






前言
github仓库寻找的项目,并非原创,感觉拿来学习和理解transformer架构挺好的,记录一下个人的浅薄理解。感谢代码原创作者和指正!如有侵权请与我联系。
项目简介
基于transformer架构实现中文日期向英文日期的转变。即Chinese time order [yy/mm/dd] ---- English time order [dd/M/yyyy]。
for example (日期:2031/4/26): 31/04/26 --- 26/Apr/2031项目实现
数据集构建
构建Datedata类生成数据。
类初始化:
def __init__(self, n):
# 设计随机数生成种子
np.random.seed(1)
# 创建中英文日期列表
self.date_cn = []
self.date_en = []
# 生成n个随机日期
for timestamp in np.random.randint(143835585, 2043835585, n):
date = datetime.datetime.fromtimestamp(timestamp)
self.date_cn.append(date.strftime("%y-%m-%d"))
self.date_en.append(date.strftime("%d/%b/%Y"))
# 把日期字符串所涉及的0-9、英文日期所涉及的月份简写(Apr)、中英文日期连接字符以及开始标志<GO>和结束标志<EOS>存入集合vocab
self.vocab = set(
[str(i) for i in range(0, 10)] + ["-", "/", "<GO>", "<EOS>"] + [i.split("/")[1] for i in self.date_en]
)
# 生成字典:以整数形式表示每个字符(<GO>:int a),i从1起始,因为补充字符<PAD>:0
self.v2i = {v: i for i, v in enumerate(sorted(list(self.vocab)), start=1)}
# 加入短句结尾的补充字符,值为PAD_ID == 0
self.v2i["<PAD>"] = PAD_ID
# 字符字典相应的加上补充字符<PAD>
self.vocab.add("<PAD>")
# 反转字典,用于整数--字符,idx2str
self.i2v = {i: v for v, i in self.v2i.items()}
self.x, self.y = [], []
# 生成输入序列x和标签序列y(str2idx),标签序列加入开始结束符号idx
for cn, en in zip(self.date_cn, self.date_en):
self.x.append([self.v2i[v] for v in cn])
self.y.append([self.v2i["<GO>"], ] + [self.v2i[v] for v in en[:3]] + [
self.v2i[en[3:6]]] + [self.v2i[v] for v in en[6:]] + [self.v2i["<EOS>"], ])
self.x, self.y = np.array(self.x), np.array(self.y)
self.start_token = self.v2i["<GO>"]
self.end_token = self.v2i["<EOS>"]其他类函数:
# 返回生成日期数据的个数n
def __len__(self):
return len(self.x)
# 涉及字符数量
@property
def num_word(self):
return len(self.vocab)
# 取元素
def __getitem__(self, index):
return self.x[index], self.y[index], len(self.y[index]) - 1
# 整数序列向str转变
def idx2str(self, idx):
x = []
for i in idx:
x.append(self.i2v[i])
if i == self.end_token:
break
return "".join(x)transformer架构实现
embedding实现
输入str的embedding包括词embedding和位置embedding,如图(转载)
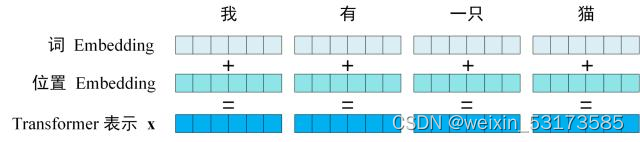
位置embedding遵循(pos为字符在输入序列中的位置,d为emb_dim即每个字符嵌入向量的维度,2i 或者 2i + 1分别表示字符嵌入向量idx的奇偶) 
代码实现:
class PositionEmbedding(nn.Module):
def __init__(self, max_len, emb_dim, n_vocab):
super().__init__()
pos = np.expand_dims(np.arange(max_len), 1)
# 依靠广播实现位置embedding(如公式)
pe = pos / np.power(10000, 2 * np.expand_dims(np.arange(emb_dim) // 2, 0) / emb_dim)
pe[:, 0::2] = np.sin(pe[:, 0::2])
pe[:, 1::2] = np.cos(pe[:, 1::2])
# 加上batch_size维度
pe = np.expand_dims(pe, 0)
self.pe = torch.from_numpy(pe).type(torch.float32)
# 构建嵌入矩阵并初始化权重
self.embeddings = nn.Embedding(n_vocab, emb_dim)
self.embeddings.weight.data.normal_(0, 0.1)
def forward(self, x):
# cpu or cuda
device = self.embeddings.weight.device
self.pe = self.pe.to(device)
# 词embedding + 位置embedding
x_embed = self.embeddings(x) + self.pe
return x_embed encoder block实现
transformer架构的encoder block由多个encoder组成,每个encoder又由Multi-Head Attention和Feed Forward组成。
encoder代码实现
class EncoderLayer(nn.Module):
def __init__(self, n_head, emb_dim, drop_rate):
super().__init__()
# multi-head attention
self.mh = MultiHead(n_head, emb_dim, drop_rate)
# feed forward
self.ffn = PositionWiseFFN(emb_dim, drop_rate)
def forward(self, xz, training, mask):
# xz: [n, step, emb_dim],输入序列的embedding,mh + ffn = encoder
context = self.mh(xz, xz, xz, mask, training)
o = self.ffn(context)
return oencoder中multi-head attention模块实现
class MultiHead(nn.Module):
def __init__(self, n_head, model_dim, drop_rate):
super().__init__()
self.head_dim = model_dim // n_head
self.n_head = n_head
self.model_dim = model_dim
# wq, wk, wv权值矩阵初始化
self.wq = nn.Linear(model_dim, n_head * self.head_dim)
self.wk = nn.Linear(model_dim, n_head * self.head_dim)
self.wv = nn.Linear(model_dim, n_head * self.head_dim)
self.o_dense = nn.Linear(model_dim, model_dim)
# dropout防止过拟合
self.o_drop = nn.Dropout(drop_rate)
# layer归一化(不是batch归一化)
self.layer_norm = nn.LayerNorm(model_dim)
self.attention = None
def forward(self, q, k, v, mask, training):
# 残差short cut
residual = q
# 得到q、k、v矩阵
key = self.wk(k) # [batch_size, max_len, num_heads * head_dim]
value = self.wv(v) # [batch_size, max_len, num_heads * head_dim]
query = self.wq(q) # [batch_size, max_len, num_heads * head_dim]
# 按照每个head split
query = self.split_heads(query) # [batch_size, n_head, max_len, h_dim]
key = self.split_heads(key) # [batch_size, n_head, max_len, h_dim]
value = self.split_heads(value) # [batch_size, n_head, max_len, h_dim]
# self-attention
context = self.scaled_dot_product_attention(query, key, value, mask)
o = self.o_dense(context) # [batch_size, max_len, emb_dim]
o = self.o_drop(o)
# 残差
o = self.layer_norm(residual + o)
return o
def split_heads(self, x):
x = torch.reshape(x, (x.shape[0], x.shape[1], self.n_head, self.head_dim))
return x.permute(0, 2, 1, 3)multi-head attention 中 attention 模块的实现(如公式所示)

def scaled_dot_product_attention(self, q, k, v, mask=None):
# 求key矩阵最后一维度,开平方作为除数防止内积过大
dk = torch.tensor(k.shape[-1]).type(torch.float) # tensor(8.)
score = torch.matmul(q, k.permute(0, 1, 3, 2)) / (torch.sqrt(dk) + 1e-8) # [batch_size, n_head, max_len, max_len]
if mask is not None:
# 输入序列PAD维度填充负无穷大
score = score.masked_fill_(mask, -np.inf)
# 最后一维度计算softmax
self.attention = softmax(score, dim=-1)
context = torch.matmul(self.attention, v) # [batch_size, num_head, max_len, head_dim]
context = context.permute(0, 2, 1, 3) # [batch_size, max_len, num_head, head_dim]
context = context.reshape((context.shape[0], context.shape[1], -1))
return context # [batch_size, max_len, model_dim]encoder中ffn模块实现(如公式)
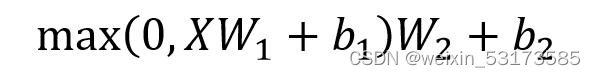
class PositionWiseFFN(nn.Module):
def __init__(self, model_dim, dropout=0.0):
super().__init__()
dff = model_dim * 4
self.l = nn.Linear(model_dim, dff)
self.o = nn.Linear(dff, model_dim)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, x):
o = relu(self.l(x))
o = self.o(o)
o = self.dropout(o)
o = self.layer_norm(x + o)
return o # [batch_size, max_len, model_dim]encoder_block实现(encoder的叠加)
class Encoder(nn.Module):
def __init__(self, n_head, emb_dim, drop_rate, n_layer):
super().__init__()
self.encoder_layers = nn.ModuleList(
[EncoderLayer(n_head, emb_dim, drop_rate) for _ in range(n_layer)]
)
def forward(self, xz, training, mask):
for encoder in self.encoder_layers:
xz = encoder(xz, training, mask)
return xz # [batch_size, max_len, emb_dim]decoder block实现
decoder block同样由多个decoder组成,每个decoder包括两个不同的multi-head attention模块和ffd模块,decoder模块和encoder模块相似,但存在以下区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层使用Sequence-Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。使用和encoder中Multi-Head Attention相同的PAD-Masked操作。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
decoder代码实现
class DecoderLayer(nn.Module):
def __init__(self, n_head, model_dim, drop_rate):
super().__init__()
self.mh = nn.ModuleList([MultiHead(n_head, model_dim, drop_rate) for _ in range(2)])
self.ffn = PositionWiseFFN(model_dim, drop_rate)
# decoded_z = self.decoder(y_embed, encoded_z, training, yz_look_ahead_mask, pad_mask) # [n, step, emb_dim]
def forward(self, yz, xz, training, yz_look_ahead_mask, xz_pad_mask):
dec_output = self.mh[0](yz, yz, yz, yz_look_ahead_mask, training) # [n, step, model_dim]
dec_output = self.mh[1](dec_output, xz, xz, xz_pad_mask, training) # [n, step, model_dim]
dec_output = self.ffn(dec_output) # [n, step, model_dim]
return dec_outputdecoder block代码实现
class Decoder(nn.Module):
def __init__(self, n_head, model_dim, drop_rate, n_layer):
super().__init__()
self.num_layers = n_layer
self.decoder_layers = nn.ModuleList(
[DecoderLayer(n_head, model_dim, drop_rate) for _ in range(n_layer)]
)
def forward(self, yz, xz, training, yz_look_ahead_mask, xz_pad_mask):
for decoder in self.decoder_layers:
yz = decoder(yz, xz, training, yz_look_ahead_mask, xz_pad_mask)
return yz # [batch_size, max_len, model_dim]sequence-masked操作代码实现(和PAD-masked一样,最终输出布尔类型的矩阵,true表示无效(有掩码),false表示有效(无掩码)),sequence-masked本质上为了实现顺序预测。
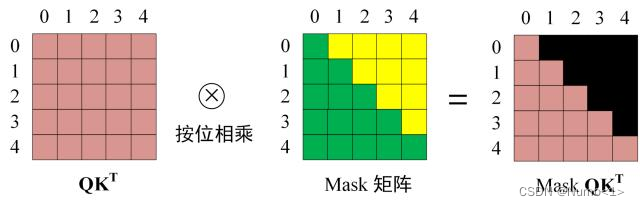
def _look_ahead_mask(self, seqs):
# cpu or cuda
device = next(self.parameters()).device
batch_size, seq_len = seqs.shape #[batch_size, max_len]
# 创建上三角矩阵
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.long), diagonal=1).to(device) # [seq_len ,seq_len]
# 广播获得sequence-masked
mask = torch.where(self._pad_bool(seqs)[:, None, None, :], 1, mask[None, None, :, :]).to(device) # [batch_size, 1, max_len, max_len]
return mask > 0 # [batch_size, 1, max_len, max_len]训练过程
def train(emb_dim=32, n_layer=3, n_head=4):
# 随即生成4000个日期(中英文 + 整数序列表示),作为数据集
dataset = utils.DateData(4000)
# 数据展示
print("Chinese time order: yy/mm/dd ", dataset.date_cn[:], "\nEnglish time order: dd/M/yyyy", dataset.date_en[:])
print("Vocabularies: ", dataset.vocab)
print(f"x index sample: \n{dataset.idx2str(dataset.x[0])}\n{dataset.x[0]}",
f"\ny index sample: \n{dataset.idx2str(dataset.y[0])}\n{dataset.y[0]}")
# batch_size = 256, shuffle = true
loader = DataLoader(dataset, batch_size=256, shuffle=True)
# 调用transformer类
model = Transformer(n_vocab=dataset.num_word, max_len=MAX_LEN, n_layer=n_layer, emb_dim=emb_dim, n_head=n_head,
drop_rate=0.1, padding_idx=0)
# cpu or cuda
if torch.cuda.is_available():
print("GPU train avaliable")
device = torch.device("cuda")
model = model.cuda()
else:
device = torch.device("cpu")
model = model.cpu()
# epoch = 500
for i in range(500):
for batch_idx, batch in enumerate(loader):
bx, by, decoder_len = batch
# PAD
bx, by = torch.from_numpy(utils.pad_zero(bx, max_len=MAX_LEN)).type(torch.LongTensor).to(
device), torch.from_numpy(utils.pad_zero(by, MAX_LEN + 1)).type(torch.LongTensor).to(device)
loss, logits = model.step(bx, by)
if batch_idx % 5 == 0:
target = dataset.idx2str(by[0, 1:-1].cpu().data.numpy())
pred = model.translate(bx[0:1], dataset.v2i, dataset.i2v)
res = dataset.idx2str(pred[0].cpu().data.numpy())
src = dataset.idx2str(bx[0].cpu().data.numpy())
print(
"Epoch: ", i,
"| t: ", batch_idx,
"| loss: %.3f" % loss,
"| input: ", src,
"| target: ", target,
"| inference: ", res,
)训练结果
省事了,短暂训练结果
![]()
完整代码
transformer.py
import torch.nn as nn
from torch.nn.functional import cross_entropy, softmax, relu
import numpy as np
import torch
from torch.utils import data
import utils
from torch.utils.data import DataLoader
import argparse
MAX_LEN = 11
# 多头注意力机制
class MultiHead(nn.Module):
def __init__(self, n_head, model_dim, drop_rate):
super().__init__()
self.head_dim = model_dim // n_head
self.n_head = n_head
self.model_dim = model_dim
self.wq = nn.Linear(model_dim, n_head * self.head_dim)
self.wk = nn.Linear(model_dim, n_head * self.head_dim)
self.wv = nn.Linear(model_dim, n_head * self.head_dim)
self.o_dense = nn.Linear(model_dim, model_dim)
self.o_drop = nn.Dropout(drop_rate)
self.layer_norm = nn.LayerNorm(model_dim)
self.attention = None
def forward(self, q, k, v, mask, training):
# residual connect
residual = q
dim_per_head = self.head_dim
num_heads = self.n_head
batch_size = q.size(0)
key = self.wk(k) # [batch_size, max_len, num_heads * head_dim]
value = self.wv(v) # [batch_size, max_len, num_heads * head_dim]
query = self.wq(q) # [batch_size, max_len, num_heads * head_dim]
# split by head
query = self.split_heads(query) # [batch_size, n_head, max_len, h_dim]
key = self.split_heads(key) # [batch_size, n_head, max_len, h_dim]
value = self.split_heads(value) # [batch_size, n_head, max_len, h_dim]
context = self.scaled_dot_product_attention(query, key, value, mask) # [n, q_step, h*dv]
o = self.o_dense(context)
o = self.o_drop(o)
o = self.layer_norm(residual + o)
return o
def split_heads(self, x):
x = torch.reshape(x, (x.shape[0], x.shape[1], self.n_head, self.head_dim))
return x.permute(0, 2, 1, 3)
def scaled_dot_product_attention(self, q, k, v, mask=None):
dk = torch.tensor(k.shape[-1]).type(torch.float) # tensor(n.)
score = torch.matmul(q, k.permute(0, 1, 3, 2)) / (torch.sqrt(dk) + 1e-8)
if mask is not None:
# change the value at masked position to negative infinity,
# so the attention score at these positions after softmax will close to 0.
score = score.masked_fill_(mask, -np.inf)
self.attention = softmax(score, dim=-1)
context = torch.matmul(self.attention, v) # [batch_size, num_head, max_len, head_dim]
context = context.permute(0, 2, 1, 3) # [batch_size, max_len, num_head, head_dim]
context = context.reshape((context.shape[0], context.shape[1], -1))
return context # [batch_size, max_len, model_dim]
class PositionWiseFFN(nn.Module):
def __init__(self, model_dim, dropout=0.0):
super().__init__()
dff = model_dim * 4
self.l = nn.Linear(model_dim, dff)
self.o = nn.Linear(dff, model_dim)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, x):
o = relu(self.l(x))
o = self.o(o)
o = self.dropout(o)
o = self.layer_norm(x + o)
return o
class EncoderLayer(nn.Module):
def __init__(self, n_head, emb_dim, drop_rate):
super().__init__()
self.mh = MultiHead(n_head, emb_dim, drop_rate)
self.ffn = PositionWiseFFN(emb_dim, drop_rate)
def forward(self, xz, training, mask):
context = self.mh(xz, xz, xz, mask, training) # [n, step, emb_dim]
o = self.ffn(context)
return o
class Encoder(nn.Module):
def __init__(self, n_head, emb_dim, drop_rate, n_layer):
super().__init__()
self.encoder_layers = nn.ModuleList(
[EncoderLayer(n_head, emb_dim, drop_rate) for _ in range(n_layer)]
)
def forward(self, xz, training, mask):
for encoder in self.encoder_layers:
xz = encoder(xz, training, mask)
return xz
class DecoderLayer(nn.Module):
def __init__(self, n_head, model_dim, drop_rate):
super().__init__()
self.mh = nn.ModuleList([MultiHead(n_head, model_dim, drop_rate) for _ in range(2)])
self.ffn = PositionWiseFFN(model_dim, drop_rate)
def forward(self, yz, xz, training, yz_look_ahead_mask, xz_pad_mask):
dec_output = self.mh[0](yz, yz, yz, yz_look_ahead_mask, training) # [n, step, model_dim]
dec_output = self.mh[1](dec_output, xz, xz, xz_pad_mask, training) # [n, step, model_dim]
dec_output = self.ffn(dec_output) # [n, step, model_dim]
return dec_output
class Decoder(nn.Module):
def __init__(self, n_head, model_dim, drop_rate, n_layer):
super().__init__()
self.num_layers = n_layer
self.decoder_layers = nn.ModuleList(
[DecoderLayer(n_head, model_dim, drop_rate) for _ in range(n_layer)]
)
def forward(self, yz, xz, training, yz_look_ahead_mask, xz_pad_mask):
for decoder in self.decoder_layers:
yz = decoder(yz, xz, training, yz_look_ahead_mask, xz_pad_mask)
return yz
class PositionEmbedding(nn.Module):
def __init__(self, max_len, emb_dim, n_vocab):
super().__init__()
pos = np.expand_dims(np.arange(max_len), 1)
pe = pos / np.power(1000, 2 * np.expand_dims(np.arange(emb_dim) // 2, 0) / emb_dim)
pe[:, 0::2] = np.sin(pe[:, 0::2])
pe[:, 1::2] = np.cos(pe[:, 1::2])
pe = np.expand_dims(pe, 0)
self.pe = torch.from_numpy(pe).type(torch.float32)
self.embeddings = nn.Embedding(n_vocab, emb_dim) # 创建整数索引对应的词emb向量
self.embeddings.weight.data.normal_(0, 0.1)
def forward(self, x):
device = self.embeddings.weight.device
self.pe = self.pe.to(device)
x_embed = self.embeddings(x) + self.pe # [batch_size, max_len, emb_dim]
return x_embed
class Transformer(nn.Module):
def __init__(self, n_vocab, max_len, n_layer=6, emb_dim=512, n_head=8, drop_rate=0.1, padding_idx=0):
super().__init__()
self.max_len = max_len
self.padding_idx = torch.tensor(padding_idx)
self.dec_v_emb = n_vocab
self.embed = PositionEmbedding(max_len, emb_dim, n_vocab)
self.encoder = Encoder(n_head, emb_dim, drop_rate, n_layer)
self.decoder = Decoder(n_head, emb_dim, drop_rate, n_layer)
self.o = nn.Linear(emb_dim, n_vocab)
self.opt = torch.optim.Adam(self.parameters(), lr=0.002)
def forward(self, x, y, training=None):
x_embed, y_embed = self.embed(x), self.embed(y) # [batch_size, max_len, emb_dim] * 2
pad_mask = self._pad_mask(x) # [batch_size, 1, max_len, max_len]
encoded_z = self.encoder(x_embed, training, pad_mask) # [batch_size, max_len, emb_dim]
yz_look_ahead_mask = self._look_ahead_mask(y) # [batch_size, 1, max_len, max_len]
decoded_z = self.decoder(y_embed, encoded_z, training, yz_look_ahead_mask, pad_mask) # [batch_size, max_len, emb_dim]
o = self.o(decoded_z) # [batch_size, max_len, n_vocab]
return o
def step(self, x, y):
self.opt.zero_grad()
logits = self(x, y[:, :-1], training=True)
pad_mask = ~torch.eq(y[:, 1:], self.padding_idx)
loss = cross_entropy(logits.reshape(-1, self.dec_v_emb), y[:, 1:].reshape(-1))
loss.backward()
self.opt.step()
return loss.cpu().data.numpy(), logits
def _pad_bool(self, seqs):
o = torch.eq(seqs, self.padding_idx) # [batch_size, max_len]
return o
def _pad_mask(self, seqs):
len_q = seqs.size(1)
mask = self._pad_bool(seqs).unsqueeze(1).expand(-1, len_q, -1) # [batch_size, max_len, max_len]
return mask.unsqueeze(1) # [batch_size, 1, max_len, max_len]
def _look_ahead_mask(self, seqs):
# [batch_size, max_len, emb_dim]
device = next(self.parameters()).device
batch_size, seq_len = seqs.shape
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.long), diagonal=1).to(device) # [seq_len ,seq_len]
# 广播获得前瞻性掩码
mask = torch.where(self._pad_bool(seqs)[:, None, None, :], 1, mask[None, None, :, :]).to(device) # [batch_size, 1, max_len, max_len]
return mask > 0 # [batch_size, 1, seq_len, seq_len]
def translate(self, src, v2i, i2v):
self.eval()
device = next(self.parameters()).device
src_pad = src
# Initialize Decoder input by constructing a matrix M([n, self.max_len+1]) with initial value:
# M[n,0] = start token id
# M[n,:] = 0
target = torch.from_numpy(
utils.pad_zero(np.array([[v2i["<GO>"], ] for _ in range(len(src))]), self.max_len + 1)).to(device)
x_embed = self.embed(src_pad)
encoded_z = self.encoder(x_embed, False, mask=self._pad_mask(src_pad))
for i in range(0, self.max_len):
y = target[:, :-1]
y_embed = self.embed(y)
decoded_z = self.decoder(y_embed, encoded_z, False, self._look_ahead_mask(y), self._pad_mask(src_pad))
o = self.o(decoded_z)[:, i, :]
idx = o.argmax(dim=1).detach()
# Update the Decoder input, to predict for the next position.
target[:, i + 1] = idx
self.train()
return target
def train(emb_dim=32, n_layer=3, n_head=4):
# 随即生成4000个日期(中英文 + embedding),作为数据集
dataset = utils.DateData(4000)
print("Chinese time order: yy/mm/dd ", dataset.date_cn[:], "\nEnglish time order: dd/M/yyyy", dataset.date_en[:])
print("Vocabularies: ", dataset.vocab)
print(f"x index sample: \n{dataset.idx2str(dataset.x[0])}\n{dataset.x[0]}",
f"\ny index sample: \n{dataset.idx2str(dataset.y[0])}\n{dataset.y[0]}")
loader = DataLoader(dataset, batch_size=256, shuffle=True)
model = Transformer(n_vocab=dataset.num_word, max_len=MAX_LEN, n_layer=n_layer, emb_dim=emb_dim, n_head=n_head,
drop_rate=0.1, padding_idx=0)
if torch.cuda.is_available():
print("GPU train avaliable")
device = torch.device("cuda")
model = model.cuda()
else:
device = torch.device("cpu")
model = model.cpu()
for i in range(1):
for batch_idx, batch in enumerate(loader):
bx, by, decoder_len = batch
bx, by = torch.from_numpy(utils.pad_zero(bx, max_len=MAX_LEN)).type(torch.LongTensor).to(
device), torch.from_numpy(utils.pad_zero(by, MAX_LEN + 1)).type(torch.LongTensor).to(device)
loss, logits = model.step(bx, by)
if batch_idx % 1 == 0:
target = dataset.idx2str(by[0, 1:-1].cpu().data.numpy())
pred = model.translate(bx[0:1], dataset.v2i, dataset.i2v)
res = dataset.idx2str(pred[0].cpu().data.numpy())
src = dataset.idx2str(bx[0].cpu().data.numpy())
print(
"Epoch: ", i,
"| t: ", batch_idx,
"| loss: %.3f" % loss,
"| input: ", src,
"| target: ", target,
"| inference: ", res,
)
if __name__ == "__main__":
parser = argparse.ArgumentParser() # 创建解析器
parser.add_argument("--emb_dim", type=int, help="change the model dimension")
parser.add_argument("--n_layer", type=int, help="change the number of layers in Encoder and Decoder")
parser.add_argument("--n_head", type=int, help="change the number of heads in MultiHeadAttention")
args = parser.parse_args()
args = dict(filter(lambda x: x[1], vars(args).items()))
train(**args)utils.py
import numpy as np
from torch.utils.data import Dataset as tDataset
import datetime
PAD_ID = 0
class DateData(tDataset):
def __init__(self, n):
# 设计随机数生成种子
np.random.seed(1)
self.date_cn = []
self.date_en = []
for timestamp in np.random.randint(143835585, 2043835585, n):
date = datetime.datetime.fromtimestamp(timestamp)
self.date_cn.append(date.strftime("%y-%m-%d"))
self.date_en.append(date.strftime("%d/%b/%Y"))
self.vocab = set(
[str(i) for i in range(0, 10)] + ["-", "/", "<GO>", "<EOS>"] + [i.split("/")[1] for i in self.date_en]
)
self.v2i = {v: i for i, v in enumerate(sorted(list(self.vocab)), start=1)}
self.v2i["<PAD>"] = PAD_ID
self.vocab.add("<PAD>")
self.i2v = {i: v for v, i in self.v2i.items()}
self.x, self.y = [], []
for cn, en in zip(self.date_cn, self.date_en):
self.x.append([self.v2i[v] for v in cn])
self.y.append([self.v2i["<GO>"], ] + [self.v2i[v] for v in en[:3]] + [
self.v2i[en[3:6]]] + [self.v2i[v] for v in en[6:]] + [self.v2i["<EOS>"], ])
self.x, self.y = np.array(self.x), np.array(self.y)
self.start_token = self.v2i["<GO>"]
self.end_token = self.v2i["<EOS>"]
def __len__(self):
return len(self.x)
@property
def num_word(self):
return len(self.vocab)
def __getitem__(self, index):
return self.x[index], self.y[index], len(self.y[index]) - 1
def idx2str(self, idx):
x = []
for i in idx:
x.append(self.i2v[i])
if i == self.end_token:
break
return "".join(x)
def pad_zero(seqs, max_len):
padded = np.full((len(seqs), max_len), fill_value=PAD_ID, dtype=np.int32)
for i, seq in enumerate(seqs):
padded[i, :len(seq)] = seq
return padded















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











