送到其他两台虚拟机 scp /etc/profile root@node02:/etc scp /etc/profile root@node03:/etc # 最后在另外两台虚拟机上执行source,使配置文件生效 source /etc/profile # 使用java -version命令查看配置配置文件是否生效 java -version

5.安装Hadoop(搭建Hadoop集群环境)
5.1:下载Hadoop
官方下载地址:Index of /dist/hadoop/common (apache.org)
清华大学镜像下载地址:Index of /apache/hadoop/common/hadoop-3.3.1 (tsinghua.edu.cn)
5.2:安装Hadoop
-
将下载的安装包复制到虚拟机(/etc/moudle):

-
解压安装hadoop:
tar -zxvf hadoop-3.3.1.tar.gz # 删除安装包 rm -rf hadoop-3.3.1.tar.gz # 重命名 mv hadoop-3.3.1/ hadoop
5.3:配置环境变量:
# 进入/etc/profile文件
vim /etc/profile
# 添加下述配置文件
# HADOOP_HOME
export HADOOP_HOME=/opt/moudle/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin

5.4:配置集群:
【重点】能不手写就不要手写,能复制就复制,手写出错后果自负
-
各个节点的分布情况:
node01 node02 node03 HDFS NameNode、DataNode DataNode SecondaryNameNode、DataNode YARN ResourceManager、NodeManager NodeManager NodeManager -
配置hadoop-env.sh文件:
# 进入hadoop-env.sh文件 vim /opt/moudle/hadoop/etc/hadoop/hadoop-env.sh # 在文件最后一行添加配置文件 export JAVA_HOME=/opt/moudle/jdk1.8.0_381 export HDFS_NAMENODE_USER=hadoop export HDFS_DATANODE_USER=hadoop export HDFS_SECONDARYNAMENODE_USER=hadoop export YARN_RESOURCEMANAGER_USER=hadoop export YARN_NODEMANAGER_USER=hadoop

-
配置core-site.xml文件:
# 进入core-site.sh文件 vim /opt/moudle/hadoop/etc/hadoop/core-site.sh # 在configuration标签中添加文件<!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://node01:9000</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/moudle/hadoop/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为hadoop --> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property>

【注】此处需要在Hadoop目录下创建一个data目录,用于存储hadoop数据
mkdir data
chmod 777 ./data/
-
配置hdfs-site.xml配置文件:
# 进入hdfs-site.sh文件 vim /opt/moudle/hadoop/etc/hadoop/hdfs-site.sh # 在configuration标签中添加文件<!-- NameNode web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>node01:9870</value> </property> <!-- SecondaryNameNode web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>node03:9868</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property>

-
配置yarn-site.xml配置文件:
# 进入yarn-site.sh文件 vim /opt/moudle/hadoop/etc/hadoop/yarn-site.sh # 在configuration中添加下述文件<!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>node01</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </peoperty> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!--设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node01:19888/jobhistiry/logs</value> </property> <!--历史日志保存时间 7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
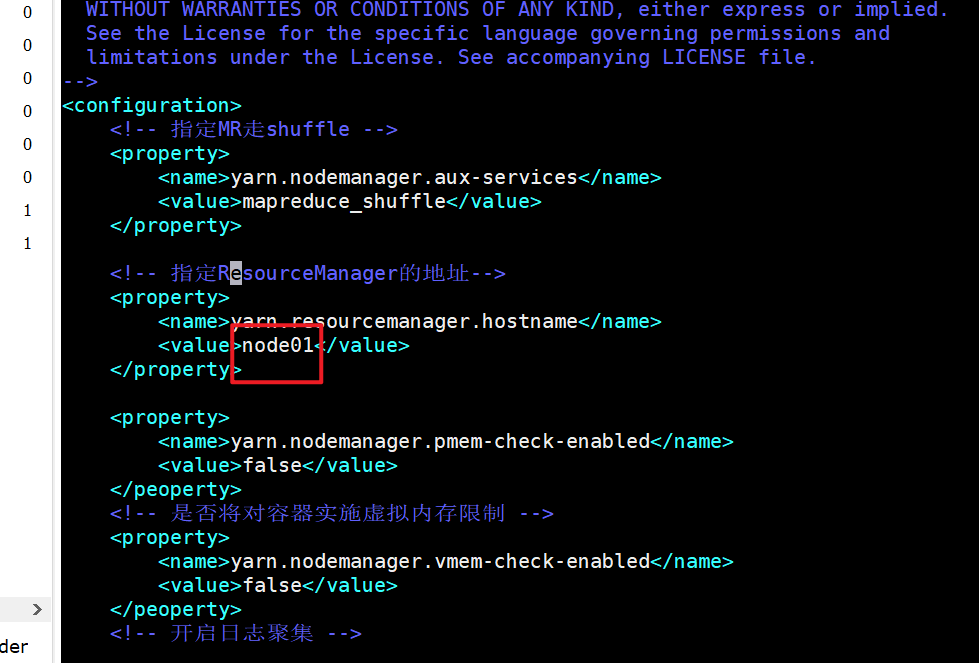
【注】此处需要在hadoop目录下创建logs文件夹,用于存放日志文件:
mkdir logs
chmod 777 ./logs/
-
配置mapred-site.xml:
# 进入mapred-site.sh文件 vim /opt/moudle/hadoop/etc/hadoop/mapred-site.sh # 在configuration中加入下述文件<!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 指定MapReduce程序历史服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node01:10020</value> </property> <!-- 指定MapReduce程序历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node01:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>

-
修改works(有的是slaves)文件:
# 进入works文件: vim /opt/moudle/hadoop/etc/hadoop/works # 在文件中修改成自己的虚拟机名称,配几台虚拟机就写几台虚拟机名 node01 node02 node03
-

-
将hadoop分发到其他两台虚拟机:
scp -r /opt/moudle/hadoop hadoop@node02:/opt/moudle/ scp -r /opt/moudle/hadoop hadoop@node03:/opt/moudle/ # !!!注意!!!,之前配置过的profile也需要重新分法 scp /etc/profile root@node02:/etc/ scp /etc/profile root@node03:/etc/ -
首次启动hadoop前,需要格式化namenode节点,只需要启动一次,启动多次自行重新安装!!!,建议在格式化之前先将虚拟机快照备份:
hdfs namenode -format
-
不小心多次格式化namenode节点
[答]:删除所有虚拟机下hadoop目录下的data文件夹中内容以及logs文件夹中的内容,然后重新格式化就行。
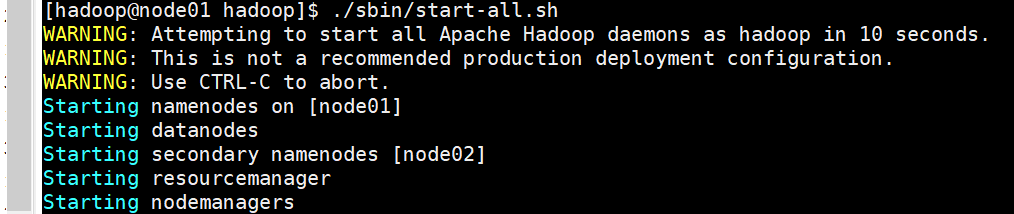
5.5:启动集群:
# 启动hdfs,先进入hadoop目录下的sbin目录
./sbin/start-dfs.sh
# 启动yarn,先进入hadoop目录下的sbin目录
./sbin/start-yarn.sh
# 还可以选择同时启动hdfs和yarn
./sbin/start-all.sh
# 查看是否启动
jps



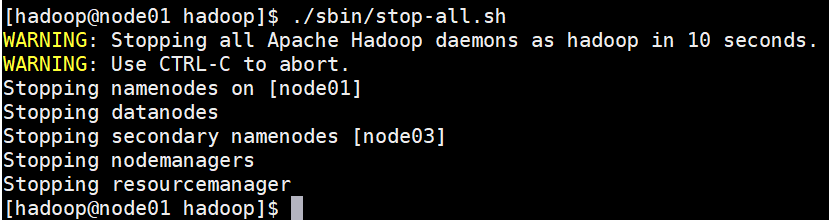
5.6:停止集群:
# 命令基本同上,只是将上述start换成stop
./sbin/stop-dfs.sh
./sbin/stop-yarn.sh
./sbin/start-all.sh
6.遇到的问题
6.1:警告问题
【注】目前尚未解决,请各位集思广益,提供解决方案!!!
















 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









