






搭建Spark集群
1、概念:
静待后续
2、实验所需要环境:
VMware虚拟机、CentOS7操作系统、JDK1.8、搭建好的Hadoop集群
如果没有搭建好Hadoop集群,可以点击查看之前的文章进行安装:http://t.csdn.cn/kI2B2
2.1:本实验中所需安装软件:
- scala-2.12.15.tgz
- spark-3.2.4-bin-hadoop3.2.tgz
- sbt-1.9.4.tgz
链接:https://pan.baidu.com/s/1OGyoZE2ylEd-JnHE4C0hww
提取码:kd0t
3、安装Scala:
-
官网:https://www.scala-lang.org/download/2.12.15.html

-
将下载下来的压缩包上传到虚拟机上并解压到指定目录:
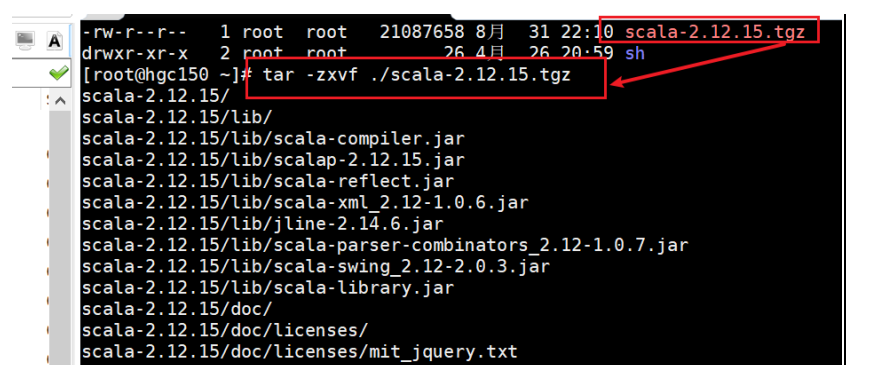
# 解压到指定路径 tar -zxvf ./scala-z.12.15.tgz -C 指定路径 # 修改文件夹名字 mv ./scala-2.12.15 scala
-
配置环境变量:
# 进入profile文件 vim /etc/profile # 在配置文件中添加下述路径(scala的路径一定要改成自己的路径)# SCALA_HOME export SCALA_HOME=/opt/moudle/scala export PATH=$PATH:$SCALA_HOME/bin
# 使修改后的配置文件生效 source /etc/profile -
查看Scala是否安装成功:
# 进入Scala的客户端界面(任意路径下输入scala即可) scala
-
注意:Scala编程需要依靠JDK,所以必须先安装好JDK后才能使用Scala。
-
将Scala远程发送到其他两台虚拟机:
scp -r ./scala hadoop@node02:/opt/moudle/ scp -r ./scala hadoop@node03:/opt/moudle/

-
将配置文件发送到其他两台虚拟机并生效配置:
scp /etc/profile hadoop@node02:/etc/profile scp /etc/profile hadoop@node03:/etc/profile # 生效配置 source /etc/profile -
Scala编程指令:略
4、安装Spark:
4.1:下载Spark:
- 官网:https://spark.apache.org/downloads.html
- 清华镜像:https://mirrors.tuna.tsinghua.edu.cn/apache/spark/
- 下载注意事项:下载的Spark版本需要和自己安装的Hadoop版本对应,否则会影响后续使用。

4.2:将下载好的Spark上传到虚拟机并解压:
-
# 进入/opt/moudle/目录下 cd /opt/moudle/ # 解压压缩包 tar -zxvf ./spark-3.2.4-bin-hadoop3.2.tgz # 修改文件夹名字 mv ./spark-3.2.4-bin-hadoop3.2 spark # 删除压缩包,节省空间 rm -rf ./spark-3.2.4-bin-hadoop3.2.tgz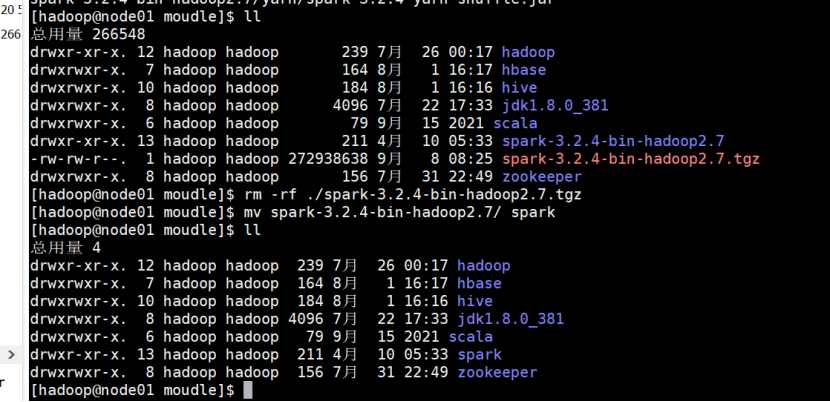
4.3:修改Spark的相关配置文件:
-
# 进入spark的conf目录 cd spark/conf # 对其中的三个文件进行重命名(spark-env.sh.template、spark-defaults.conf.template、workers.template) mv spark-env.sh.template spark-env.sh mv spark-defaults.conf.template spark-defaults.conf # mv workers.template works (错误配置,要改为slaves,否则可能不能群起,Worker节点只能单独启动,切记!!) # 下面图片有误(!!!找了一晚上!!!) mv workers.template slaves
-
修改spark-env.sh(注意有坑):
# 指明Java路径,不加可能Worker节点包启动不了(JAVA_HOME is not set) JAVA_HOME=/opt/moudle/jdk1.8.0_381 # 指明scala路径 SCALA_HOME=/opt/moudle/scala # Spark主节点所在IP SPARK_MASTER_HOST=192.168.80.153 SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=10002 # Spark的Worker最大内存 SPARK_WORKER_MEMORY=1G # Spark的Worker的端口号 SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=10003 # Saprk日志存放路径,没有需要创建 SPARK_LOG_DIR=/opt/moudle/spark/logs # 找到hadoop指定路径(作用:加上后,Spark可以在HDFS上读取文件,不加就只能读取本地文件) SPARK_DIST_CLASSPATH=$(/opt/moudle/hadoop/bin/hadoop classpath) # 找到hadoop配置地址 HADOOP_CONF_DIR=/opt/moudle/hadoop/etc/hadoop # 指定Spark的历史服务器的Java环境变量。(设置端口号为18080,在hdfs上创建了一个spark_historu_log文件夹来存储历史记录,自动清除)(!!!此处配置hdfs的端口号不是web界面的端口号,是指hdfs的NameNode地址的端口号,查看方式:hdfs getconf -confKey fs.default.name) SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=5 -Dspark.history.fs.logDirectory=hdfs://node01:9000/spark_history_log -Dspark.history.fs.cleaner.enabled=true"
【注】需要在HDFS上创建一个spark_history_log文件夹。
# 启动hdfs /opt/moudle/hadoop/sbin/start-dfs.sh # 创建文件 hadoop fs -mkdir /spark_history_log
-
修改spark-defaults.conf:
# 配置事件日志功能(是否开启,存储位置,是否压缩日志文件,此处hdfs端口号同上) spark.eventLog.enabled true spark.eventLog.dir hdfs://node01:9000/spark_history_log spark.eventLog.compress true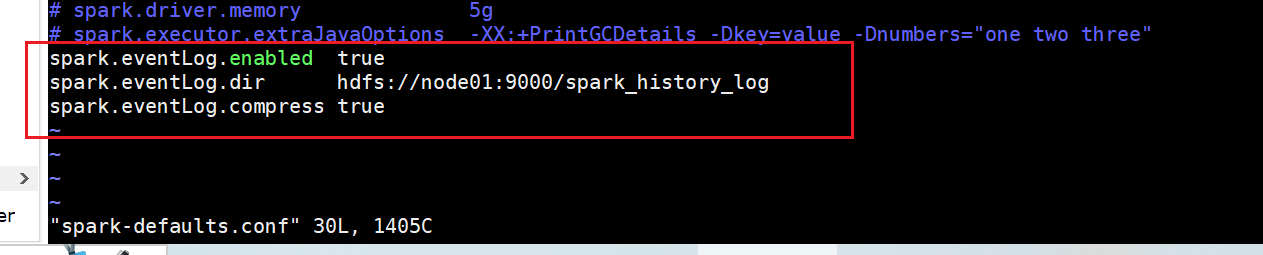
-
配置slaves:
node01 node02 node03
-
配置SPARK_HOME:
# 进入/etc/profile文件 sudo vim /etc/profile # 添加Spark路径# SPARK_HOME export SPARK_HOME=/opt/moudle/spark export PATH=$PATH:$SPARK_HOME/sbin:$SPARK_HOME/bin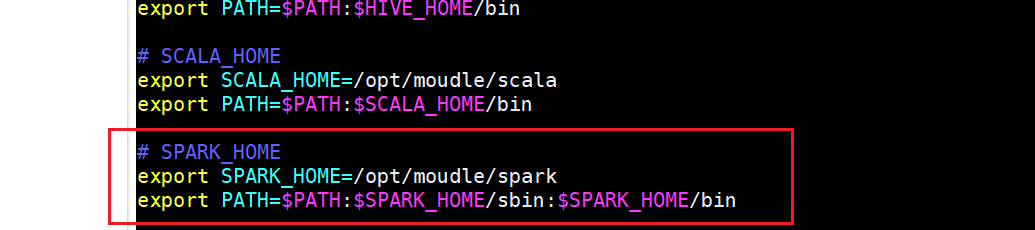
# 使配置文件生效 source /etc/profile
4.4:搭建集群:
-
将profile配置文件发送到其他两台虚拟机,覆盖原文件:
scp /etc/profile root@node02:/etc/profile scp /etc/profile root@node03:/etc/profile
# 在两台虚拟机上使配置文件生效 source /etc/profile -
将Spark发送到其他两台虚拟机:
scp -r ./spark hadoop@node02:/opt/moudle/ scp -r ./spark hadoop@node03:/opt/moudle/

4.5:启动Spark集群:
-
首先启动Hadoop:
# 进入hadoop目录 cd /opt/moudle/hadoop # 启动Hadoop集群 ./sbin/start-all.sh # 查看是否启动 jps
-
启动Spark集群:
# 在主节点上启动即可 # 进入spark目录 cd /opt/moudle/spark # 先启动master节点 ./sbin/start-master.sh # 在启动Worker节点 ./sbin/start-workers.sh ########################################################## # 还可以直接启动集群 ./sbin/start-all.sh # 查看是否正常启动 jps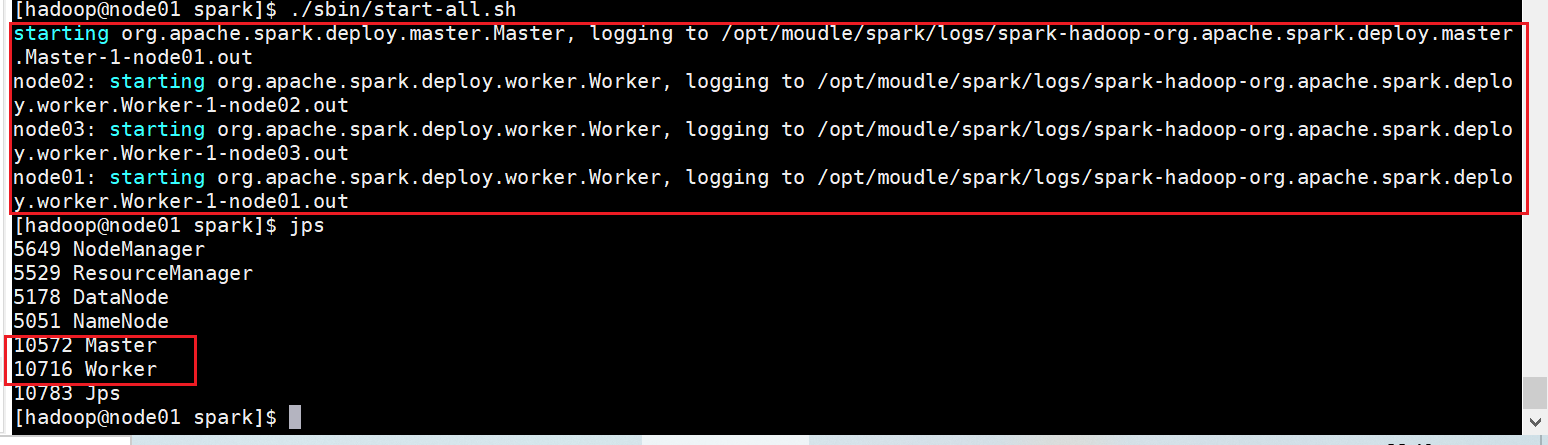
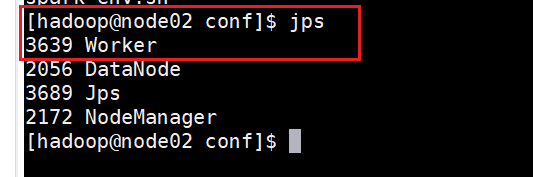

-
在Web界面上查看:
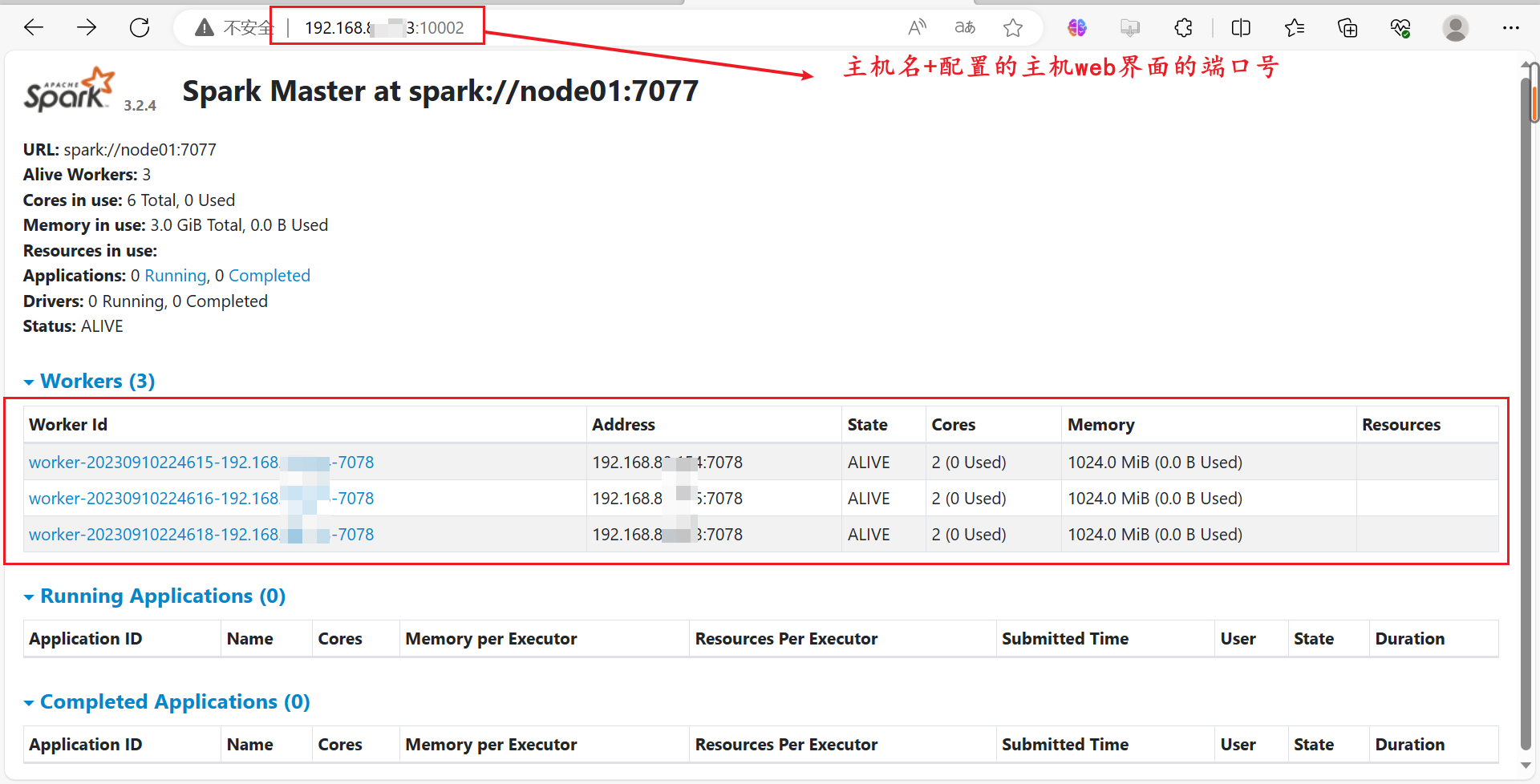
4.6:关闭集群
./sbin/stop-all.sh

5、在集群上运行Spark应用程序:
- Spark集群部署包括4种方式:
- Standalone部署模式
- Spark on YARN部署模式
- Spark on Mesos部署模式
- Spark on Kubernets部署模式
- 此处先采用Stanalone部署模式
5、1:启动集群:
cd /opt/moudle/spark
./sbin/start-all.sh
5.2:在集群种运行应用程序JAR包:
# 进入spark目录
cd /opt/moudle/spark
# 运行Spark自带的样例程序SparkPi
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node01:7077 examples/jars/spark-examples_2.12-3.2.0.jar 100 2>&1 | grep "Pi is roughly"
5.3:在集群中运行Spark-shell
-
# 进入spark目录 cd /opt/moudle/spark # 进入shell界面 ./bin/spark-shell # 或者(指定主节点位置) ./bin/spark-shell -master spark://node01:7077
-
运行hdfs上的文件:
-
先创建一个文件(README.md):
Hello Scala Hello Spark Hello World -
将文件上传到hdfs
hadoop fs -put ./README.md /user/hadoop # /user/hadoop这两个目录没有需要先创建 hadoop fs -mkdir -p /user/hadoop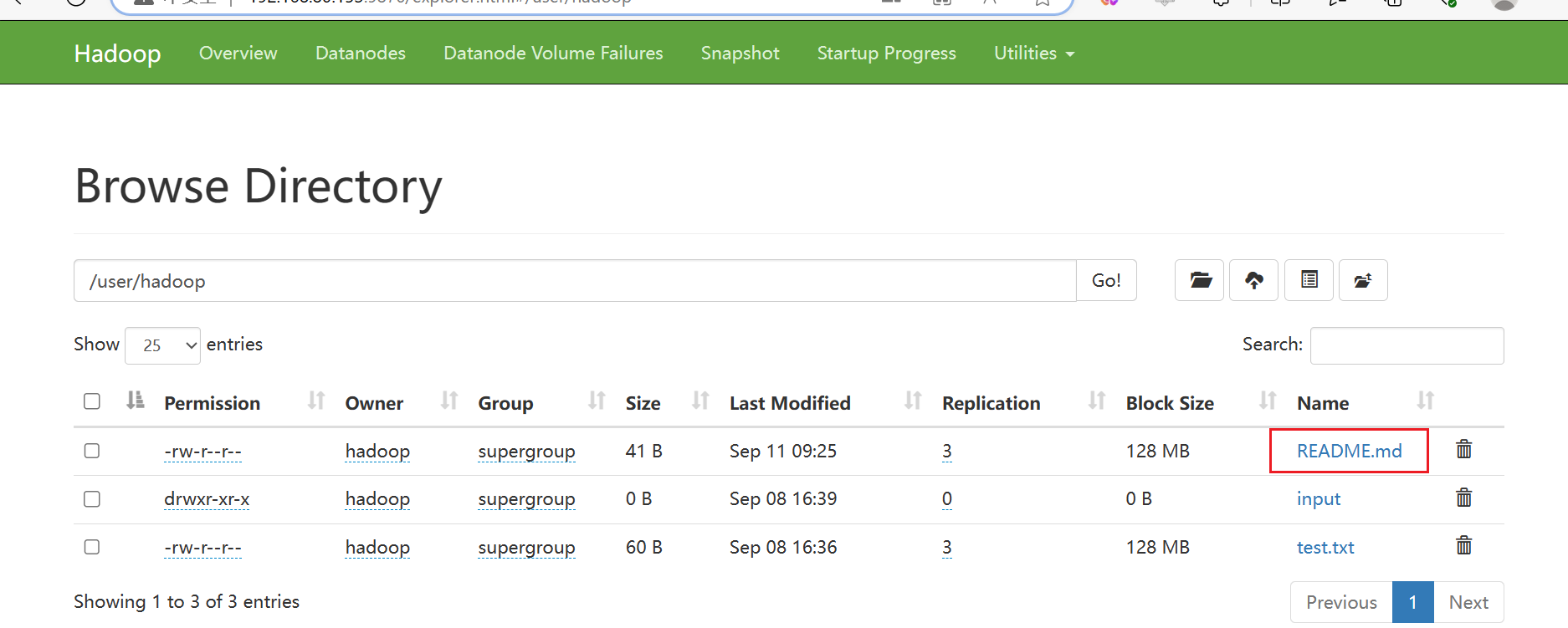
-
在shell界面编写指令:
val textFile = sc.textFile("hdfs://node01:9000/user/hadoop/README.md")
textFile.count()
textFile.first()
-

-
6、安装Sbt:
6.1:概念:
- SBT是 Scala 的构建工具,全称是 Simple Build Tool, 类似 Maven 或 Gradle。可以将一个scala文件打成jar包。
6.2:下载Sbt:

6.3:将下载好的压缩包上传到虚拟机上并解压:

6.4:修改配置:
-
修改profile配置:
# 进入profile界面 vim /etc/profile # 添加路径: # SBT_HOME export SBT_HOME=/opt/moudle/sbt export PATH=$PATH:$SBT_HOME/bin
# 生效环境变量 source /etc/profile -
进入/sbt/conf/sbtopts界面:
vim /opt/moudle/sbt/conf/sbtopts # 在文件最后一行加上这句话(当设置为true时,sbt将会忽略默认的构建仓库,而使用自定义的仓库。这可以用于在构建过程中使用私有或本地的仓库,而不是默认的公共仓库。) -Dsbt.override.build.repos=true
-
设置国内仓库(阿里云):
默认情况下,sbt使用的是国外的仓库地址,打包编译的时候慢的一匹(无法忍受),为了加快打包编译速度,建议更换仓库地址。
# 在~/.sbt下创建repositories文件 cd ~/.sbt vim repositories # 添加如下指令:[repositories] aliyun-maven-repo: https://maven.aliyun.com/repository/public aliyun-nexus: https://maven.aliyun.com/nexus/content/groups/public/ typesafe: https://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly maven-central sonatype-oss-releases sonatype-oss-snapshots ivy-sbt-plugin: https://dl.bintray.com/sbt/sbt-plugin-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext]
-
运行sbt:
sbt sbtVersion # 出现版本号即成功,第一次可能比较慢
-
sbt有关实验,静待后续!!!
















 3967
3967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









