






 文章介绍了LeNet和AlexNet两种经典的卷积神经网络结构,包括它们在网络层次、卷积窗口大小、激活函数和防止过拟合策略上的差异。LeNet适合较小规模的数据集,而AlexNet因其更深的网络层次和更大的模型参数,在处理大规模图像识别任务如ImageNet上表现出色。AlexNet还引入了ReLU激活函数和丢弃法,提高了模型训练的效率和性能。
文章介绍了LeNet和AlexNet两种经典的卷积神经网络结构,包括它们在网络层次、卷积窗口大小、激活函数和防止过拟合策略上的差异。LeNet适合较小规模的数据集,而AlexNet因其更深的网络层次和更大的模型参数,在处理大规模图像识别任务如ImageNet上表现出色。AlexNet还引入了ReLU激活函数和丢弃法,提高了模型训练的效率和性能。
LeNet网络的名字来源于LeNet论文的第一作者Yann LeCun。
LeNet网络结构如下
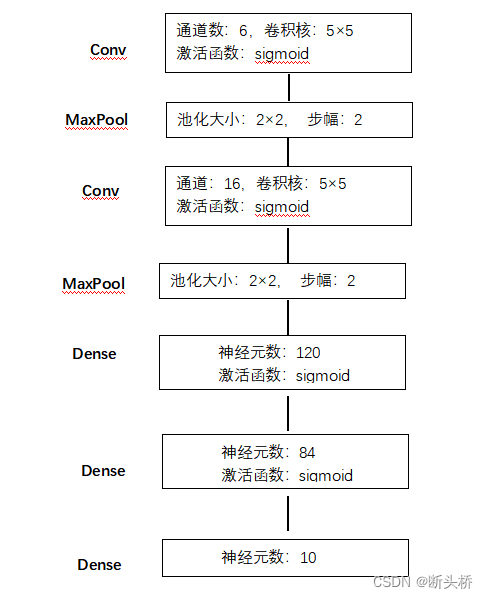
mxnet创建LeNet网络代码如下
import d2lzh as d2l
import mxnet as mx
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn
import time
net = nn.Sequential()
net.add(nn.Conv2D(channels=6, kernel_size=5),
nn.Activation('sigmoid'),
nn.MaxPool2D(pool_size=2, strides=2),
nn.Conv2D(channels=16, kernel_size=5),
nn.Activation('sigmoid'),
nn.MaxPool2D(pool_size=2, strides=2),
# Dense会默认将(批量大小, 通道, 高, 宽)形状的输入转换成
# (批量大小, 通道 * 高 * 宽)形状的输入
nn.Dense(120, activation='sigmoid'),
nn.Dense(84, activation='sigmoid'),
nn.Dense(10))AlexNet来源于论文-ImageNet Classification with Deep Convolutional Neural Networks
的第一作者Alex Krizhevsky。
AlexNet的网络结构如下
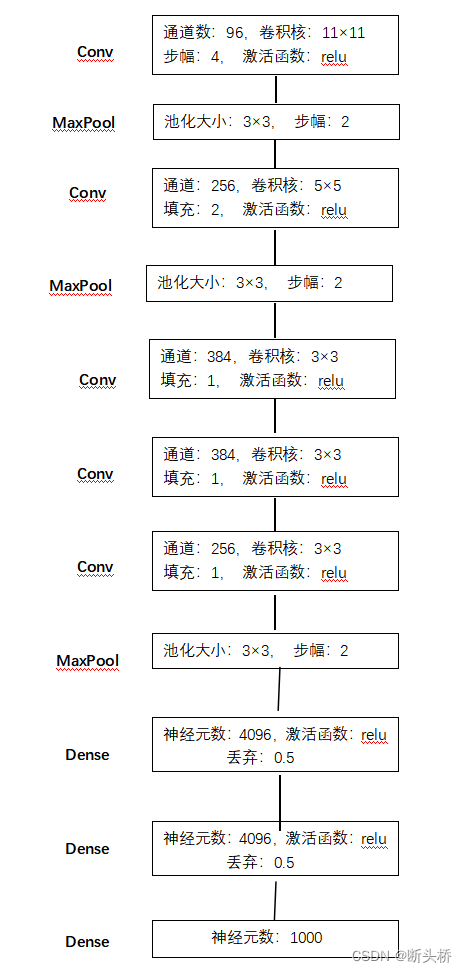
mxnet创建AlexNet网络代码如下
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import data as gdata, nn
import os
import sys
net = nn.Sequential()
# 使用较大的11 x 11窗口来捕获物体。同时使用步幅4来较大幅度减小输出高和宽。这里使用的输出通
# 道数比LeNet中的也要大很多
net.add(nn.Conv2D(96, kernel_size=11, strides=4, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2D(256, kernel_size=5, padding=2, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'),
nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'),
nn.Conv2D(256, kernel_size=3, padding=1, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
nn.Dense(4096, activation="relu"), nn.Dropout(0.5),
nn.Dense(4096, activation="relu"), nn.Dropout(0.5),
nn.Dense(1000))AlexNet与LeNet的设计理念非常相似,但也有显著的区别。
第一,与相对较小的LeNet相比,AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。下面我们来详细描述这些层的设计。
AlexNet第一层中的卷积窗口形状是11×11。因为ImageNet中绝大多数图像的高和宽均比MNIST图像的高和宽大10倍以上,ImageNet图像的物体占用更多的像素,所以需要更大的卷积窗口来捕获物体。第二层中的卷积窗口形状减小到5×5,之后全采用3×3。此外,第一、第二和第五个卷积层之后都使用了窗口形状为3×3、步幅为2的最大池化层。而且,AlexNet使用的卷积通道数也大于LeNet中的卷积通道数数十倍。
紧接着最后一个卷积层的是两个输出个数为4096的全连接层。这两个巨大的全连接层带来将近1 GB的模型参数。由于早期显存的限制,最早的AlexNet使用双数据流的设计使一个GPU只需要处理一半模型。幸运的是,显存在过去几年得到了长足的发展,因此通常我们不再需要这样的特别设计了。
第二,AlexNet将sigmoid激活函数改成了更加简单的ReLU激活函数。一方面,ReLU激活函数的计算更简单,例如它并没有sigmoid激活函数中的求幂运算。另一方面,ReLU激活函数在不同的参数初始化方法下使模型更容易训练。这是由于当sigmoid激活函数输出极接近0或1时,这些区域的梯度几乎为0,从而造成反向传播无法继续更新部分模型参数;而ReLU激活函数在正区间的梯度恒为1。因此,若模型参数初始化不当,sigmoid函数可能在正区间得到几乎为0的梯度,从而令模型无法得到有效训练。
第三,AlexNet通过丢弃法来控制全连接层的模型复杂度。而LeNet并没有使用丢弃法。
第四,AlexNet引入了大量的图像增广,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。


















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











