







1.项目简介
1.1项目背景
随着人们生活水平的提高和消费观念的更新,图书市场需求不断发生变化,出现了需求多样化的趋势。近年来,我国网民网上读书率正在迅速增长,上网阅读率平均每年增长10%。纸质阅读力虽然在下降,但是传统的纸质图书阅读在相当长的时间内仍将占据重要地位。纸质阅读面临许多挑战,如新媒体对传统纸质媒体市场进行瓜分、中国出版业创新不足和纸质图书价格过高等问题。针对如下现象,本文主要针对主要文学类纸质图书价格、销量、折扣等研究其之间的相互关系,旨在找到一个合适的价格区间,让商家和读者都能接受的纸质图书价格,以此来提高商家的销量和读者的购买量,让二者均从此获益。
1.2项目功能
(1)后裔采集器获取当当网图书数据
(2) Python数据预处理
(3)数据上传Hive
(4)Hive数据分析
(5)MapperReduce数据分析
(6)Python数据可视化分析
1.3运行环境
(1)操作系统:Linux(Ubuntu16.04);
(2) MySQL版本:5.7.16;
(3)Hadoop版本:2.7.1;
(4)HBase版本:1.1.5;
(5)Hive版本:1.2.1;
(6)Sqoop版本:1.4.6;
(7)Eclipse版本:3.8。
2.数据集与数据预处理
2.1数据集
(1)数据来源
本项目数据收集文学类图书中戏剧文学、文学理论、纪实文学、中国古诗词、民间文学共5中类型的书籍,每类6000行数据,一共30000万行数据。
(2)采集数据包涵数据类型
| 字段名称 |
字段说明 |
字段类型 |
| name |
书名 |
String |
| price |
价格 |
Int |
| author |
作者 |
String |
| evaluate |
评价数量 |
Int |
| publish_time |
出版时间 |
String |
| discount |
折扣 |
Float |
| publish |
出版社 |
String |
| type |
类型 |
String |
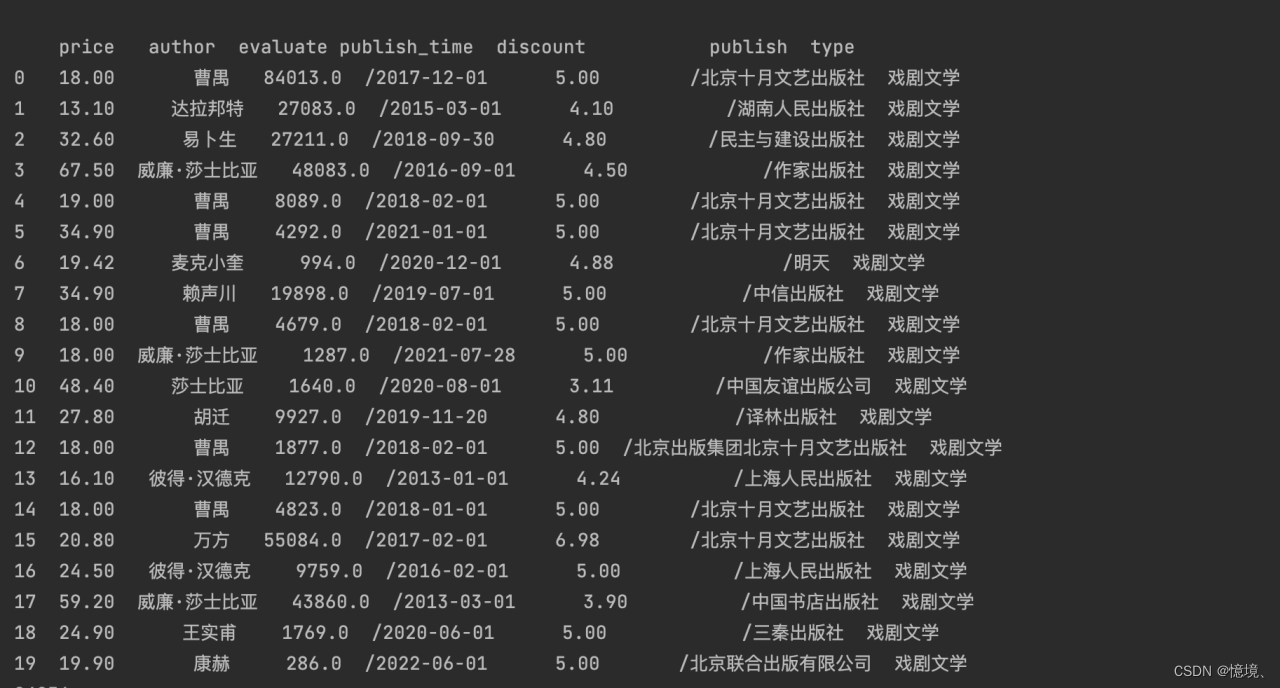
(3)前20行数据查询(由于书名太长,所以这里暂不显示)
2.2数据预处理
2.2.1 Python数据预处理
对出版时间(publish_time)和出版社(publish)字符串进行提取,删除特殊字符“/”;在书名(name)因为太长,不适合观察数据,所以只截取了前面5个字符;在末尾增加1列数量(number),均赋值为1,表示每种图书被出版了1次;对评价数量(evaluate)在采集数据时通过观察发现,当该书籍没有评价时,采集到对书籍为空值,所以对所有评价数量为空值的赋值为0;最后对所有存在空值所在的行进行删除操作。Python预处理之后的数据一共有24028行,前20行数据
Python预处理之后数据类型
| 字段名称 |
字段说明 |
字段类型 |
| name |
书名 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









