






1、什么是高可用、keepalived
高可用(High Availability)是指系统或应用程序在出现故障或故障的部分组件失效时,仍能够保持正常运行,并且能够在最短时间内恢复到正常运行状态。高可用性是保证系统或应用程序持续稳定运行的重要因素,它可以提高系统的可靠性、稳定性和可用性,减少系统故障对业务的影响。常见的高可用技术包括负载均衡、故障转移、冗余备份等。
keepalived:
官方网站:https://keepalived.org/
Keepalived是一个用C语言编写的路由软件。该项目的主要目标是为Linux系统和基于Linux的基础设施提供简单而强大的负载平衡和高可用性设施。负载平衡框架依赖于众所周知的和广泛使用的Linux虚拟服务器(IPVS)内核模块提供第4层负载平衡。Keepalived实现了一组检查器,可以根据负载均衡服务器池的运行状况动态地、自适应地维护和管理它们。。另一方面,高可用性是通过VRRP协议来实现的。VRRP是路由器故障转移的基础砖。此外,Keepalived实现了一组到VRRP有限状态机的钩子,提供低级和高速协议交互。为了提供最快的网络故障检测,Keepalived实现了BFD协议。VRRP状态转换可以考虑BFD提示以驱动快速状态转换。 Keepalived框架可以单独使用,也可以一起使用,以提供弹性基础设施。
2、VRRP协议
VRRP(Virtual Router Redundancy Protocol):虚拟路由器冗余协议
它允许多个路由器共同承担一个虚拟路由器的IP地址,其中一个路由器被选为活动路由器,其他路由器则作为备用路由器。如果活动路由器故障或离线,备用路由器会自动接管虚拟路由器的IP地址,确保网络的连通性和可用性。
VRRP协议通过在网络中的路由器之间交换VRRP协议报文来实现路由器冗余。这些报文包含有关活动路由器和备用路由器的信息,以及虚拟路由器的IP地址和优先级等。通过VRRP协议,网络设备可以实现快速的故障恢复和无缝的路由器切换,从而提高网络的可用性和可靠性。
工作原理:
1、路由器选举:在VRRP中,多个路由器可以组成一个虚拟路由器组(VRG)。其中一个路由器被选举为虚拟路由器(VR)并负责发送虚拟IP地址,其他路由器则作为备份。
2、虚拟IP地址:虚拟路由器(VR)负责发送虚拟IP地址,该地址是VRG的默认网关地址。当客户端发送数据包时,它们将使用该地址作为目标地址。
3、选举过程:在VRRP中,路由器之间通过发送VRRP消息进行通信。每个路由器都会发送一个优先级值,具有最高优先级的路由器将成为虚拟路由器(VR)。如果虚拟路由器(VR)失效,则备份路由器将接管并发送虚拟IP地址。
4、心跳检测:VRRP路由器之间会定期发送心跳消息以确保它们仍然处于活动状态。如果某个路由器在一定时间内没有发送心跳消息,则其他路由器将认为该路由器已经失效,并将选举一个新的虚拟路由器(VR)。
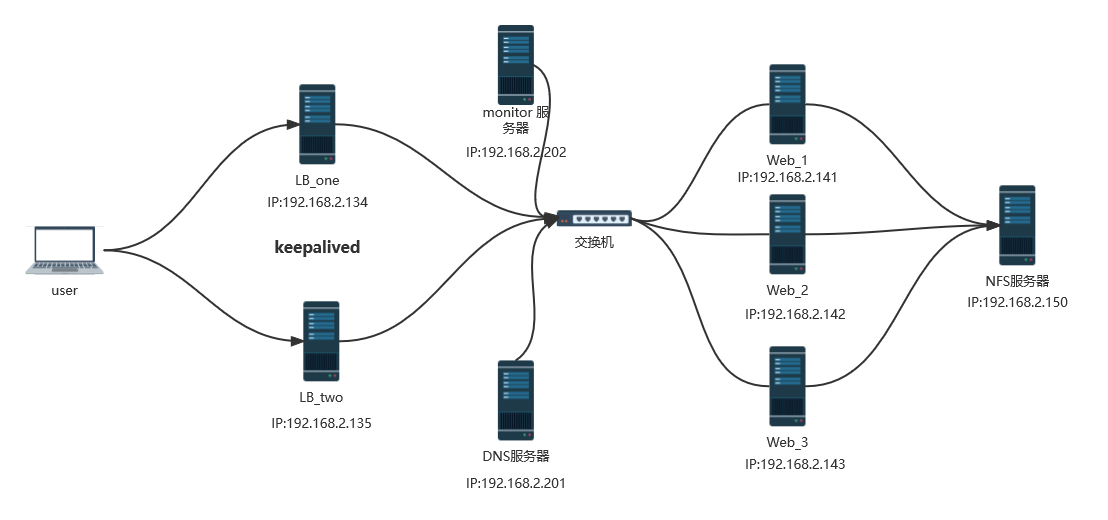
3、高可用实现
网络拓扑图:
1、在负载均衡器上安装keepalived
yum install keepalived -y
a、单vip架构,vip漂移
2、修改配置文件/etc/keepalived/keepalived.conf
主路由:
vrrp_instance VI_1 { #配置一个VRRP实例,名称为VI_1
state MASTER #状态设置为MASTER,表示这是该虚拟路由器ID (VRID)的主路由器
interface ens33 #接口
virtual_router_id 52 #虚拟路由器ID设置为52,用来标识该VRRP实例在网络中的存在,0~255
priority 150 #优先级(0-255)
advert_int 1 #通告间隔设置为1秒,即主路由器每秒发送VRRP通告
authentication { #认证部分指定认证类型为PASS,密码为1111。只有配置了正确密码的路由器才能参与该VRRP实例。
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { #将虚拟IP地址设置为192.168.2.166,该IP地址将用作网络中主机的默认网关。这个IP地址将与主路由器相关联,但是如果主路由器发生故障,备用路由器将接管并使用这个IP地址作为自己的IP地址
192.168.2.166
}
}
备用路由:
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.166
}
}
3、启动keepalived,实现vip漂移
service keepalived restart
LB-one:
[root@lb-one keepalived]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:a7:e7:5c brd ff:ff:ff:ff:ff:ff
inet 192.168.2.134/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.2.166/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fea7:e75c/64 scope link
valid_lft forever preferred_lft forever
[root@lb-one keepalived]# service keepalived stop
Redirecting to /bin/systemctl stop keepalived.service
[root@lb-one keepalived]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:a7:e7:5c brd ff:ff:ff:ff:ff:ff
inet 192.168.2.134/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fea7:e75c/64 scope link
valid_lft forever preferred_lft forever
LB-two:
关闭LB-one前:
[root@lb_two keepalived]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:84:79:69 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.135/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe84:7969/64 scope link
valid_lft forever preferred_lft forever
关闭LB-one后:
[root@lb_two keepalived]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:84:79:69 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.135/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.2.166/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe84:7969/64 scope link
valid_lft forever preferred_lft forever
4、可以看到vip在两台负载均衡器之间漂移
b、双vip架构
启动两个vrrp实例,每台机器启用两个vrrp实例,一个做master,一个做backup;启用两个vip
2、修改配置文件
LB-one:
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 52
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.166
}
}
vrrp_instance VI_2 {
state BACKUP
interface ens33
virtual_router_id 60
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.177
}
}
LB-two:
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.166
}
}
vrrp_instance VI_2 {
state MASTER
interface ens33
virtual_router_id 60
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.177
}
}
3、刷新keepalived的查看效果
LB-one:
占据vip:192.168.2.166
[root@lb-one keepalived]# service keepalived restart
Redirecting to /bin/systemctl restart keepalived.service
[root@lb-one keepalived]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:a7:e7:5c brd ff:ff:ff:ff:ff:ff
inet 192.168.2.134/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.2.166/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fea7:e75c/64 scope link
valid_lft forever preferred_lft forever
LB-two:
占据vip:192.168.2.177
[root@lb_two keepalived]# service keepalived restart
Redirecting to /bin/systemctl restart keepalived.service
[root@lb_two keepalived]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:84:79:69 brd ff:ff:ff:ff:ff:ff
inet 192.168.2.135/24 brd 192.168.2.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.2.177/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe84:7969/64 scope link
valid_lft forever preferred_lft forever
两个负载均衡互为master
c、脑裂现象
两台keepalived高可用服务器在指定时间内,无法检测到对方存活心跳信息,从而导致互相抢占对方的资源和服务所有权,然而此时两台高可用服务器有都还存活。
原因:
1、vrid不一样(虚拟路由id)
2、网络通信有问题(如防火墙组织了vrrp选举过程)
3、认证密码不一样
出现脑裂现象,还是可以正常访问,反而还有负载均衡,但是脑裂现象恢复会使业务出现短暂停止
出现两个master会争抢共享资源,结果会导致系统混乱,数据损坏。对于无状态服务的HA,无所谓脑裂不脑裂;但对有状态服务(比如MySQL)的HA,必须要严格防止脑裂。















 2628
2628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









