






urllib.request模块
请求方式
- GET 特点 :查询参数在URL地址中显示
- POST
- 在Request方法中添加data参数 urllib.request.Request(url,data=data,headers=headers)
- data :表单数据以bytes类型提交,不能是str
常用的方法
- urllib.request.urlopen(“网址”) 作用 :向网站发起一个请求并获取响应
- 字节流 = response.read()
- 字符串 = response.read().decode(“utf-8”)
- urllib.request.Request(“网址”,headers=“字典”)
- urlopen()不支持重构User-Agent
- urlretrieve(url, filename=None, reporthook=None, data=None)直接将远程数据下载到本地
响应对象
• read() 读取服务器响应的内容
• getcode() 返回HTTP的响应码
• geturl() 返回实际数据的URL(防止重定向问题)
urllib的使用
方法一
- 1.获取URL
- 2.在网页中鼠标右键—》检查—》选择Network—》刷新页面—》选择第一段—》在Headers下找到Uer-Agent—》复制整个内容
- 3.利用urllib.request.urlopen(‘网址’)发起请求
- 4.response.read(),获取HTML代码,有时候获取到的源码可能出现乱码,这时候要用到代码解析,即response.read().encode(‘utf-8’)
- 5.解析HTML源码(后面讲)



方法二,urllib.request.Request(URL, user-agent)

urllib.parse模块
浏览器中看到URL有中文,但复制出来中文会是十六进制,但程序不会,为避免程序的错误,urllib.parse模块可将中文转换成十六进制。
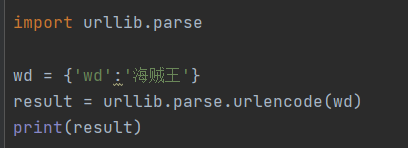
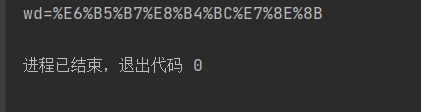
方法一:urllib.parse.urlencode(字典)
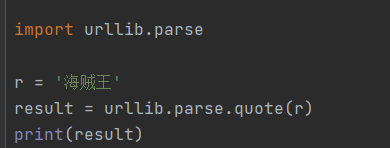
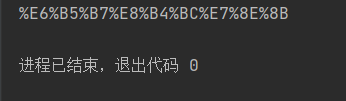
方法二:urllib.parse.quote(字符串)
扩展
有时候,网站中也会出现一堆十六进制的代码,这时候用到urllib.parse.unquote(url)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









