







目录
前言
OS→管理硬件→CPU是最核心的硬件
OS首先管理CPU,引出多进程图像
CPU管理的直观想法
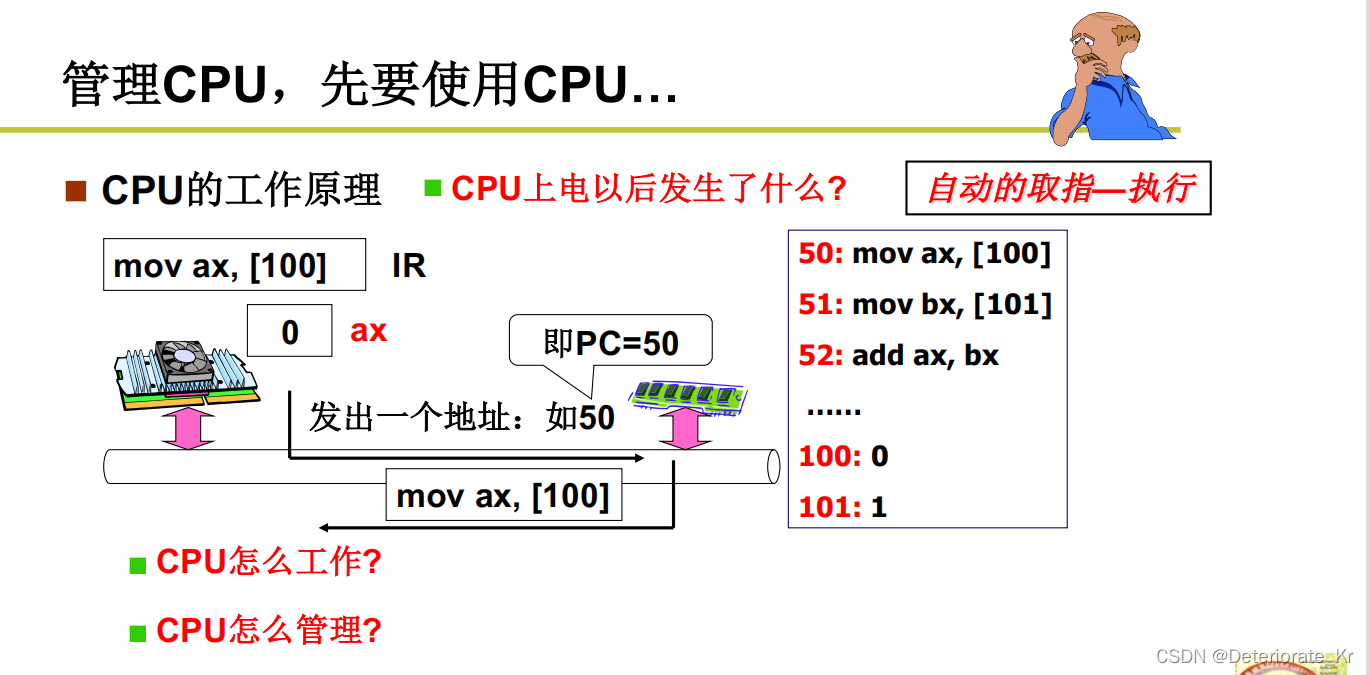
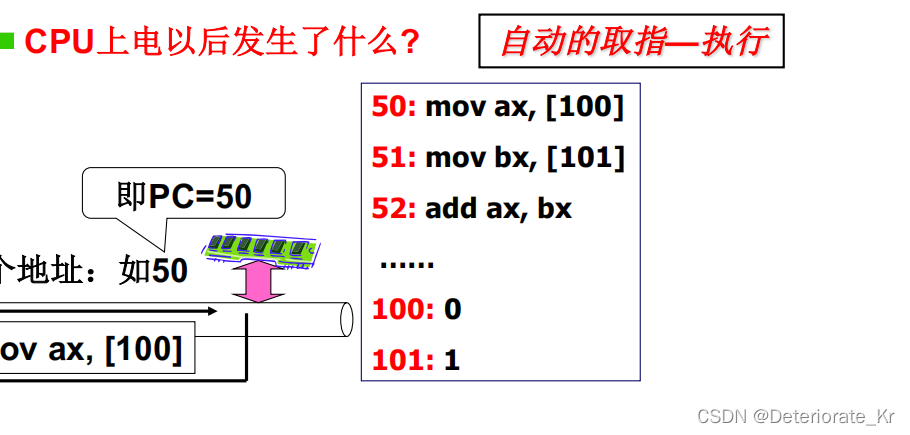
计算机工作的方式是取指执行(取的是PC的值),而且这个PC后面会自动累加。
CPU通过总线发出取指命令(把50放在地址总线上),内存工作;
内存把50这条指令传回CPU,cpu解释执行
所以这个PC值是关键,PC会自动累加.理论上让CPU工作,就是把PC置为程序初值就完事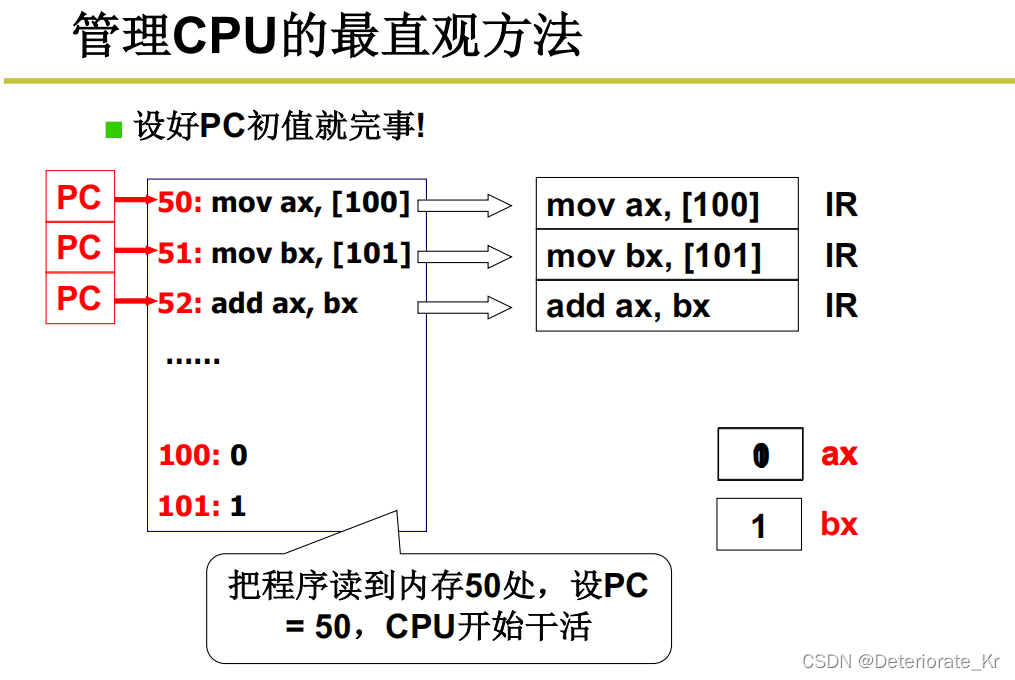
但事实却没有这么简单
fprintf是一条I/O指令,来看看执行一条I/O指令和不执行一条I/O指令所需时间的比较↓


5.7X10^5:1≈10 ^6:1,也就是说执行一条I/O指令的时间大约可执行10 ^6次方条计算指令!!!为什么I/O指令这么慢?因为他要访问磁盘。
↓
也就是说当PC累加到I/O指令时,(如果此时不加任何干预)CPU一会工作,一会又停止,利用率大幅下降。(I/O指令越多,CPU利用率越低)
↓
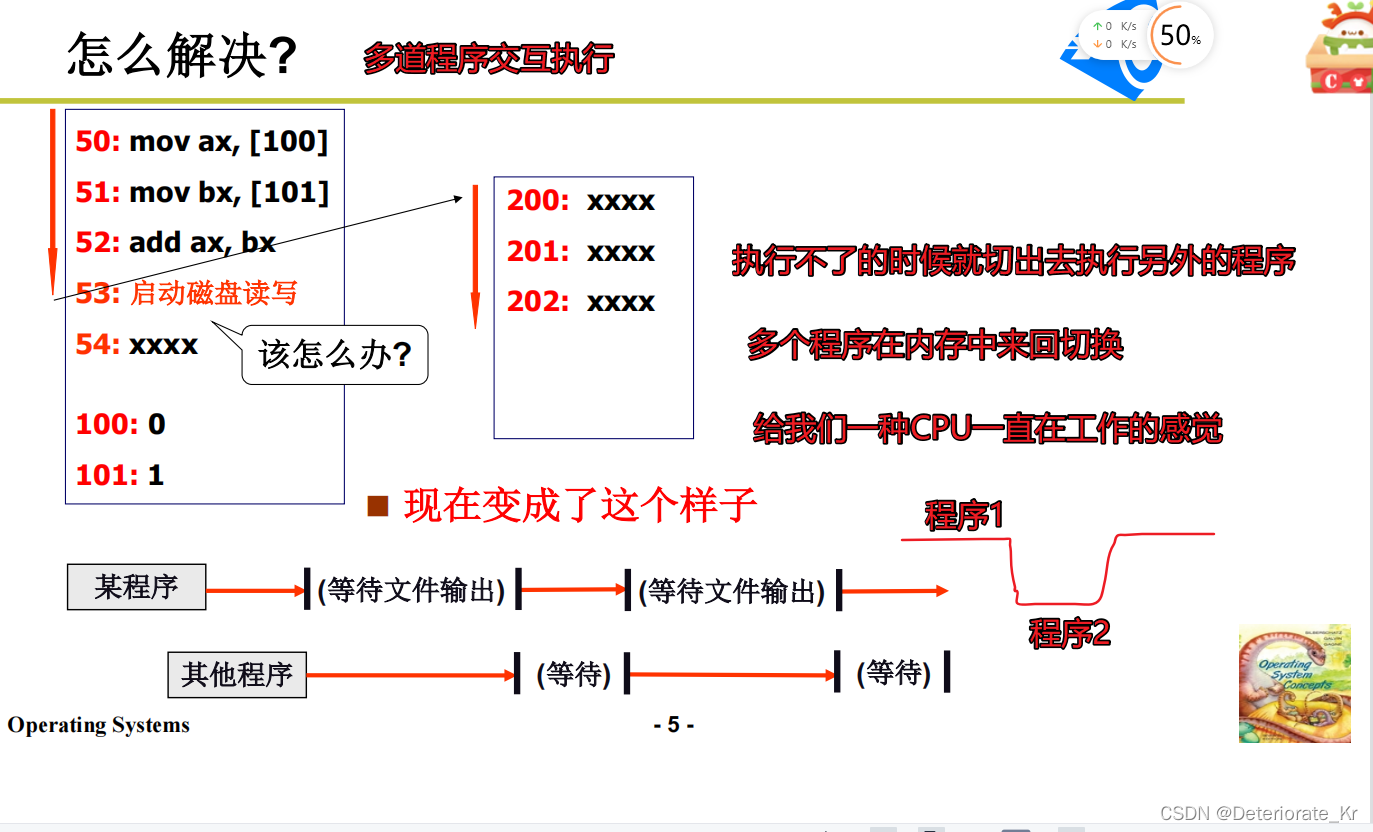
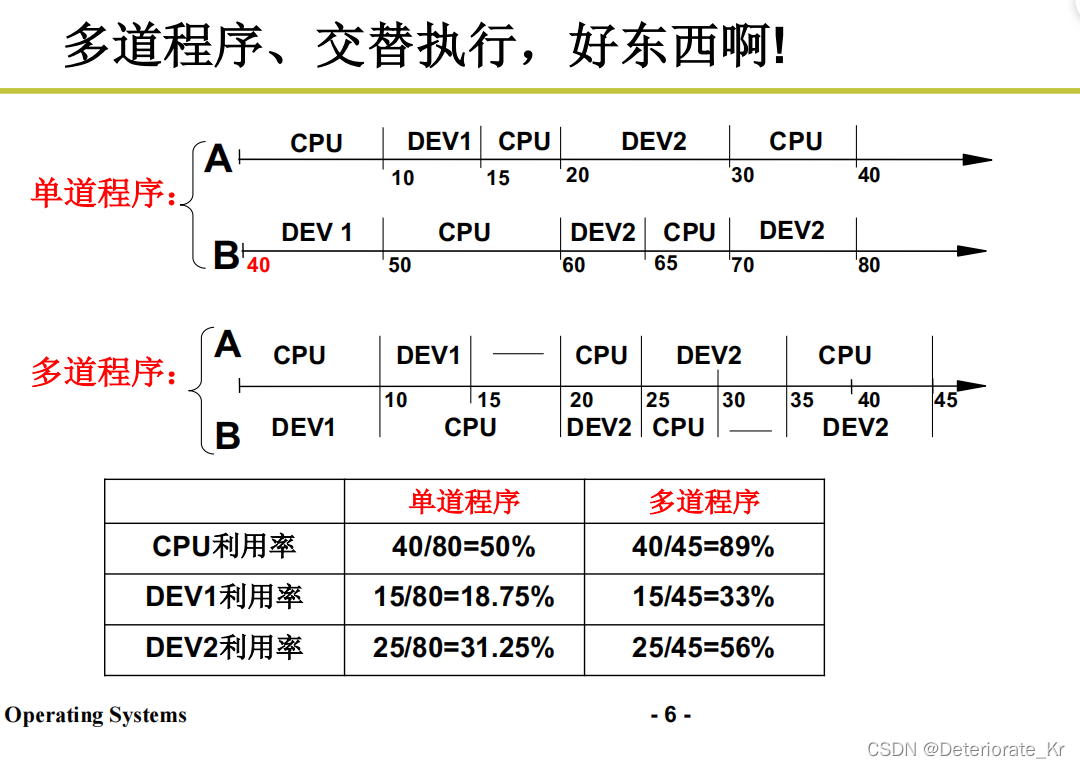
多道程序交互执行就是管理CPU的核心

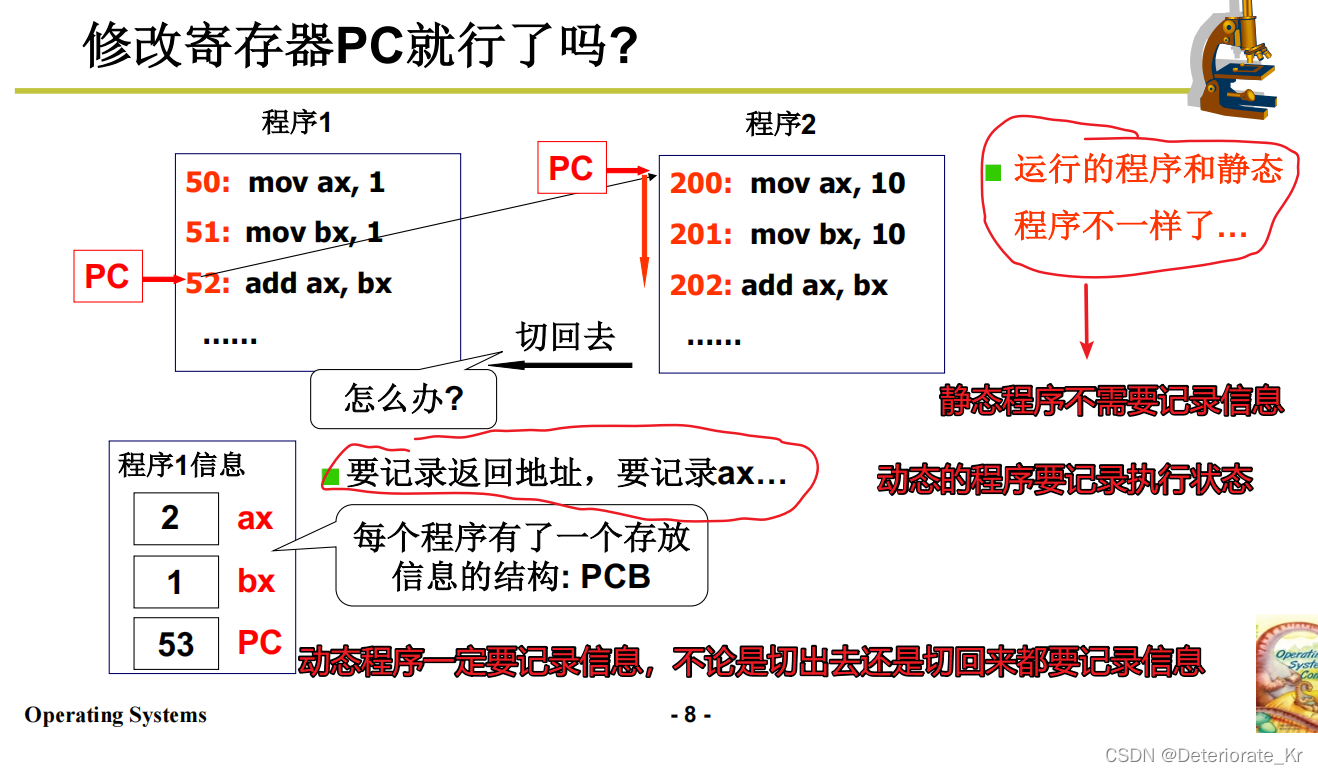
所以,仅仅修改寄存器PC还不行,我们还要记录信息,你切出去的时候是个什么样子,切回来的时候当然不会变
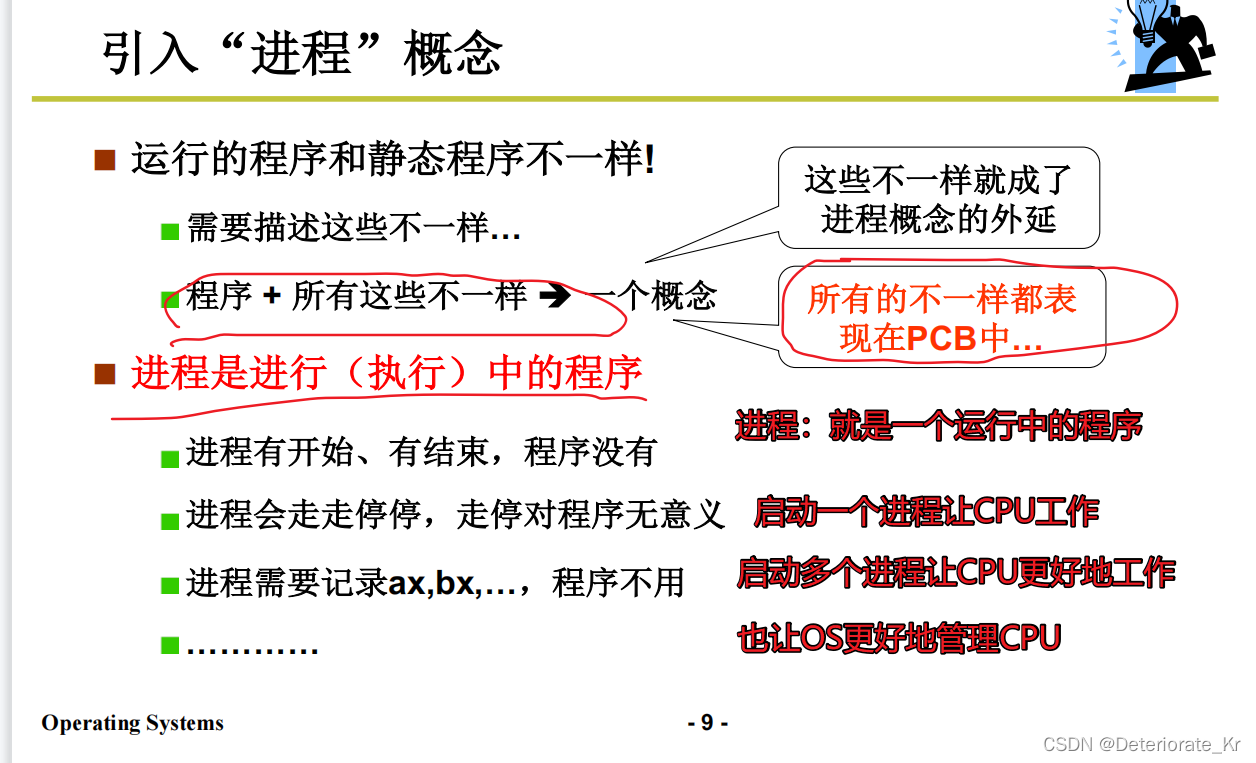
引入多进程图像
多进程图像,多个进程使用CPU的图像,也是操作系统的核心图像
PCB:进程控制块(它是一个结构体)
TCB:线程控制块(它也是一个结构体)
我们用户只关心如何使用多进程,而OS负责管理这些多进程

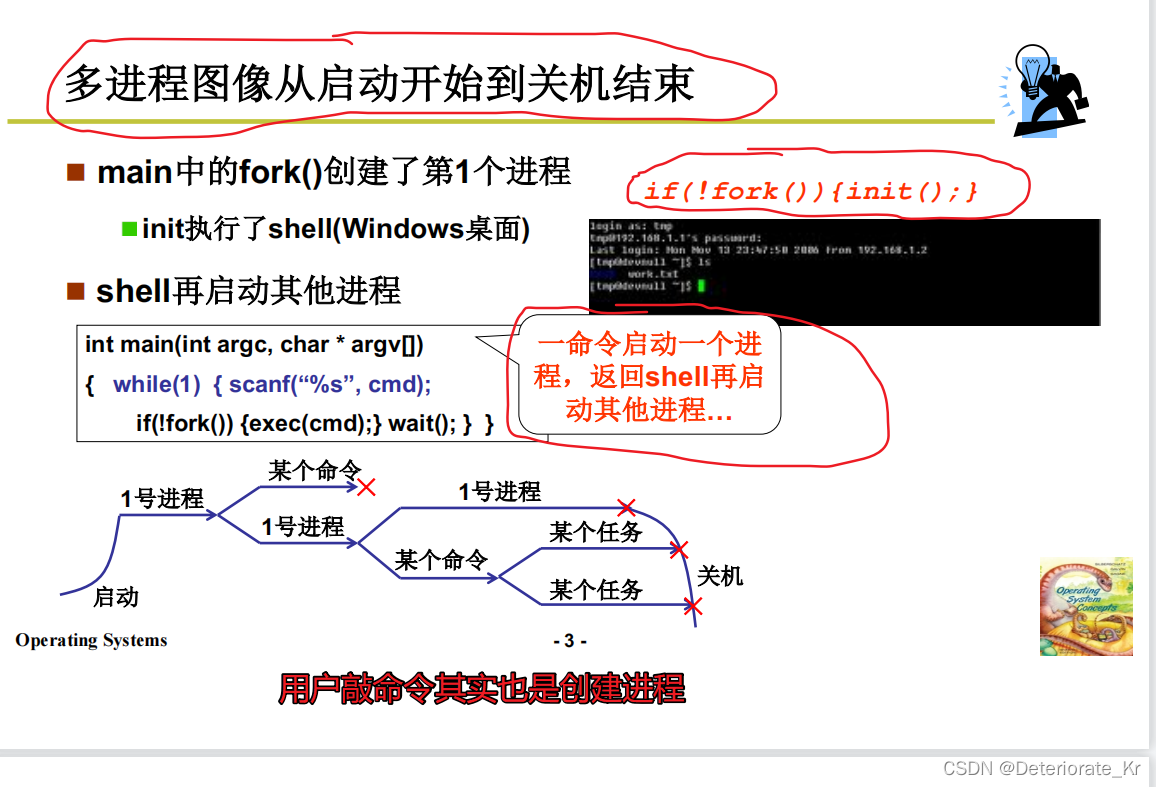
1.多进程如何组织呢?怎么推进多进程?一句话:就是把多个进程所对应的PCB所放在不同的地方,而且操作系统都知道
1.为什么要组织多个进程?因为操作系统只有组织好多个进程,才能够合理地推进多个进程,每个进程执行的先后顺序肯定不一样,完成的任务也不一样,事情的轻重缓急也不一样
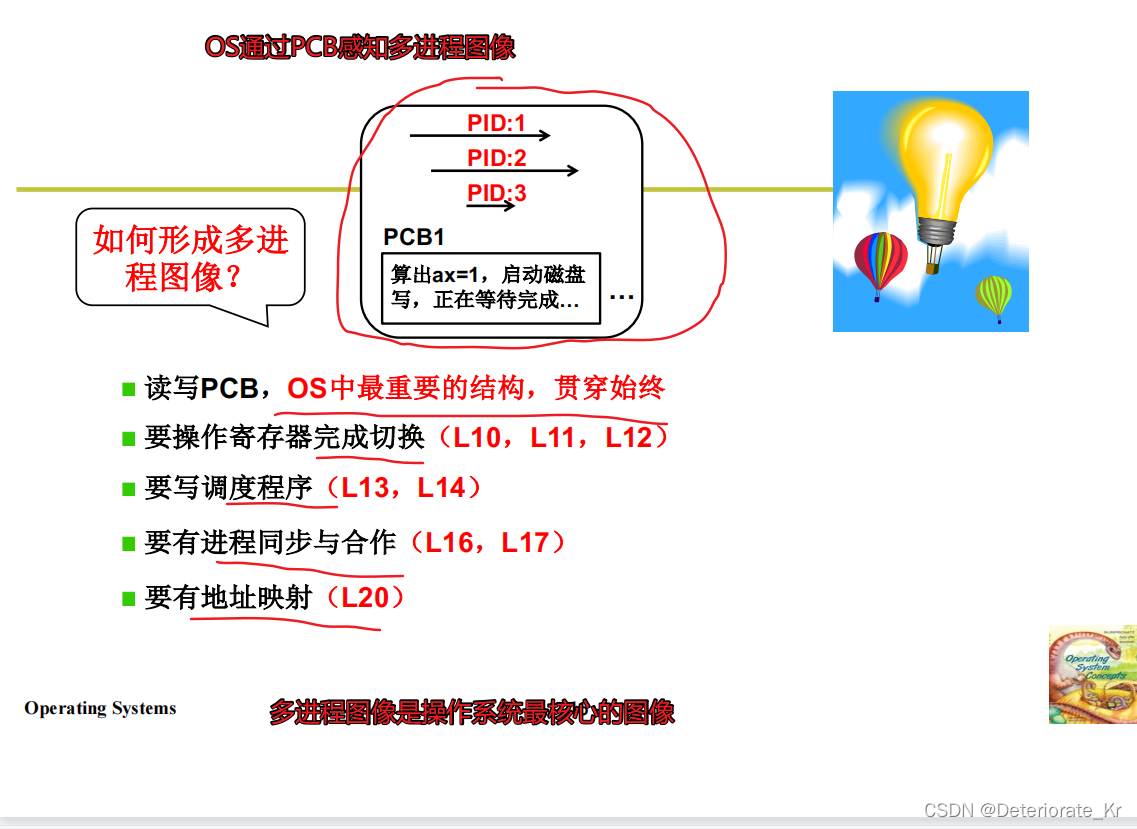
2.操作系统感知进程全靠PCB,操作系统组织进程当然也是靠PCB,用PCB形成一些数据结构(比如队列)来组织
3.每个进程都有对应的一个PCB,它是用来记录进程信息的一个数据结构
4.既然执行的顺序不一样,那我们就在PCB之上形成不同的队列,把每个进程对应的PCB放在队列的不同的地方(当然操作系统肯定知道这个PCB放在哪里)不就完事了
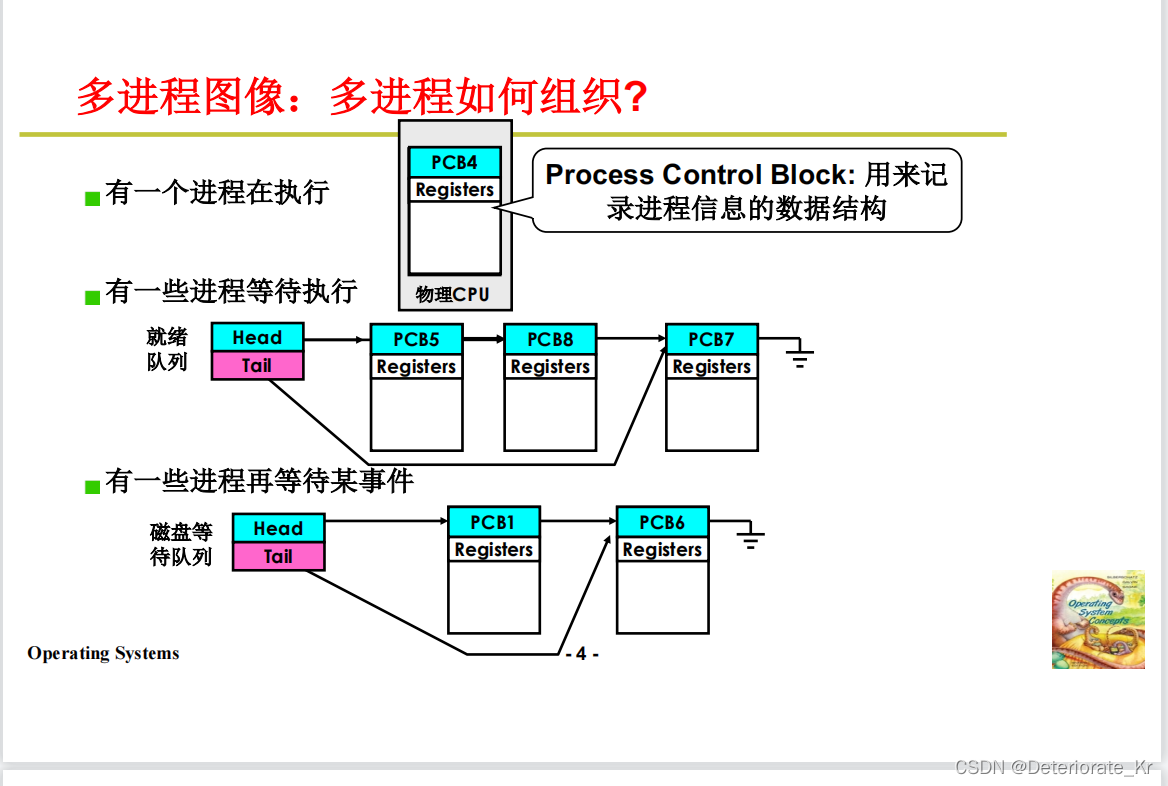
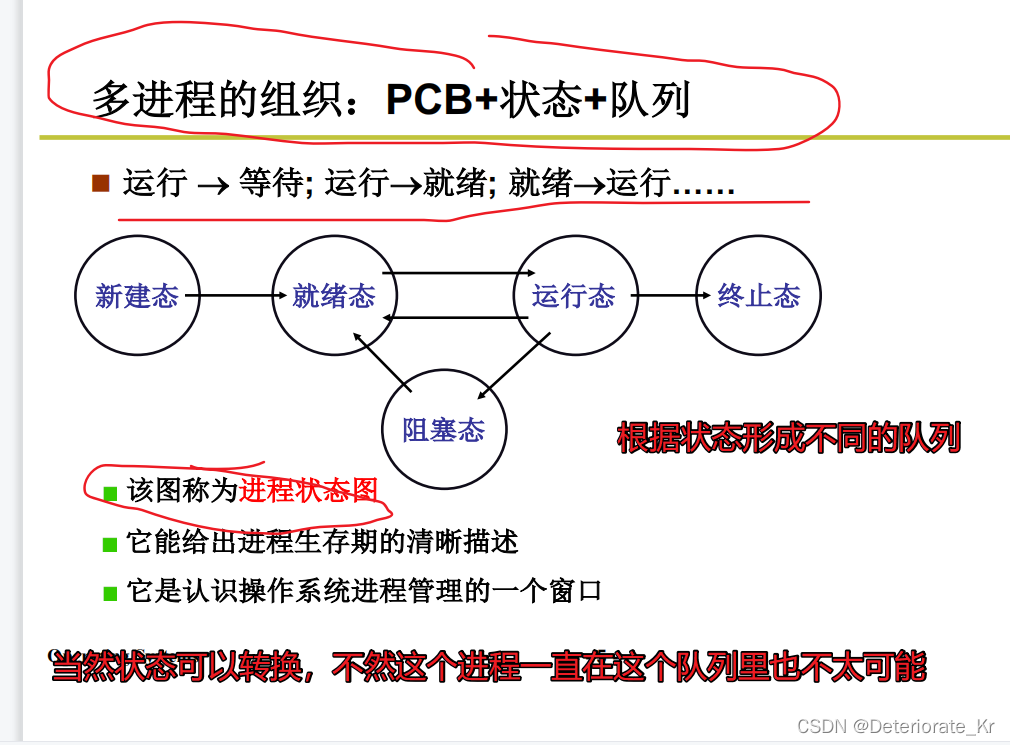
总结:把PCB放在不同的队列中,用状态来推进多个进程(根据状态形成不同的队列,把PCB放在不同的位置里)
2.多进程如何交替执行呢?这是多进程图像的核心

启动磁盘读写; / /此时必须等待
pCur.state = ‘W’;/ / 把自己状态变为阻塞态
将pCur放到DiskWaitQueue;/ /放在等待队列上
schedule();/ / 切换,这是重中之重,会无数次的讲到这个函数
schedule()
{
pNew = getNext(ReadyQueue);/ /调度函数(到底选哪一个进程切换)
/ / 这里是在就绪队列中得到下一个进程的PCB
/ / 选好后,根据PCB的信息,切换和恢复
switch_to(pCur,pNew);/ / 这就是真正的切换了
/ / pCur:当前进程的PCB
/ / PNew:切换后进程的PCB
}
也就是这几步:保存当前现场、切换到下一现场、再恢复当前现场

switch_to(pCur,pNew) {
pCur.ax = CPU.ax;
pCur.bx = CPU.bx;
...
pCur.cs = CPU.cs;
pCur.retpc = CPU.pc;
/ /上面就是把(当前态的)CPU中数据保存到PCB1
CPU.ax = pNew.ax;
CPU.bx = pNew.bx;
...
CPU.cs = pNew.cs;
CPU.retpc = pNew.pc;
/ / 再把执行态加载到CPU}
①:先将CPU中数据(也就是当前态中寄存器的数据)保存到PCB1
②再将执行态的数据扣到CPU里面
③:这里面必须要精细的控制(规定CPU中的寄存器具体放在哪里),所以需要汇编代码
3.多个进程交替执行的时候还有没有别的事情要做?多进程交替执行的时候还会交替影响

可以看到,进程1和进程2都在内存中。进程1访问的地址100很有可能是进程2的地址100,那么这就会把进程2里的数据给修改,这是不被允许的。
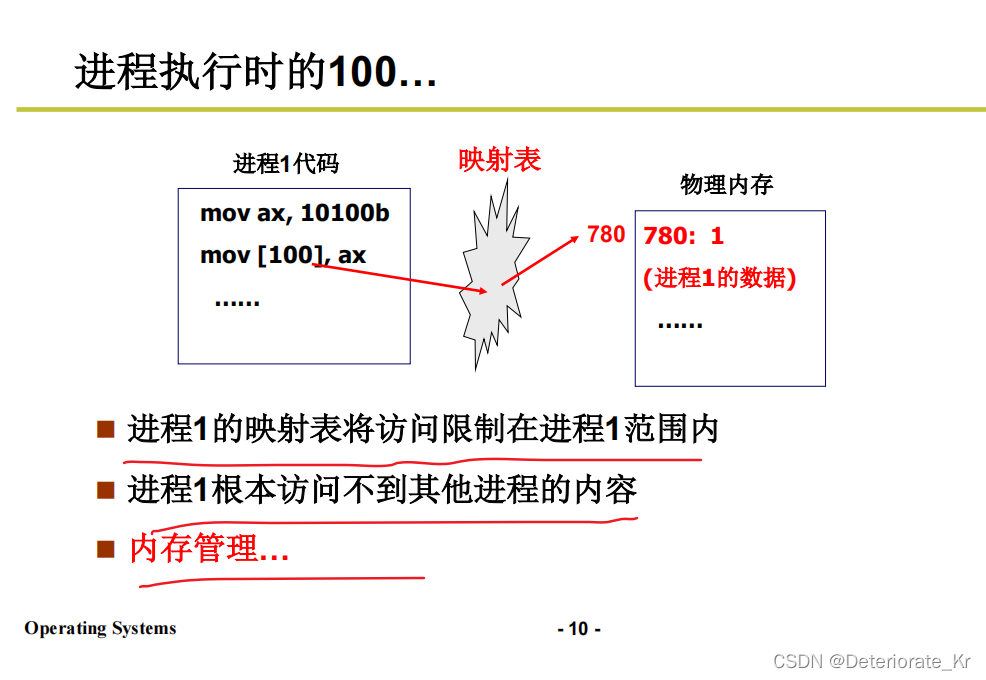
实际上,进程1中的100不是真实的地址,而是每个进程都有自己对应的映射表,他会映射到真实地址
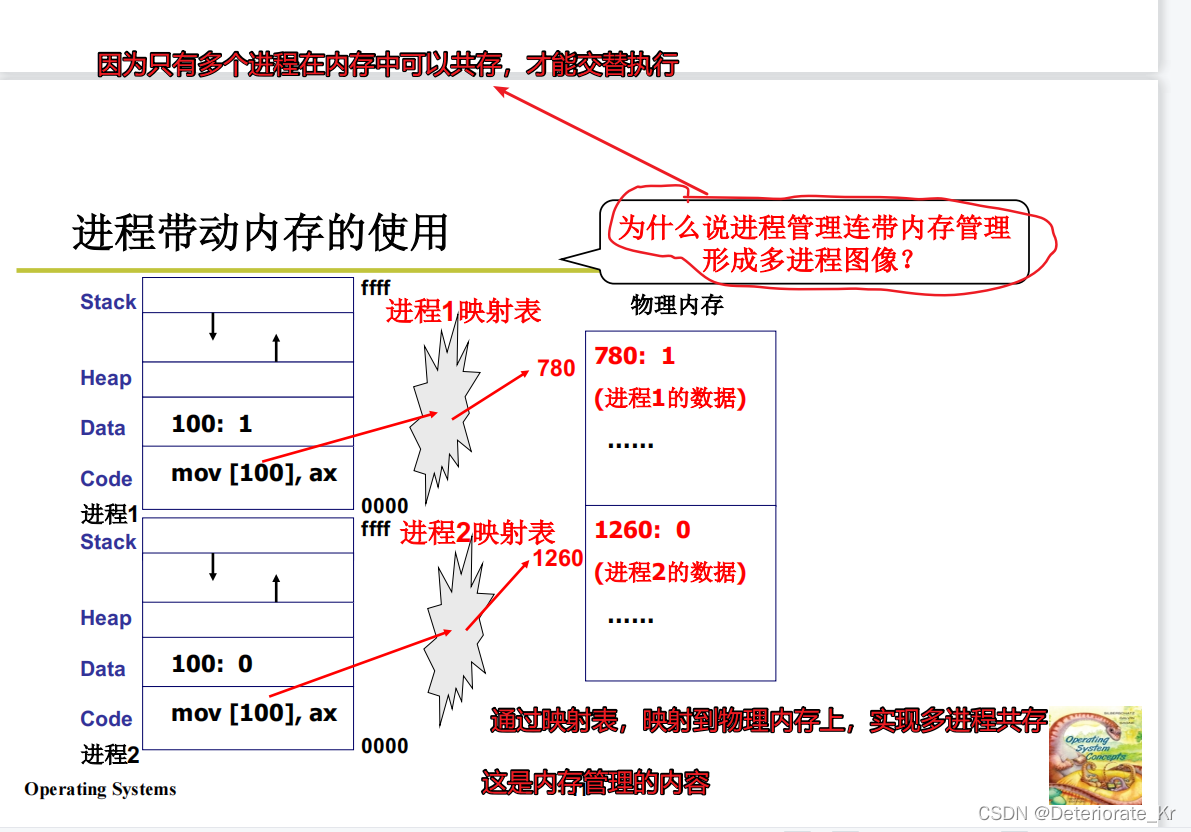
4.多进程如何合作呢?
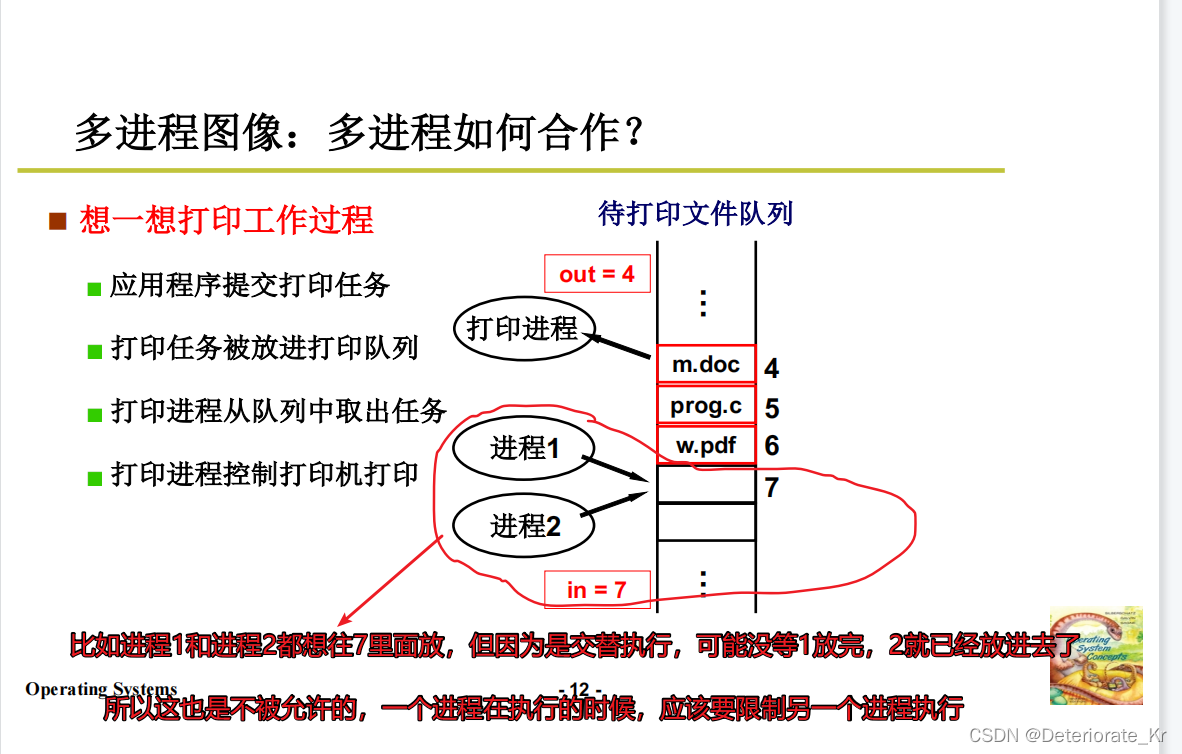
来看一下经典的生产者消费者问题
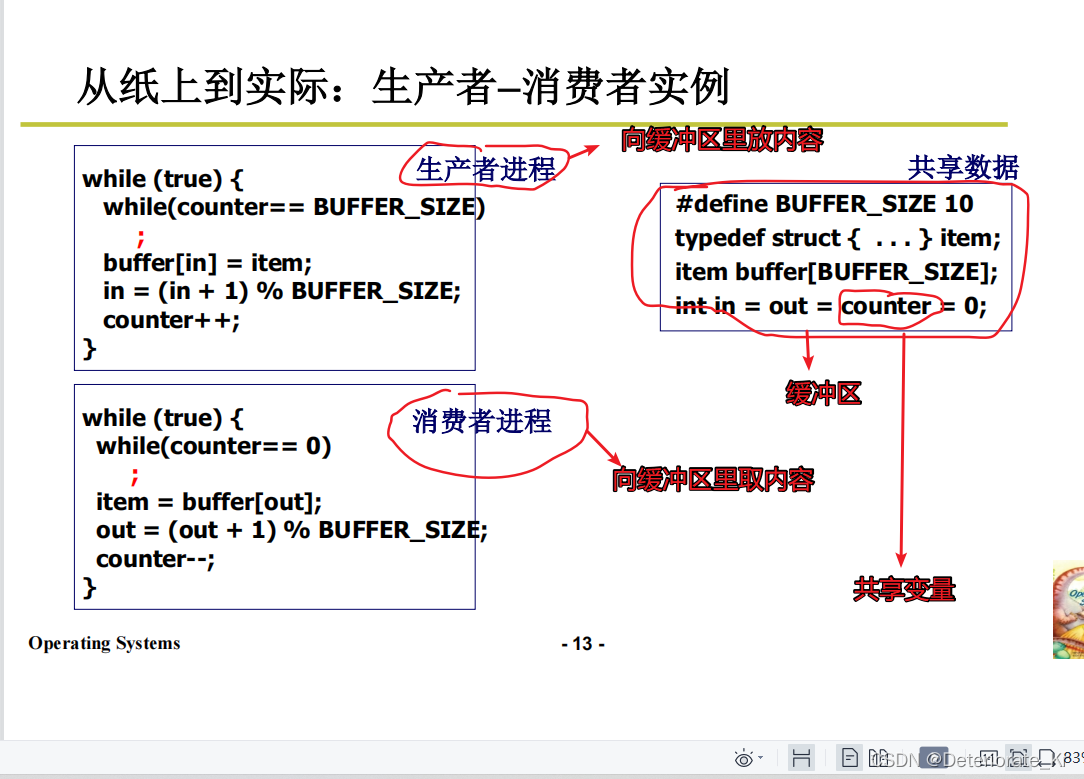
我们一定要保证这个counter能准确表达此时的情况,也就是它的值必须是对的

此时counter变成4,含义是不对的。
counter初始为5,加了一个数又减了一个数,还应该是5

总结
多进程图像是操作系统最核心的图像















 1565
1565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









