






数学基础
贝叶斯
条件概率P(A|B)和P(B|A)之间存在一定关系,
P(A|B)= P(AB)/ P(B)同理 P(B|A)= P(AB)/ P(A)
推导出这种关系即贝叶斯公式:
![]()
极大似然估计
概率:已知参数下结果发生的可能性。 似然:已知某些观测结果的情况下对参数的估计。
我们设条件参数为θ而结果分布为D,那么似然可以表示成L(θ|D)即在结果为D的情况下参数为θ的概率,它在数值上等同于条件概率P(D|θ)。
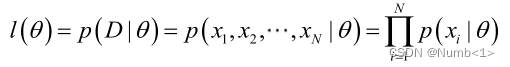
顾名思义,极大似然估计就是用已知结果反推最大概率导致这样结果的参数值,即求出似然函数取最大值时候的参数θ的取值。
GPT实现
GPT是一种基于transformer架构(decoder)的生成式预训练模型。包括无监督的预训练和有监督的下游任务微调。
GPT无监督预训练
给定文本序列u = {u(1)-u(n)},窗口长度为K,通过u(i-1)到u(i-K)预测当前字符u(i),θ为模型参数,于是构成似然函数并使其最大化。似然函数如下(取对数):
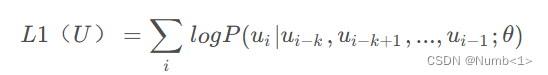
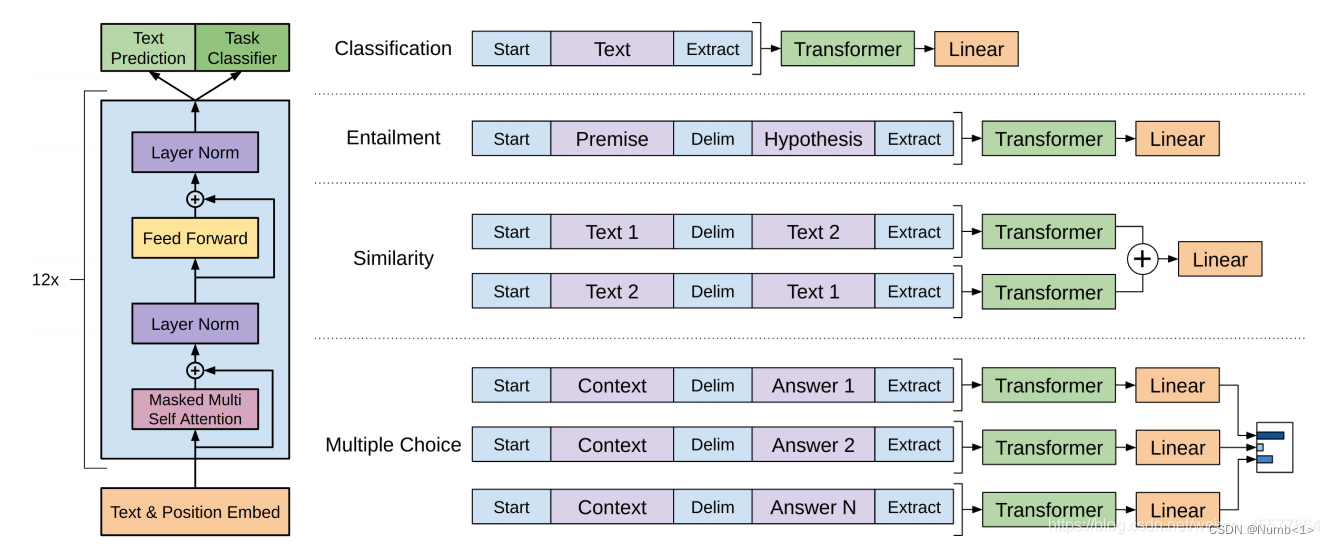
GPT模型结构
GPT基于transformer架构的decoder,也就是在multi-head attention模块加入了sequence-masked机制进行顺序预测。(如图转载)
GPT 语义相似判断任务的pytorch实现
参考代码(强烈推荐,本文只做注释,实现代码为转载。下为转载链接,感谢原创作者!!!如构成侵权,请速与我联系删除,如有注释纰漏,感谢指正):GitHub - MorvanZhou/NLP-Tutorials: Simple implementations of NLP models. Tutorials are written in Chinese on my website https://mofanpy.com
数据集构建
使用MRPC数据集。这个数据集的每条数据包含两个string1和string2,以及两条string是否相似的标签,相似标签为1,不相似标签为0。下面给出数据集的训练和测试集。
https://mofanpy.com/static/files/MRPC/msr_paraphrase_train.txt
https://mofanpy.com/static/files/MRPC/msr_paraphrase_test.txt
数据集下载
def maybe_download_mrpc(save_dir="./MRPC/", proxy=None):
train_url = 'https://mofanpy.com/static/files/MRPC/msr_paraphrase_train.txt'
test_url = 'https://mofanpy.com/static/files/MRPC/msr_paraphrase_test.txt'
os.makedirs(save_dir, exist_ok=True)
proxies = {"http": proxy, "https": proxy}
for url in [train_url, test_url]:
raw_path = os.path.join(save_dir, url.split("/")[-1])
if not os.path.isfile(raw_path):
print("downloading from %s" % url)
r = requests.get(url, proxies=proxies)
with open(raw_path, "w", encoding="utf-8") as f:
f.write(r.text.replace('"', "<QUOTE>"))
print("completed")数据集处理
def _process_mrpc(dir="./MRPC", rows=None):
# 创建字典用于分开存储训练和测试数据
data = {"train": None, "test": None}
files = os.listdir(dir)
for f in files:
df = pd.read_csv(os.path.join(dir, f), sep='\t', nrows=rows)
k = "train" if "train" in f else "test"
# 嵌套字典data{train{is_same{标签}, s1{string1}, s2{string2}}, test{测试数据,同train}}
data[k] = {"is_same": df.iloc[:, 0].values, "s1": df["#1 String"].values, "s2": df["#2 String"].values}
vocab = set()
for n in ["train", "test"]:
for m in ["s1", "s2"]:
for i in range(len(data[n][m])):
# string正则化
data[n][m][i] = _text_standardize(data[n][m][i].lower())
# 创建字符set
cs = data[n][m][i].split(" ")
vocab.update(set(cs))
# 字符转化成整数索引
v2i = {v: i for i, v in enumerate(sorted(vocab), start=1)}
# 补位PAD
v2i["<PAD>"] = PAD_ID
v2i["<MASK>"] = len(v2i)
# 间隔or结束标记
v2i["<SEP>"] = len(v2i)
# 开始标记
v2i["<GO>"] = len(v2i)
# 整数索引转字符
i2v = {i: v for v, i in v2i.items()}
for n in ["train", "test"]:
for m in ["s1", "s2"]:
# 嵌套字典data{train{is_same{}, s1{}, s2{}, s1id{字符序列转整数索引序列}, s2id{同s1id}}, test{...}}
data[n][m + "id"] = [[v2i[v] for v in c.split(" ")] for c in data[n][m]]
return data, v2i, i2vstring正则化(正则化知识不再赘述,可自行查询)
def _text_standardize(text):
text = re.sub(r'—', '-', text)
text = re.sub(r'–', '-', text)
text = re.sub(r'―', '-', text)
text = re.sub(r" \d+(,\d+)?(\.\d+)? ", " <NUM> ", text)
text = re.sub(r" \d+-+?\d*", " <NUM>-", text)
return text.strip()数据集类MRPCData的构建
class MRPCData(tDataset):
# 0、1、2分别表示s1、s2、PAD
num_seg = 3
# PAD整数索引
pad_id = PAD_ID
def __init__(self, data_dir="./MRPC/", rows=None, proxy=None):
# 下载数据集
maybe_download_mrpc(save_dir=data_dir, proxy=proxy)
# 返回嵌套字典data,字符转整数索引字典v2i和整数索引转字符字典i2v
data, self.v2i, self.i2v = _process_mrpc(data_dir, rows)
# 确定输入序列(train,test数据均要考虑)的最大长度max_len +3:<GO> s1id <sep> s2id <sep>
self.max_len = max(
[len(s1) + len(s2) + 3 for s1, s2 in zip(
data["train"]["s1id"] + data["test"]["s1id"], data["train"]["s2id"] + data["test"]["s2id"])])
# 分别计算s1id和s2id的长度为了编码标识string1、string2和PAD
self.xlen = np.array([
[
len(data["train"]["s1id"][i]), len(data["train"]["s2id"][i])
] for i in range(len(data["train"]["s1id"]))], dtype=int)
# 转化整数索引序列 <GO> s1id <SEP> s2id <SEP>
x = [
[self.v2i["<GO>"]] + data["train"]["s1id"][i] + [self.v2i["<SEP>"]] + data["train"]["s2id"][i] + [
self.v2i["<SEP>"]]
for i in range(len(self.xlen))
]
# PAD(0)
self.x = pad_zero(x, max_len=self.max_len)
# 相似标签转二维数组[[]], 便于loss交叉熵计算
self.nsp_y = data["train"]["is_same"][:, None]
# 创建编码, 区分string1、string2、PAD(0, 1, 2)
self.seg = np.full(self.x.shape, self.num_seg - 1, np.int32)
for i in range(len(x)):
# 标记 <GO> s1id <SEP> = 0
si = self.xlen[i][0] + 2
self.seg[i, :si] = 0
# 标记 s2id <SEP> = 1
si_ = si + self.xlen[i][1] + 1
self.seg[i, si:si_] = 1
# 获得非辅助字符的字符的整数索引
self.word_ids = np.array(list(set(self.i2v.keys()).difference(
[self.v2i[v] for v in ["<PAD>", "<MASK>", "<SEP>"]])))
def __getitem__(self, idx):
return self.x[idx], self.seg[idx], self.xlen[idx], self.nsp_y[idx]
def sample(self, n):
bi = np.random.randint(0, self.x.shape[0], size=n)
bx, bs, bl, by = self.x[bi], self.seg[bi], self.xlen[bi], self.nsp_y[bi]
return bx, bs, bl, by
@property
def num_word(self):
return len(self.v2i)
def __len__(self):
return len(self.x)
@property
def mask_id(self):
return self.v2i["<MASK>"]GPT模型构建
首先应当明确的是GPT基于的是transformer架构的decoder block,这么说的原因是对于decoder中的multi-head attention模块的输入需要进行相同的sequence-masked操作来达到顺序预测的目的,然而从代码层面来讲,其实GPT中的decoder block更接近于transformer架构中encoder block的构建,因为只需要一个multi-head attention模块。encoder block代码实现和transformer架构相同,可以参考上一篇transformer的pytorch实现
CSDN https://mp.csdn.net/mp_blog/creation/editor/139606957 GPT模型的代码构建:
https://mp.csdn.net/mp_blog/creation/editor/139606957 GPT模型的代码构建:
class GPT(nn.Module):
def __init__(self, model_dim, max_len, num_layer, num_head, n_vocab, lr, max_seg=3, drop_rate=0.2, padding_idx=0):
super().__init__()
# 初始化PAD的整数索引
self.padding_idx = padding_idx
# 字符数量
self.n_vocab = n_vocab
# 字符串最大长度
self.max_len = max_len
# 字符向特征向量转变(嵌入)
self.word_emb = nn.Embedding(n_vocab, model_dim)
# 初始化embedding层的权重,均值0/方差0.1
self.word_emb.weight.data.normal_(0, 0.1)
# 分割编码的嵌入层,即(0,1,2)用于区分输入序列中的string1、string2和PAD max_seg = 3(0,1,2)
self.segment_emb = nn.Embedding(num_embeddings=max_seg, embedding_dim=model_dim)
# 初始化
self.segment_emb.weight.data.normal_(0, 0.1)
# 位置嵌入矩阵的初始化和可学习参数设置
self.position_emb = torch.empty(1, max_len, model_dim)
nn.init.kaiming_normal_(self.position_emb, mode='fan_out', nonlinearity='relu')
self.position_emb = nn.Parameter(self.position_emb)
# 初始化dencoder block(和encoder结构相似,一个multi-head attention,但是使用sequence-masked)
self.encoder = Encoder(n_head=num_head, emb_dim=model_dim, drop_rate=drop_rate, n_layer=num_layer)
# 实现序列预测,根据前K个字符预测当前字符
self.task_mlm = nn.Linear(in_features=model_dim, out_features=n_vocab)
# 实现相似预测,判断string1和string2是否相似
self.task_nsp = nn.Linear(in_features=model_dim * self.max_len, out_features=2)
# Adam优化器
self.opt = optim.Adam(self.parameters(), lr)
def forward(self, seqs, segs, training=False):
# 嵌入
embed = self.input_emb(seqs, segs)
# decoder
z = self.encoder(embed, training, mask=self.mask(seqs)) # [batch_size, max_len, model_dim]
# 序列预测
mlm_logits = self.task_mlm(z) # [batch_size, max_len, n_vocab]
# 相似标签预测
nsp_logits = self.task_nsp(z.reshape(z.shape[0], -1)) # [batch_size, n_cls]
return mlm_logits, nsp_logits
def step(self, seqs, segs, seqs_, nsp_labels):
self.opt.zero_grad()
# 调用forward函数
mlm_logits, nsp_logits = self(seqs, segs, training=True)
# 交叉熵损失函数计算预测字符的损失
pred_loss = cross_entropy(mlm_logits.reshape(-1, self.n_vocab), seqs_.reshape(-1))
# 交叉熵损失函数计算相似标签损失
nsp_loss = cross_entropy(nsp_logits, nsp_labels.reshape(-1))
# 加权构建损失函数
loss = pred_loss + 0.2 * nsp_loss
loss.backward()
self.opt.step()
return loss.cpu().data.numpy(), mlm_logits
# 嵌入
def input_emb(self, seqs, segs):
return self.word_emb(seqs) + self.segment_emb(segs) + self.position_emb
# sequence-masked
def mask(self, seqs):
device = next(self.parameters()).device
batch_size, seq_len = seqs.shape
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.long), diagonal=1).to(device) # [seq_len ,seq_len]
pad = torch.eq(seqs, self.padding_idx) # [n, seq_len]
mask = torch.where(pad[:, None, None, :], 1, mask[None, None, :, :]).to(device) # [batch_size, 1, seq_len, seq_len]
return mask > 0 # [batch_size, 1, seq_len, seq_len]
@property
def attentions(self):
attentions = {
"encoder": [l.mh.attention.cpu().data.numpy() for l in self.encoder.encoder_layers]
}
return attentions模型训练
def train():
# emb_dim
MODEL_DIM = 256
N_LAYER = 4
LEARNING_RATE = 1e-4
# 创建数据集
dataset = utils.MRPCData("./MRPC", 5000)
print("num word: ", dataset.num_word)
# 初始化GPT模型
model = GPT(
model_dim=MODEL_DIM, max_len=dataset.max_len - 1, num_layer=N_LAYER, num_head=4, n_vocab=dataset.num_word,
lr=LEARNING_RATE, max_seg=dataset.num_seg, drop_rate=0.2, padding_idx=dataset.pad_id
)
# cpu or cuda
if torch.cuda.is_available():
print("GPU train avaliable")
device = torch.device("cuda")
model = model.cuda()
else:
device = torch.device("cpu")
model = model.cpu()
# batch_size 32
loader = DataLoader(dataset, batch_size=64, shuffle=True)
# 世代 1000
for epoch in range(1000):
for batch_idx, batch in enumerate(loader):
# 返回 <GO> s1id <SEP> s2id <SEP> PAD 的id序列, mask序列[0..1..2..], s1id\s2id 的长度, 相似标签
seqs, segs, xlen, nsp_labels = batch
seqs, segs, nsp_labels = seqs.type(torch.LongTensor).to(device), segs.type(torch.LongTensor).to(
device), nsp_labels.to(device)
# 顺序序列预测,输入序列为[:-1],预测序列为[1:]
loss, pred = model.step(seqs=seqs[:, :-1], segs=segs[:, :-1], seqs_=seqs[:, 1:], nsp_labels=nsp_labels)
if batch_idx % 5 == 0:
pred = pred[0].cpu().data.numpy().argmax(axis=1) # [step]
print(
"Epoch: ", epoch,
"|batch: ", batch_idx,
"| loss: %.3f" % loss,
"\n| tgt: ", " ".join([dataset.i2v[i] for i in seqs[0, 1:].cpu().data.numpy()[:xlen[0].sum() + 1]]),
"\n| prd: ", " ".join([dataset.i2v[i] for i in pred[:xlen[0].sum() + 1]]),
)
os.makedirs("./visual/models/gpt", exist_ok=True)
torch.save(model.state_dict(), "./visual/models/gpt/model.pth")
export_attention(model, device, dataset)

















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











