







题目如下:
(力扣题)https://leetcode.cn/problems/remove-duplicate-node-lcci/
移除未排序链表中的重复节点,保留最开始出现的节点
思路:
使用HashSet——>HashSet保证数据不重复
(1)先判断头节点是否为空,若为空则证明链表不存在;不为空则继续执行下面的代码;
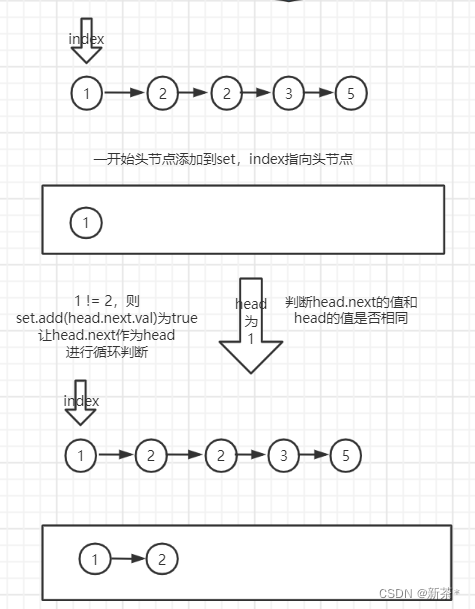
(2)定义一个指针指向头节点,定义一个Hash Set;先将头节点值放入set
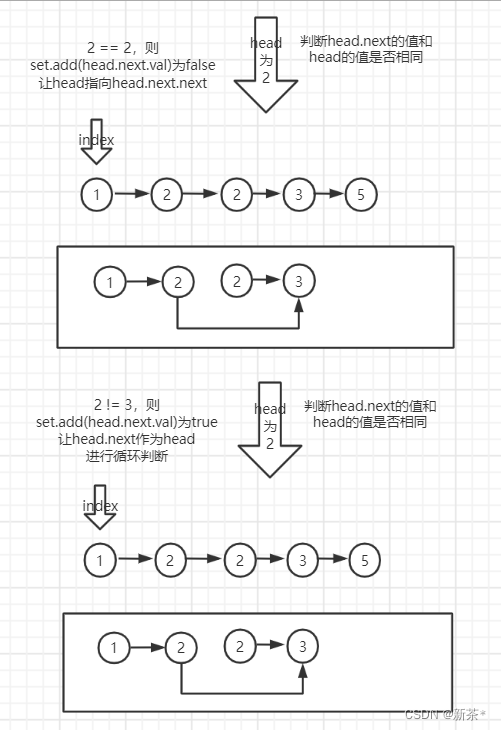
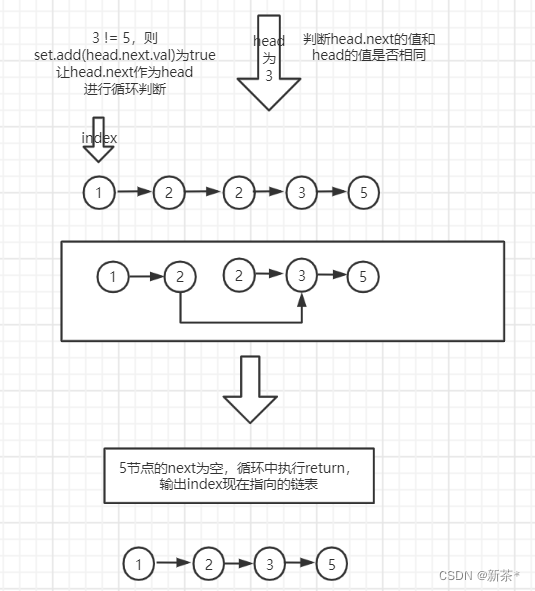
(3)使用set.add(head.next.val)判断head的下一个节点和head的值是否相同;
(4)相同就舍弃head.next这个节点,不同就保留head.next这个节点
(5)循环判断head和head.next的值
(6)最后输出去重后的链表
思路图示:
代码如下:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;//节点值
* ListNode next;
* ListNode(int x) { val = x; }//节点记录的下一个节点的地址
* }
*/
class Solution {
public ListNode removeDuplicateNodes(ListNode head) {
if (head == null) {
return head;//链表为空的时候,执行return
}
ListNode index=head;//index指向head
HashSet<Object> set = new HashSet<>();
set.add(head.val);//head值添加到HashSet中
while (head.next!=null){//当节点的下一个节点不为空
//递归下一个节点,放入set
if (set.add(head.next.val)){//set.add()为true执行下面的代码,set.add为true即节点的下一个节点值不重复
head=head.next;//让节点变成指向下一个节点,保证链表不重复
}else {//节点值重复后,让节点指向节点的next.next,相当于放弃 节点.next 这个节点
head.next=head.next.next;
};
}
head.next=null;
return index;
}
}














 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









